This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction to DataWarehouse SQL DataWarehouse is also a cloud-based datawarehouse that uses Massively Parallel Processing (MPP) to run complex queries across petabytes of data rapidly. Import big […].
Introduction We are all pretty much familiar with the common modern cloud datawarehouse model, which essentially provides a platform comprising a data lake (based on a cloud storage account such as AzureData Lake Storage Gen2) AND a datawarehouse compute engine […].
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
This is where data warehousing is a critical component of any business, allowing companies to store and manage vast amounts of data. It provides the necessary foundation for businesses to […] The post Understanding the Basics of DataWarehouse and its Structure appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. DataEngineers, I am sure this simple article will help you guys better understand Cosmos DB from Azure with nice features. Recently many customers have been looking forward to implementing the Data Migration into Cosmos DB.
Introduction Azuredata factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Why We Built Databricks One At Databricks, our mission is to democratize data and AI. For years, we’ve focused on helping technical teams—dataengineers, scientists, and analysts—build pipelines, develop advanced models, and deliver insights at scale.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to datawarehouse through to frontend.
Data Lakehouse has emerged as a significant innovation in data management architecture, bridging the advantages of both data lakes and datawarehouses. By enabling organizations to efficiently store various data types and perform analytics, it addresses many challenges faced in traditional data ecosystems.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. OneLake, being built on AzureData Lake Storage (ADLS), supports various data formats, including Delta, Parquet, CSV, and JSON. On the home page, select Synapse DataEngineering.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Introduction Delta Lake is an open-source storage layer that brings data lakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
Accordingly, one of the most demanding roles is that of AzureDataEngineer Jobs that you might be interested in. The following blog will help you know about the AzureDataEngineering Job Description, salary, and certification course. How to Become an AzureDataEngineer?
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
By automating the integration of all Fabric workloads into OneLake, Microsoft eliminates the need for developers, analysts, and business users to create their own data silos. This approach not only improves performance by eliminating the need for separate datawarehouses but also results in substantial cost savings for customers.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
One of them is Azure functions. In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. A batch ETL works under a predefined schedule in which the data are processed at specific points in time.
Summary: This blog provides a comprehensive roadmap for aspiring AzureData Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform. One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery).
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
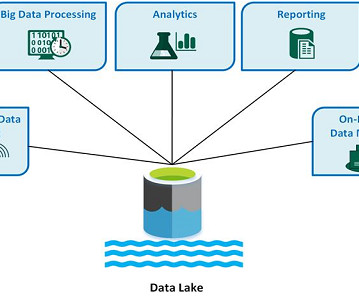
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a data lake? So let’s take a look at a few of the leading industry examples of data lakes. Where does it go?
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Below are the best practices.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses. Cost : Is the pricing predictable and within budget?
Introduction A data lake is a centralized and scalable repository storing structured and unstructured data. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Thankfully, there are tools available to help with metadata management, such as AWS Glue, AzureData Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
There you’ll hear from Ivan Nardini, Developer Relations Engineer at Google Cloud and discover the latest advancements in AI and learn how to leverage Google Cloud’s powerful tools and infrastructure to drive innovation in your organization.
Matillion is also built for scalability and future data demands, with support for cloud data platforms such as Snowflake Data Cloud , Databricks, Amazon Redshift, Microsoft Azure Synapse, and Google BigQuery, making it future-ready, everyone-ready, and AI-ready. That process will not take longer than 3 minutes!
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
Typically, this data is scattered across Excel files on business users’ desktops. Cloud Storage Upload Snowflake can easily upload files from cloud storage (AWS S3, Azure Storage, GCP Cloud Storage). Hosting the data in Snowflake’s hybrid tables may be a better choice for these applications.
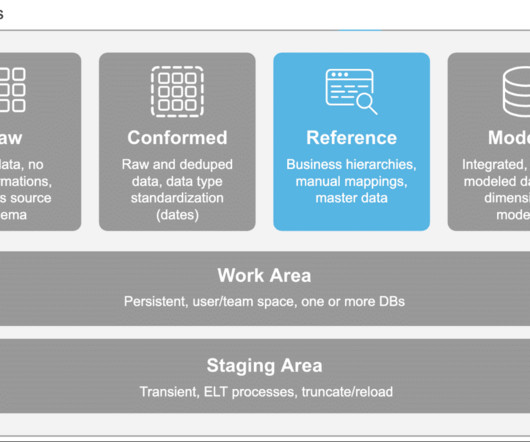
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. It comprises three main areas: Landing area, Staging area, and DataWarehouse area.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content