This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
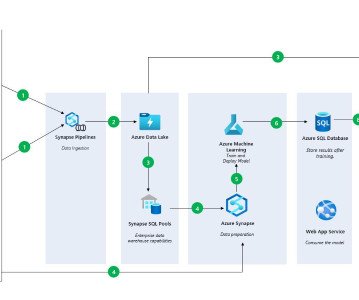
This article was published as a part of the Data Science Blogathon. Introduction to Data Warehouse SQLData Warehouse is also a cloud-based data warehouse that uses Massively Parallel Processing (MPP) to run complex queries across petabytes of data rapidly. Import big […].
Introduction Azure Functions is a serverless computing service provided by Azure that provides users a platform to write code without having to provision or manage infrastructure in response to a variety of events. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
AI Functions in SQL: Now Faster and Multi-Modal AI Functions enable users to easily access the power of generative AI directly from within SQL. AI Functions are now up to 3x faster and 4x lower cost than other vendors on large-scale workloads, enabling you to process large-scale data transformations with unprecedented speed.
Introduction Azuredata factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Introduction Microsoft Azure Synapse Analytics is a robust cloud-based analytics solution offered as part of the Azure platform. It is intended to assist organizations in simplifying the big data and analytics process by providing a consistent experience for data preparation, administration, and discovery.
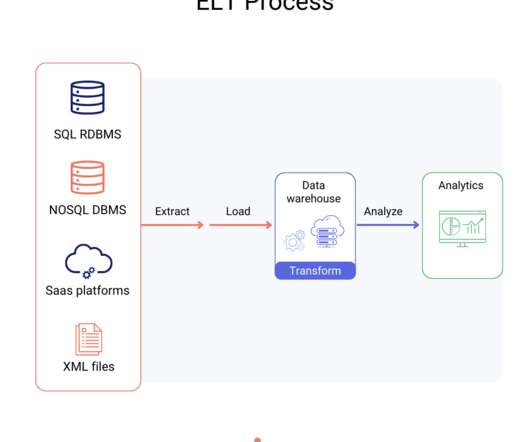
Data Science Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. Click on the button below to head over to the Azure Marketplace and deploy Airbyte for FREE by clicking below:
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. Data Lakes : It supports MS Azure Blob Storage. pipelines, AzureData Bricks.
Why We Built Databricks One At Databricks, our mission is to democratize data and AI. For years, we’ve focused on helping technical teams—dataengineers, scientists, and analysts—build pipelines, develop advanced models, and deliver insights at scale.
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. The following Terraform script will create an Azure Resource Group, a SQL Server, and a SQL Database.
They work closely with database administrators to ensure data integrity, develop reporting tools, and conduct thorough analyses to inform business strategies. Their role is crucial in understanding the underlying data structures and how to leverage them for insights. This role builds a foundation for specialization.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
DATANOMIQ Jobskills Webapp The whole web app is hosted and deployed on the Microsoft Azure Cloud via CI/CD and Infrastructure as Code (IaC). However, we collect these over time and will make trends secure, for example how the demand for Python, SQL or specific tools such as dbt or Power BI changes. Why we did it?
Accordingly, one of the most demanding roles is that of AzureDataEngineer Jobs that you might be interested in. The following blog will help you know about the AzureDataEngineering Job Description, salary, and certification course. How to Become an AzureDataEngineer?
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. OneLake, being built on AzureData Lake Storage (ADLS), supports various data formats, including Delta, Parquet, CSV, and JSON. On the home page, select Synapse DataEngineering.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
Historical context To appreciate the innovation of the data lakehouse, it’s useful to understand the evolution of its predecessors: data warehouses and data lakes. Multilayered architecture: Bronze, Silver, and Gold layers streamline data processing.
Building Enterprise-Grade Q&A Chatbots with Azure OpenAI: In this tutorial, we explore the features of Azure OpenAI and demonstrate how to further improve the platform by fine-tuning some of its models. Getting Started with SQL Programming: Are you starting your journey in data science?
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
In the Indian context, data scientists often work in dynamic environments such as IT services, fintech, e-commerce, healthcare, and telecom sectors. They are expected to be versatile, handling everything from dataengineering and exploratory analysis to deploying machine learning models and communicating insights to business stakeholders.
This explains the current surge in demand for dataengineers, especially in data-driven companies. That said, if you are determined to be a dataengineer , getting to know about big data and careers in big data comes in handy. Similarly, various tools used in dataengineering revolve around Scala.
Simple Data Model for a Process Mining Event Log As part of dataengineering, the data traces that indicate process activities are brought into a log-like schema. DATANOMIQ Data Mesh Cloud Architecture – This image is animated! Central data models in a cloud-based Data Mesh Architecture (e.g.
Azure Cognitive Services Named Entity Recognition gets some new types Persontype, product, event, organization, date are just some of them Amazon Aurora PostgreSQL Supports Machine Learning Aurora PostgreSQL can now use SQL to call ML models created with SageMaker. Google Announces BigQuery Data Challenge. Training and Courses.
The examples are production-ready and provide an actionable reference for developers and ML engineers alike. Applied Data Mesh Workshop for Scalable Data Platforms Jay Sen, Director, DataEngineering, PayPal Sen led a highly practical walkthrough on implementing data mesh principles using modern tooling.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. This streamlined approach eliminates the need for separate solutions and simplifies data management. Of course not!
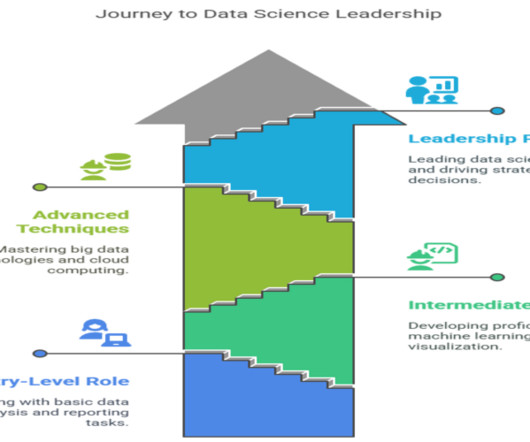
Summary: This blog provides a comprehensive roadmap for aspiring AzureData Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
In this blog, we’re going to try our best to remove as much of the uncertainty as possible by walking through the interview process here at phData for DataEngineers. Whether you’re officially job hunting or just curious about what it’s like to interview and work at phData as a DataEngineer, this is the blog for you!
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL are expected, you’ll need to go beyond that. Big Data As datasets become larger and more complex, knowing how to work with them will be key.
Using Azure ML to Train a Serengeti Data Model, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti Data Model for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Descriptive analytics is a fundamental method that summarizes past data using tools like Excel or SQL to generate reports. Techniques such as data cleansing, aggregation, and trend analysis play a critical role in ensuring data quality and relevance. Data Scientists rely on technical proficiency.
The Biggest Data Science Blogathon is now live! Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon. Knowledge is power. Sharing knowledge is the key to unlocking that power.”―
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. The first insert statement loads data having c_custkey between 30001 and 40000 – INSERT INTO ib_customers2 SELECT *, '11111111111111' AS HASHKEY FROM snowflake_sample_data.tpch_sf1.customer
One big issue that contributes to this resistance is that although Snowflake is a great cloud data warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform.
Hey, are you the data science geek who spends hours coding, learning a new language, or just exploring new avenues of data science? The post Data Science Blogathon 28th Edition appeared first on Analytics Vidhya. If all of these describe you, then this Blogathon announcement is for you!
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. DataEngineering Platforms Spark is still the leader for data pipelines but other platforms are gaining ground. Knowing some SQL is also essential.
AI and Big Data Expo – North America (May 17-18, 2023): This technology event is for enterprise technology professionals interested in the latest AI and big data advances and tactics. Representatives from Google AI, Amazon Web Services, Microsoft Azure, and other top firms attended the event as main speakers.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































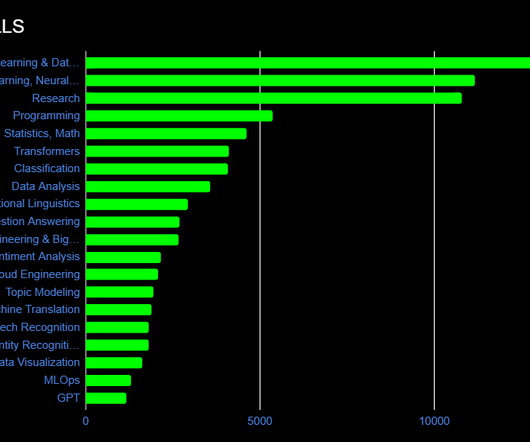







Let's personalize your content