This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction We are all pretty much familiar with the common modern cloud data warehouse model, which essentially provides a platform comprising a datalake (based on a cloud storage account such as AzureDataLake Storage Gen2) AND a data warehouse compute engine […].
Introduction Delta Lake is an open-source storage layer that brings datalakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
Separation of storage and compute : Lakebases store their data in modern datalakes (object stores) in open formats, which enables scaling compute and storage separately, leading to lower TCO and eliminating lock-in. At zero, the cost of the lakebase is just the cost of storing the data on cheap datalakes.
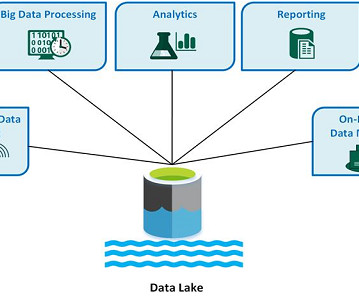
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
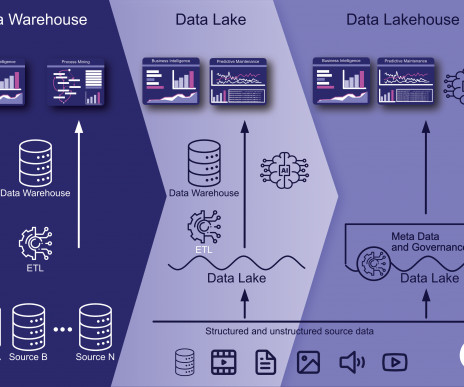
Data Lakehouse has emerged as a significant innovation in data management architecture, bridging the advantages of both datalakes and data warehouses. By enabling organizations to efficiently store various data types and perform analytics, it addresses many challenges faced in traditional data ecosystems.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
Introduction Microsoft Azure HDInsight(or Microsoft HDFS) is a cloud-based Hadoop Distributed File System version. A distributed file system runs on commodity hardware and manages massive data collections. It is a fully managed cloud-based environment for analyzing and processing enormous volumes of data.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. On the home page, select Synapse DataEngineering.
Accordingly, one of the most demanding roles is that of AzureDataEngineer Jobs that you might be interested in. The following blog will help you know about the AzureDataEngineering Job Description, salary, and certification course. How to Become an AzureDataEngineer?
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. It can also be integrated into major data platforms like Snowflake.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
One of them is Azure functions. In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. A batch ETL works under a predefined schedule in which the data are processed at specific points in time.
Summary: This blog provides a comprehensive roadmap for aspiring AzureData Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
5 DataEngineering and Data Science Cloud Options for 2023 AI development is incredibly resource intensive. As such, here are a few data science cloud options to help you handle some work virtually. Here are a few things to keep an eye out for. Learn more about how you can speak and present at ODSC West here!
Using Azure ML to Train a Serengeti Data Model, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti Data Model for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
Big data isn’t an abstract concept anymore, as so much data comes from social media, healthcare data, and customer records, so knowing how to parse all of that is needed. This pushes into big data as well, as many companies now have significant amounts of data and large datalakes that need analyzing.
Enterprise data architects, dataengineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface. free trial.
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. Given the range of tools and data types, a separate data versioning logic will be necessary.
If using a network policy with Snowflake, be sure to add Fivetran’s IP address list , which will ensure AzureData Factory (ADF) AzureData Factory is a fully managed, serverless data integration service built by Microsoft. Fivetran works with all three Snowflake cloud providers.
Data analysts often must go out and find their data, process it, clean it, and get it ready for analysis. This pushes into Big Data as well, as many companies now have significant amounts of data and large datalakes that need analyzing. Cloud Services: Google Cloud Platform, AWS, Azure.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. This provides end-to-end support for dataengineering and MLOps workflows.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
At the AI Expo and Demo Hall as part of ODSC West in a few weeks, you’ll have the opportunity to meet one-on-one with representatives from industry-leading organizations like Microsoft Azure, Hewlett Packard, Iguazio, neo4j, Tangent Works, Qwak, Cloudera, and others.
Building Scalable AI Pipelines with MLOps: A Guide for Software Engineers Let’s explore using MLOps for software engineers, such as how they can address common issues, enabling scalable and efficient AI development pipelines. Industry, Opinion, Career Advice AI for Robotics and Autonomy with Francis X.
The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. Simplify and Win Experienced dataengineers value simplicity. What does Snowflake do?
This includes operations like data validation, data cleansing, data aggregation, and data normalization. The goal is to ensure that the data is consistent and ready for analysis. Loading : Storing the transformed data in a target system like a data warehouse, datalake, or even a database.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a data warehouse or datalake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
The software you might use OAuth with includes: Tableau Power BI Sigma Computing If so, you will need an OAuth provider like Okta, Microsoft Azure AD, Ping Identity PingFederate, or a Custom OAuth 2.0 When to use SCIM vs phData's Provision Tool SCIM manages users and groups with Azure Active Directory or Okta. authorization server.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. We also need data profiling i.e. data discovery, to understand if the data is appropriate for ETL.
Other users Some other users you may encounter include: Dataengineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. Allegro.io
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Die Bedeutung effizienter und zuverlässiger Datenpipelines in den Bereichen Data Science und DataEngineering ist enorm. Vielfältige Unterstützung: Kompatibel mit verschiedenen Datenbankmanagementsystemen wie MS SQL Server und Azure Synapse Analytics. DataLakes: Unterstützt MS Azure Blob Storage.
Both persistent staging and datalakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer data pipeline. If a new, game-changing customer data technology comes along next year, you can easily incorporate it into your composable stack.
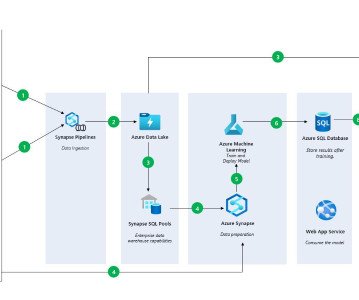
Image by author Hello Welcome to the AzureDataEngineer Project Series, Before building the Data Architecture or any data pipelines in any cloud platform, we need to know the basic terms each platform uses and how the platform will work. Here is the data pipeline building from ADLS to Azure SQL DB.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























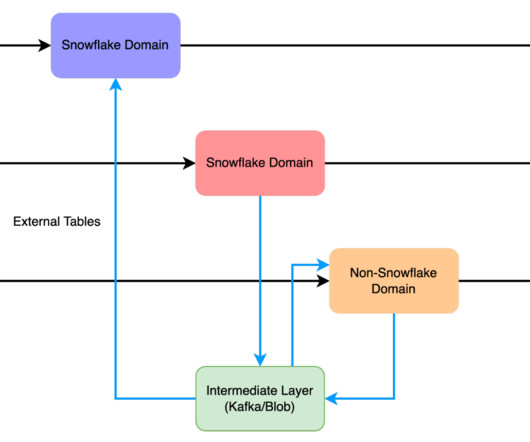











Let's personalize your content