This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. No-code/low-code experience using a diagram view in the data preparation layer similar to Dataflows.
Claims data is often noisy, unstructured, and multi-modal. Manually aligning and labeling this data is laborious and expensive, but—without high-quality representative training data—models are likely to make errors and produce inaccurate results. Book a demo today.
Claims data is often noisy, unstructured, and multi-modal. Manually aligning and labeling this data is laborious and expensive, but—without high-quality representative training data—models are likely to make errors and produce inaccurate results. Book a demo today.
Claims data is often noisy, unstructured, and multi-modal. Manually aligning and labeling this data is laborious and expensive, but—without high-quality representative training data—models are likely to make errors and produce inaccurate results. Book a demo today. See what Snorkel option is right for you.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? Adapted from the book Effective Data Science Infrastructure. Data is at the core of any ML project, so data infrastructure is a foundational concern.
Data can change a lot, models may also quickly evolve and dependencies become old-fashioned which makes it hard to maintain consistency or reproducibility. With weak version control, teams could face problems like inconsistent data, model drift , and clashes in their code. or other dedicated backup servers.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
It’s almost like a specialized data processing and storage solution. For example, you can use BigQuery , AWS , or Azure. A book that I’ve been reading recently that I really love is called “Kill It With Fire” by Marianne Bellotti. And if you want to use different inference stores, you have that option.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


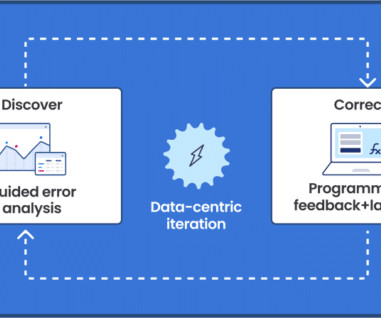









Let's personalize your content