This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Amazon SageMaker AI provides a fully managed service for deploying these machine learning (ML) models with multiple inference options, allowing organizations to optimize for cost, latency, and throughput. AWS has always provided customers with choice. That includes model choice, hardware choice, and tooling choice. The build_and_push.sh
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. Container Caching addresses this scaling challenge by pre-caching the container image, eliminating the need to download it when scaling up.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. Additionally, we discuss how to handle integrations with AWS Lambda and Amazon CloudWatch after enabling Global Resiliency. We walk through the instructions to replicate the bot later in this post.
It’s one of the prerequisite tasks to prepare training data to train a deeplearning model. Specifically, for deeplearning-based autonomous vehicle (AV) and Advanced Driver Assistance Systems (ADAS), there is a need to label complex multi-modal data from scratch, including synchronized LiDAR, RADAR, and multi-camera streams.
SageMaker Large Model Inference (LMI) is deeplearning container to help customers quickly get started with LLM deployments on SageMaker Inference. One of the primary bottlenecks in the deployment process is the time required to download and load containers when scaling up endpoints or launching new instances.
Jump Right To The Downloads Section Introduction In the previous post , we walked through the process of indexing and storing movie data in OpenSearch. If you havent already set up the project from the previous post, you can download the source code from the tutorials “Downloads” section. data queries_set_1.txt
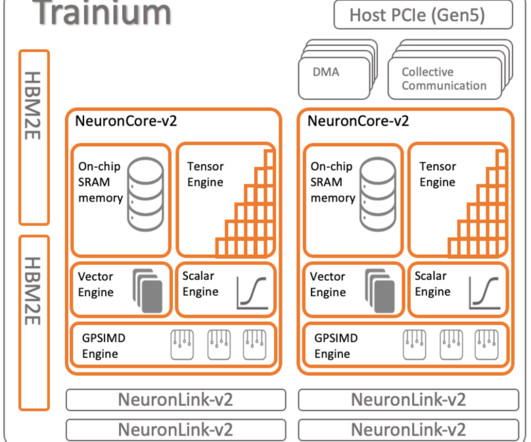
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
For this post, we use the us-east-1 AWS Region: Have access to a POSIX based (Mac/Linux) system or SageMaker notebooks. To learn how to create a SageMaker notebook within a virtual private cloud (VPC), see Connect to SageMaker AI Within your VPC. This post uses CodeBuild and a Docker Dockerfile to build the extended container.
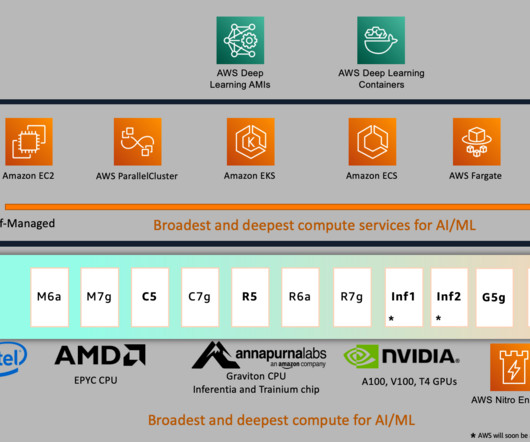
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
This feature eliminates one of the major bottlenecks in deployment scaling by pre-caching container images, removing the need for time-consuming downloads when adding new instances. Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries. Adriana Simmons is a Senior Product Marketing Manager at AWS.
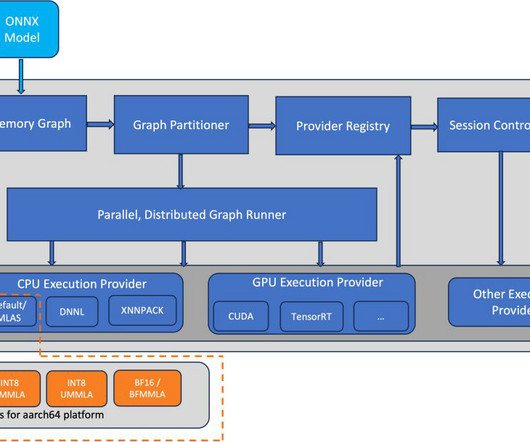
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deeplearning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
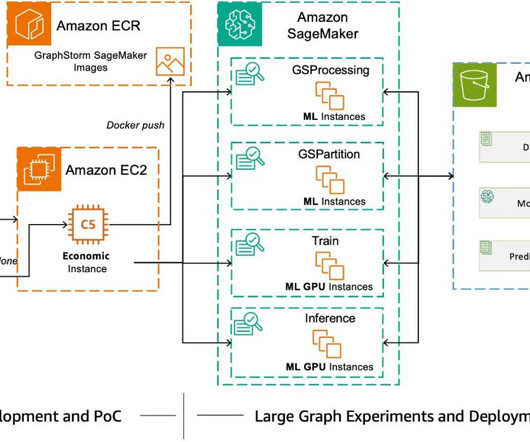
Today, AWS AI released GraphStorm v0.4. Prerequisites To run this example, you will need an AWS account, an Amazon SageMaker Studio domain, and the necessary permissions to run BYOC SageMaker jobs. Using SageMaker Pipelines to train models provides several benefits, like reduced costs, auditability, and lineage tracking. million edges.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deeplearning container (DLC). The goal for the AWS Graviton team was to optimize torch.compile backend for Graviton3 processors.
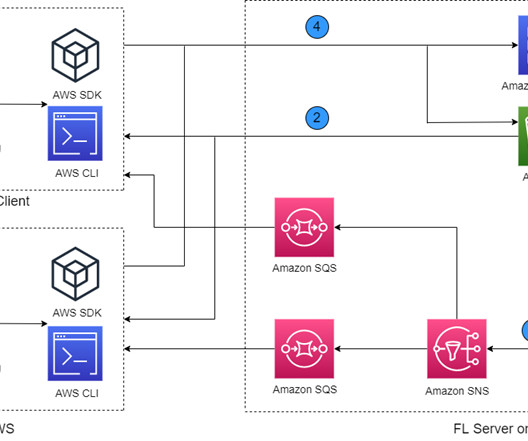
Machine learning (ML), especially deeplearning, requires a large amount of data for improving model performance. Customers often need to train a model with data from different regions, organizations, or AWS accounts. Federated learning (FL) is a distributed ML approach that trains ML models on distributed datasets.
It employs advanced deeplearning technologies to understand user input, enabling developers to create chatbots, virtual assistants, and other applications that can interact with users in natural language. Version control – With AWS CloudFormation, you can use version control systems like Git to manage your CloudFormation templates.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
AWS, Arm, Meta and others helped optimize the performance of PyTorch 2.0 As a result, we are delighted to announce that AWS Graviton-based instance inference performance for PyTorch 2.0 times the speed for BERT, making Graviton-based instances the fastest compute optimized instances on AWS for these models. is up to 3.5
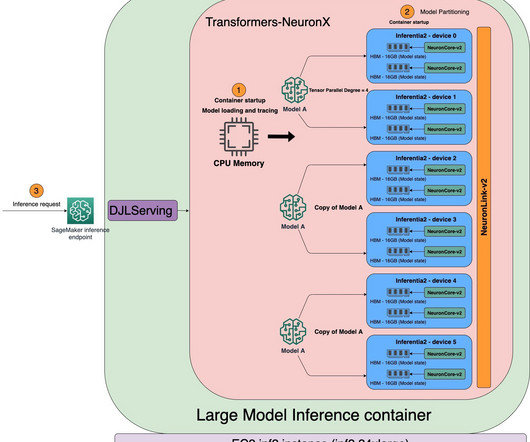
AWS has been innovating with purpose-built chips to address the growing need for powerful, efficient, and cost-effective compute hardware. You can use ml.trn1 and ml.inf2 compatible AWSDeepLearning Containers (DLCs) for PyTorch, TensorFlow, Hugging Face, and large model inference (LMI) to easily get started.
Home Table of Contents Build a Search Engine: Deploy Models and Index Data in AWS OpenSearch Introduction What Will We Do in This Blog? However, we will also provide AWS OpenSearch instructions so you can apply the same setup in the cloud. Why Are We Using Vector Embeddings? What’s Coming Next? Why Are We Using Vector Embeddings?
AWS Lambda AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Prerequisites If youre new to AWS, you first need to create and set up an AWS account. We download the documents and store them under a samples folder locally.
You can use open-source libraries, or the AWS managed Large Model Inference (LMI) deeplearning container (DLC) to dynamically load and unload adapter weights. Prerequisites To run the example notebooks, you need an AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. release, AWS customers can now do same things as they could with PyTorch 1.x 24xlarge with AWS PyTorch 2.0 on AWS PyTorch2.0
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. b64encode(img).decode('utf-8') b64encode(response.content).decode('utf-8')
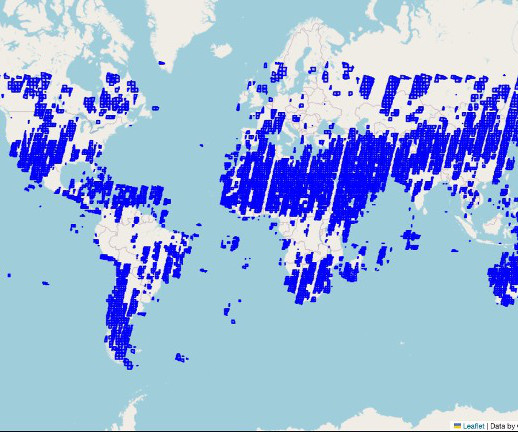
With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. See Amazon SageMaker geospatial capabilities to learn more. He is an ACM Fellow and IEEE Fellow.
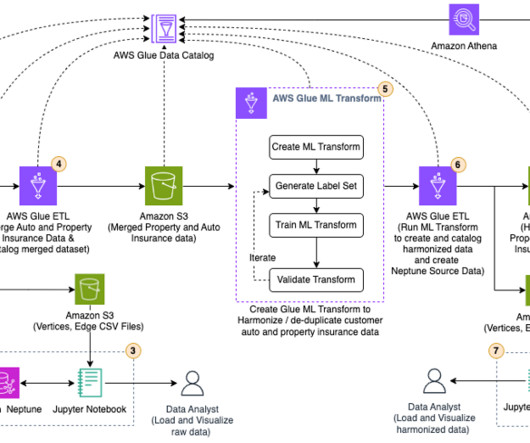
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
In this post, we describe the scale of our AI offerings, the challenges with diverse AI workloads, and how we optimized mixed AI workload inference performance with AWS Graviton3 based c7g instances and achieved 20% throughput improvement, 30% latency reduction, and reduced our cost by 25–30%.
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Many enterprise customers choose to deploy their deeplearning workloads using Kubernetes—the de facto standard for container orchestration in the cloud.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
Over the past decade, advancements in deeplearning have spurred a shift toward so-called global models such as DeepAR [3] and PatchTST [4]. Chronos models have been downloaded over 120 million times from Hugging Face and are available for Amazon SageMaker customers through AutoGluon-TimeSeries and Amazon SageMaker JumpStart.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
You can also download model from Amazon Simple Storage Service (Amazon S3). HF_TOKEN sets the token to download the model. cu128 ), AWS Region ( us-east-1 ), and create a model artifact with all the configurations. To review the latest available container version, see Available DeepLearning Containers Images.
In this post, we show how you can run Stable Diffusion models and achieve high performance at the lowest cost in Amazon Elastic Compute Cloud (Amazon EC2) using Amazon EC2 Inf2 instances powered by AWS Inferentia2. versions on AWS Inferentia2 cost-effectively. You can run both Stable Diffusion 2.1 The Stable Diffusion 2.1
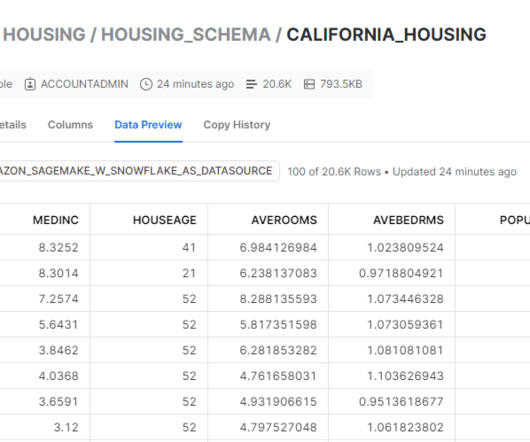
This post shows a way to do this using Snowflake as the data source and by downloading the data directly from Snowflake into a SageMaker Training job instance. We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket.
Deeplearning (DL) is a fast-evolving field, and practitioners are constantly innovating DL models and inventing ways to speed them up. Custom operators are one of the mechanisms developers use to push the boundaries of DL innovation by extending the functionality of existing machine learning (ML) frameworks such as PyTorch.
HF_TOKEN : This parameter variable provides the access token required to download gated models from the Hugging Face Hub, such as Llama or Mistral. Model Base Model Download DeepSeek-R1-Distill-Qwen-1.5B Model Base Model Download DeepSeek-R1-Distill-Qwen-1.5B GenAI Data Scientist at AWS. meta-llama/Llama-3.2-11B-Vision-Instruct
By integrating this model with Amazon SageMaker AI , you can benefit from the AWS scalable infrastructure while maintaining high-quality language model capabilities. Solution overview You can use DeepSeeks distilled models within the AWS managed machine learning (ML) infrastructure. For details, refer to Create an AWS account.
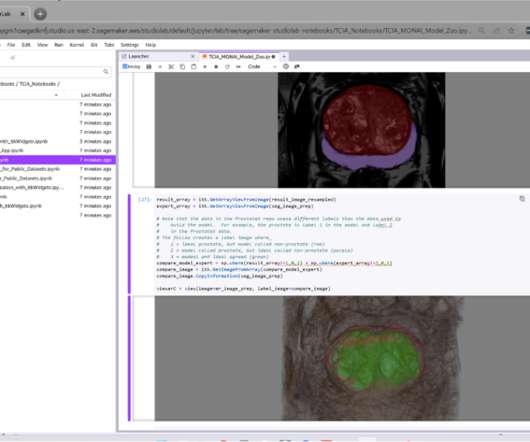
The following example illustrates Studio Lab running a Jupyter notebook that downloads TCIA prostate MRI data, segments it using MONAI, and displays the results using itkWidgets. The first SageMaker notebook shows how to download DICOM images from TCIA and visualize those images using the cinematic volume rendering capabilities of itkWidgets.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content