This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Image 1- [link] Whether you are an experienced or an aspiring datascientist, you must have worked on machinelearning model development comprising of data cleaning, wrangling, comparing different ML models, training the models on Python Notebooks like Jupyter. All the […].
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
Machinelearning (ML) has emerged as a powerful tool to help nonprofits expedite manual processes, quickly unlock insights from data, and accelerate mission outcomesfrom personalizing marketing materials for donors to predicting member churn and donation patterns. This reduces operational overhead for your organization.
Our customers want a simple and secure way to find the best applications, integrate the selected applications into their machinelearning (ML) and generative AI development environment, manage and scale their AI projects. Comet has been trusted by enterprise customers and academic teams since 2017.
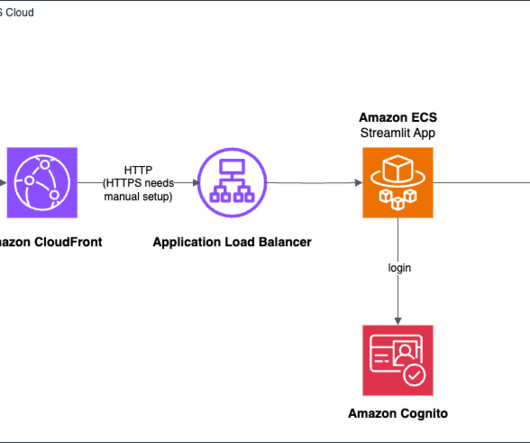
However, as exciting as these advancements are, datascientists often face challenges when it comes to developing UIs and to prototyping and interacting with their business users. Streamlit allows datascientists to create interactive web applications using Python, using their existing skills and knowledge.
AWS SageMaker is transforming the way organizations approach machinelearning by providing a comprehensive, cloud-based platform that standardizes the entire workflow, from data preparation to model deployment. What is AWS SageMaker?
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Choose Create stack.
From social media to e-commerce, businesses generate large amounts of data that can be leveraged to gain insights and make informed decisions. Data science involves the use of statistical and machinelearning techniques to analyze and make […] The post DataScientist at HP Inc.’s
With the current demand for AI and machinelearning (AI/ML) solutions, the processes to train and deploy models and scale inference are crucial to business success. Even though AI/ML and especially generative AI progress is rapid, machinelearning operations (MLOps) tooling is continuously evolving to keep pace.
This article was published as a part of the Data Science Blogathon. Introduction on AWS Sagemaker Datascientists need to create, train and deploy a large number of models as they work. AWS has created a simple […].
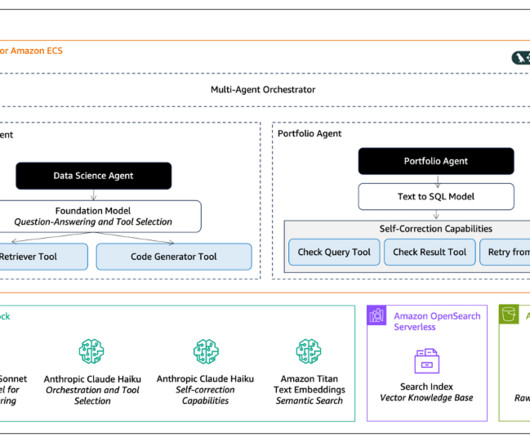
The system interprets database schemas and context, converting natural language questions into accurate queries while maintaining data reliability standards. This post provides instructions to configure a structured data retrieval solution, with practical code examples and templates.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machinelearning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
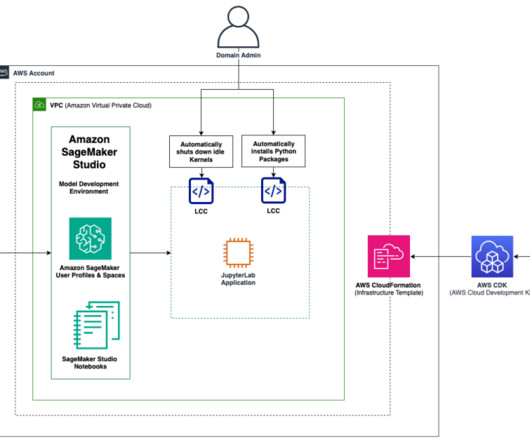
Amazon SageMaker Studio is the first integrated development environment (IDE) purposefully designed to accelerate end-to-end machinelearning (ML) development. You can create multiple Amazon SageMaker domains , which define environments with dedicated data storage, security policies, and networking configurations.
DataScientist Career Path: from Novice to First Job; Understand Neural Networks from a Bayesian Perspective; The Best Ways for Data Professionals to Market AWS Skills; Build Your Own Automated MachineLearning App.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Amazon SageMaker is a cloud-based machinelearning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. By using a combination of AWS services, you can implement this feature effectively, overcoming the current limitations within SageMaker.
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway. Aamna Najmi is a GenAI and Data Specialist at AWS.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
This post showcases how the TSBC built a machinelearning operations (MLOps) solution using Amazon Web Services (AWS) to streamline production model training and management to process public safety inquiries more efficiently. You modify training parameters, evaluation methods, and data locations. in British Columbia.
The company developed an automated solution called Call Quality (CQ) using AI services from Amazon Web Services (AWS). It uses deep learning to convert audio to text quickly and accurately. AWS Lambda is used in this architecture as a transcription processor to store the processed transcriptions into an Amazon OpenSearch Service table.
Summary: In 2025, datascientists in India will be vital for data-driven decision-making across industries. It highlights the growing opportunities and challenges in India’s dynamic data science landscape. Key Takeaways Datascientists in India require strong programming and machinelearning skills for diverse industries.
In the modern, cloud-centric business landscape, data is often scattered across numerous clouds and on-site systems. This fragmentation can complicate efforts by organizations to consolidate and analyze data for their machinelearning (ML) initiatives. For instructions, see Quick setup to Amazon SageMaker.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, datascientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
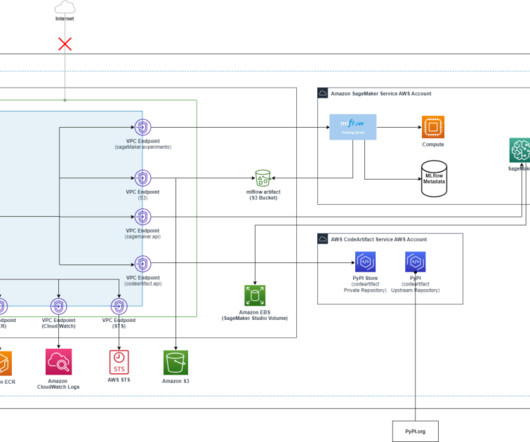
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Machinelearning deployment is a crucial step in bringing the benefits of data science to real-world applications. With the increasing demand for machinelearning deployment, various tools and platforms have emerged to help datascientists and developers deploy their models quickly and efficiently.
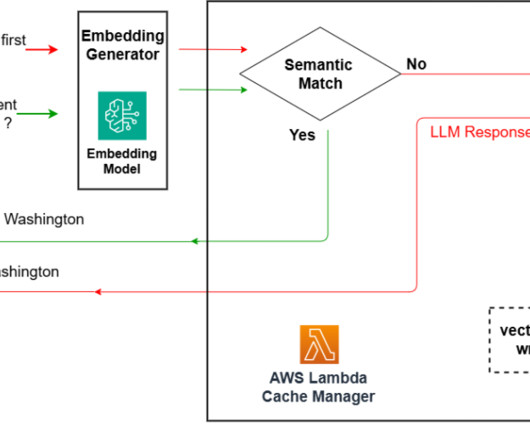
In this post, we demonstrate how to use various AWS technologies to establish a serverless semantic cache system. The solution presented in this post can be deployed through an AWS CloudFormation template. The solution presented in this post can be deployed through an AWS CloudFormation template.
Amazon SageMaker supports geospatial machinelearning (ML) capabilities, allowing datascientists and ML engineers to build, train, and deploy ML models using geospatial data. See Amazon SageMaker geospatial capabilities to learn more. About the Author Xiong Zhou is a Senior Applied Scientist at AWS.
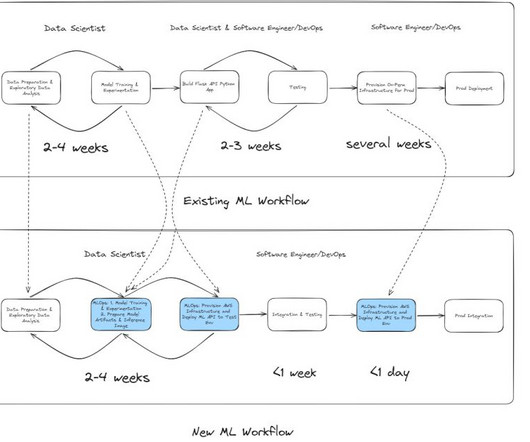
In this post, we share how Radial optimized the cost and performance of their fraud detection machinelearning (ML) applications by modernizing their ML workflow using Amazon SageMaker. To address these challenges and streamline modernization efforts, AWS offers the EBA program.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Transforming unstructured files, maintaining compliance, and mitigating data quality issues all become critical hurdles when an organization moves from AI pilots to production deployments. This helps your data teams deliver high-value AI applications faster and with less risk. Early data filtering cuts these hidden expenses.
To solve this challenge, RDC used generative AI , enabling teams to use its solution more effectively: Data science assistant Designed for data science teams, this agent assists teams in developing, building, and deploying AI models within a regulated environment.
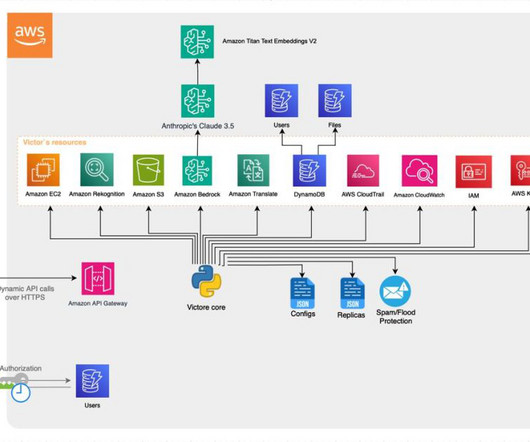
This post details our technical implementation using AWS services to create a scalable, multilingual AI assistant system that provides automated assistance while maintaining data security and GDPR compliance. Amazon Titan Embeddings also integrates smoothly with AWS, simplifying tasks like indexing, search, and retrieval.
With the support of AWS, iFood has developed a robust machinelearning (ML) inference infrastructure, using services such as Amazon SageMaker to efficiently create and deploy ML models. In the past, the data science and engineering teams at iFood operated independently.
(Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. This customer wanted to use machinelearning as a tool to digitize images and recognize handwriting.
This post is co-authored by Manuel Lopez Roldan, SiMa.ai, and Jason Westra, AWS Senior Solutions Architect. Are you looking to deploy machinelearning (ML) models at the edge? Designed to work on SiMas MLSoC (MachineLearning System on Chip) hardware, your models will have seamless compatibility across the entire SiMa.ai
Artificial intelligence (AI) and machinelearning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. Machinelearning operations (MLOps) applies DevOps principles to ML systems.
Streamlit is an open source framework for datascientists to efficiently create interactive web-based data applications in pure Python. Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. Install Python 3.7
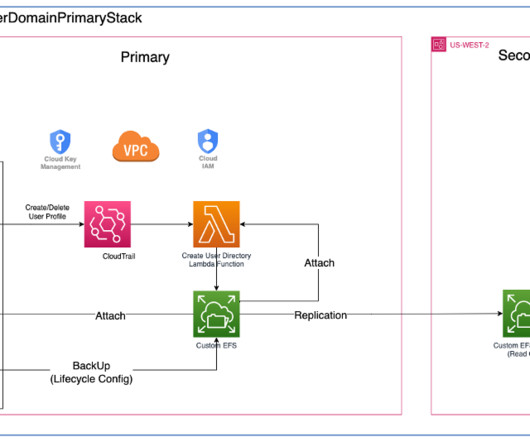
As industries begin adopting processes dependent on machinelearning (ML) technologies, it is critical to establish machinelearning operations (MLOps) that scale to support growth and utilization of this technology. AWS CloudTrail – Monitors and records account activity across AWS infrastructure.
These tools will help you streamline your machinelearning workflow, reduce operational overheads, and improve team collaboration and communication. Machinelearning (ML) is the technology that automates tasks and provides insights. It allows datascientists to build models that can automate specific tasks.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. Generate accurate training data for SageMaker models – For model training, datascientists can use Tecton’s SDK within their SageMaker notebooks to retrieve historical features.
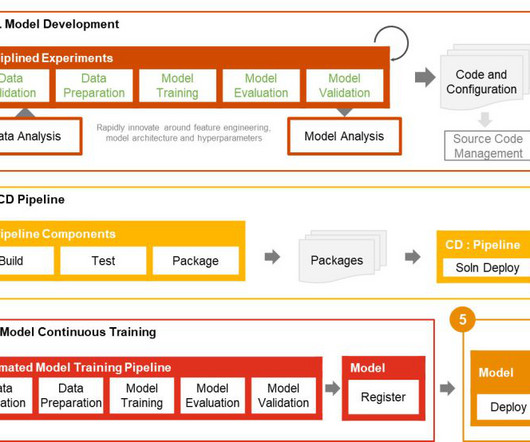
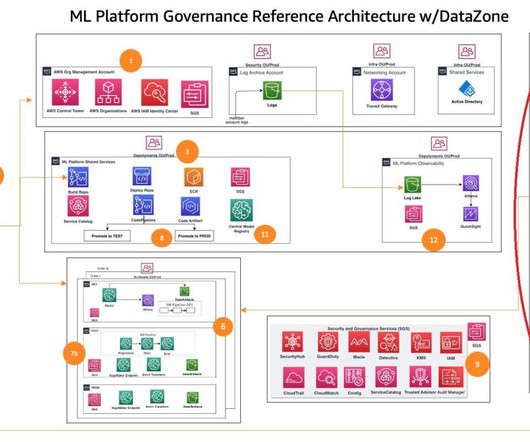
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. To view this series from the beginning, start with Part 1.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machinelearning (ML), data sharing and monetization, and more.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content