
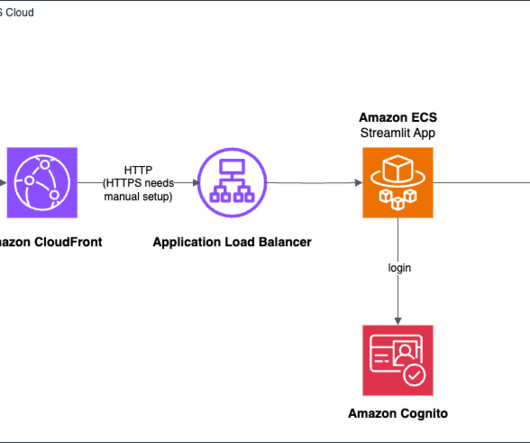
Build and deploy a UI for your generative AI applications with AWS and Python
AWS Machine Learning Blog
NOVEMBER 6, 2024
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machine learning. Choose the us-east-1 AWS Region from the top right corner. Choose Manage model access.























Let's personalize your content