This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS’ Legendary Presence at DAIS: Customer Speakers, Featured Breakouts, and Live Demos! Amazon Web Services (AWS) returns as a Legend Sponsor at Data + AI Summit 2025 , the premier global event for data, analytics, and AI.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
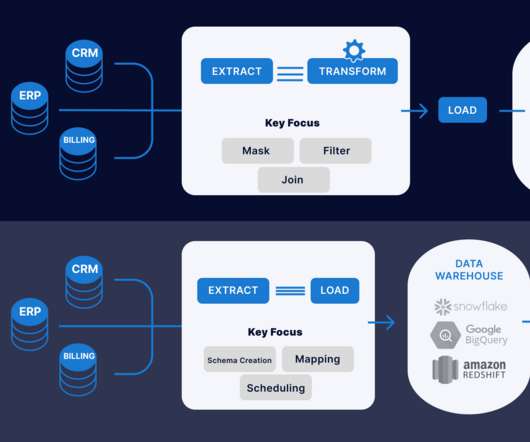
Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems. Traditionally, ETL processes are […].
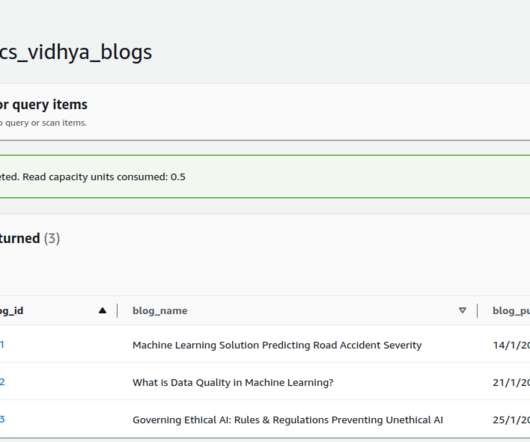
While not all of us are tech enthusiasts, we all have a fair knowledge of how Data Science works in our day-to-day lives. All of this is based on Data Science which is […]. The post Step-by-Step Roadmap to Become a DataEngineer in 2023 appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Introduction Amazon Redshift is a fully managed, petabyte-scale data warehousing Amazon Web Services (AWS). It allows users to easily set up, operate, and scale a datawarehouse in the cloud.
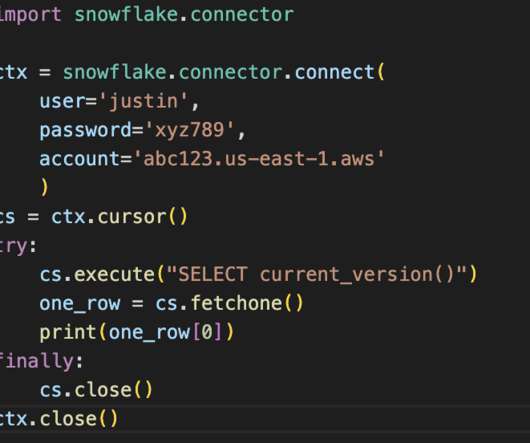
Businesses have adopted Snowflake as migration from on-premise enterprise datawarehouses (such as Teradata) or a more flexibly scalable and easier-to-manage alternative to […]. The post Data Warehousing with Snowflake and Other Alternatives appeared first on Analytics Vidhya.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Introduction Amazon Elastic MapReduce (EMR) is a fully managed service that makes it easy to process large amounts of data using the popular open-source framework Apache Hadoop. EMR enables you to run petabyte-scale datawarehouses and analytics workloads using the Apache Spark, Presto, and Hadoop ecosystems.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
The workflow includes the following steps: Within the SageMaker Canvas interface, the user composes a SQL query to run against the GCP BigQuery datawarehouse. Athena uses the Athena Google BigQuery connector , which uses a pre-built AWS Lambda function to enable Athena federated query capabilities.
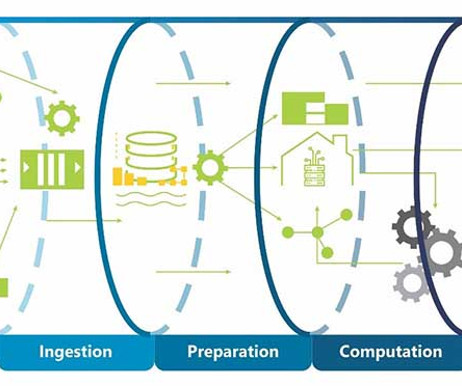
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
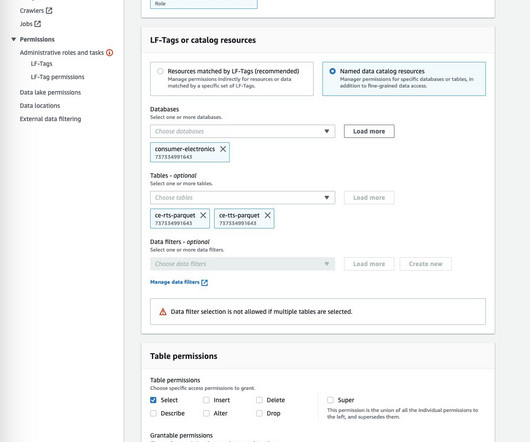
This means that business analysts who want to extract insights from the large volumes of data in their datawarehouse must frequently use data stored in Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift. Choose Grant.
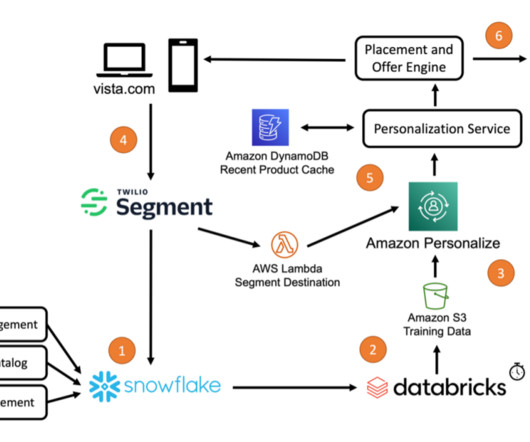
In this post, we show you how VistaPrint uses a combination of Amazon Personalize , Twilio Segment , and auxiliary AWS services and partner solutions to better understand their customers’ needs and provide personalized product recommendations. Transform the data to create Amazon Personalize training data.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To capture unanticipated, less obvious data patterns, you can enable anomaly detection.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
EvolvabilityIts Mostly About Data Contracts Editors note: Elliott Cordo is a speaker for ODSC East this May 1315! Be sure to check out his talk, Enabling Evolutionary Architecture in DataEngineering , there to learn about data contracts and plentymore.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
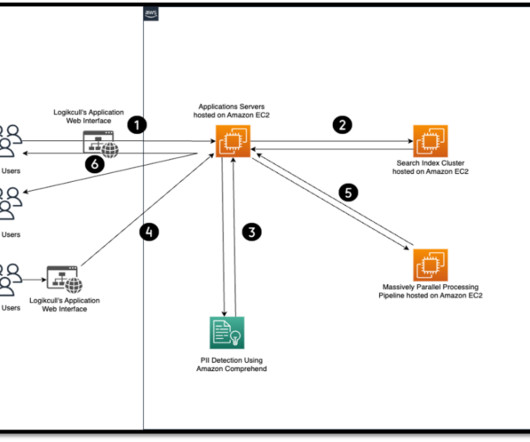
Give the features a try and send us feedback either through the AWS forum for Amazon Comprehend or through your usual AWS support contacts. About the Authors Aman Tiwari is a General Solutions Architect working with Worldwide Commercial Sales at AWS. Outside of work, he enjoys playing lawn tennis and reading books.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data.
This article was published as a part of the Data Science Blogathon. Introduction Data sharing has become so easy today, and we can share the details with just a few clicks. The post How to Encrypt and Decrypt the Data in PySpark? These details can get leaked if the […].
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
Introduction Data pipelines play a critical role in the processing and management of data in modern organizations. A well-designed data pipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses. Cost : Is the pricing predictable and within budget?
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
Thankfully, there are tools available to help with metadata management, such as AWS Glue, Azure Data Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
The success of any data initiative hinges on the robustness and flexibility of its big data pipeline. What is a Data Pipeline? A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a datawarehouse or data lake.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Truly a must-have tool in your dataengineering arsenal!
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content