This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. At the time, I knew little about AI or machine learning (ML). seconds, securing the 2018 AWS DeepRacer grand champion title!
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters.
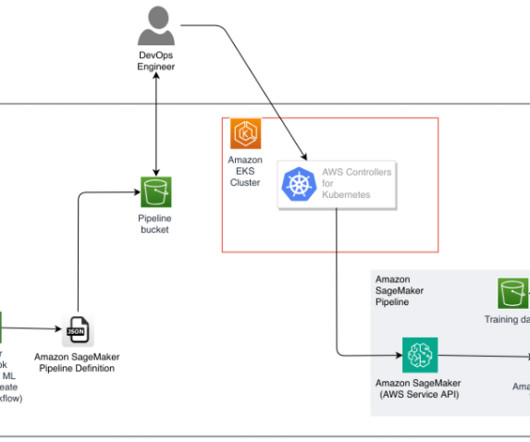
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Solution overview The steps to implement the solution are as follows: Create the EKS cluster.
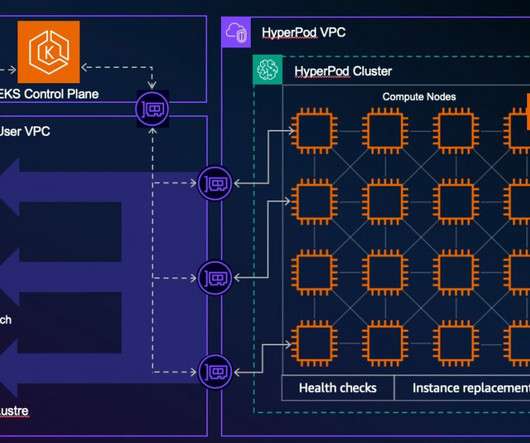
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
Scaling machine learning (ML) workflows from initial prototypes to large-scale production deployment can be daunting task, but the integration of Amazon SageMaker Studio and Amazon SageMaker HyperPod offers a streamlined solution to this challenge. Make sure you have the latest version of the AWS Command Line Interface (AWS CLI).
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. For this post we’ll use a provisioned Amazon Redshift cluster.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster.
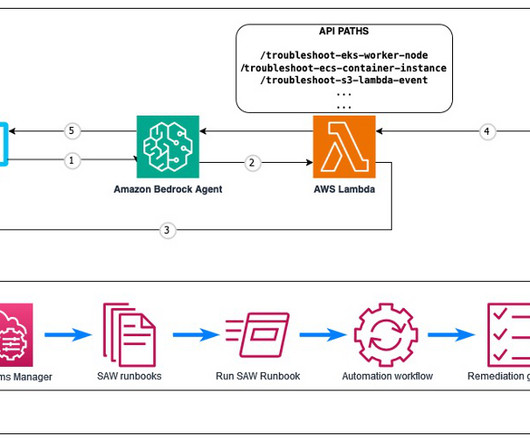
As AWS environments grow in complexity, troubleshooting issues with resources can become a daunting task. Fortunately, AWS provides a powerful tool called AWS Support Automation Workflows , which is a collection of curated AWS Systems Manager self-service automation runbooks. The agent uses Anthropics Claude 3.5
As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. Larger clusters, more failures, smaller MTBF As cluster size increases, the entropy of the system increases, resulting in a lower MTBF. It implies that if a single instance fails, it stops the entire job.
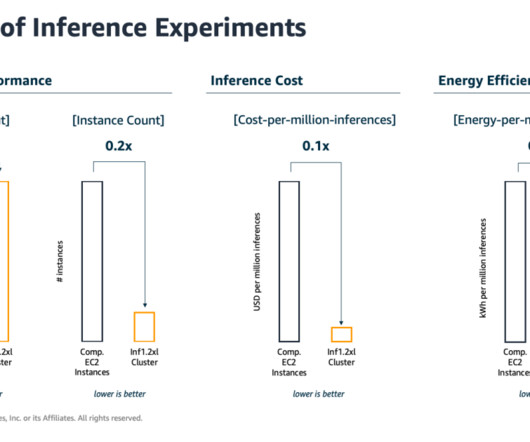
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
These experiences are made possible by our machine learning (ML) backend engine, with ML models built for video understanding, search, recommendation, advertising, and novel visual effects. By using sophisticated ML algorithms, the platform efficiently scans billions of videos each day.
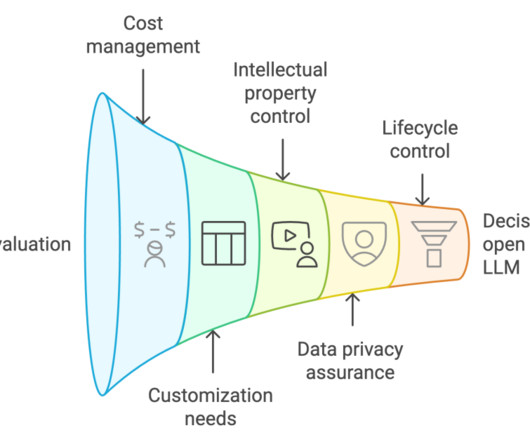
The potential for such large business value is galvanizing tens of thousands of enterprises to build their generative AI applications in AWS. This post addresses these cost considerations so you can optimize your generative AI costs in AWS. Annual costs (directional)*. These costs are based on assumptions.
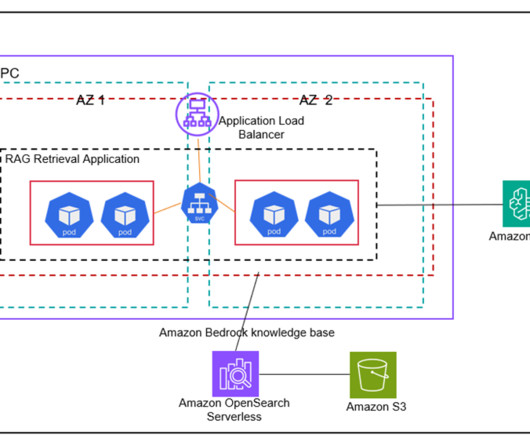
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience. Technical architecture The overall solution is implemented using AWS services and LangChain. AWS Glue AWS Glue is used for data cataloging.
In this post, we demonstrate a solution using Amazon Elastic Kubernetes Service (EKS) with Amazon Bedrock to build scalable and containerized RAG solutions for your generative AI applications on AWS while bringing your unstructured user file data to Amazon Bedrock in a straightforward, fast, and secure way. Sonnet on Amazon Bedrock.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. HBase is employed to offer real-time key-based access to data.
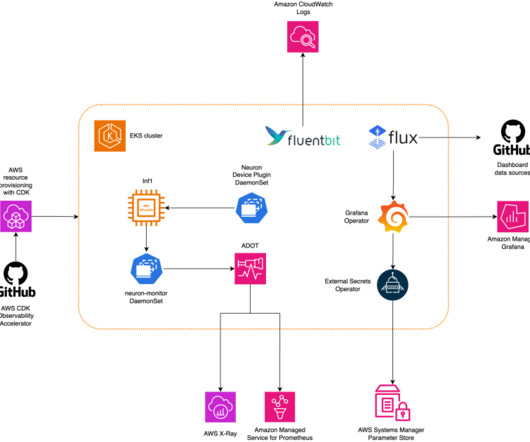
Recent developments in machine learning (ML) have led to increasingly large models, some of which require hundreds of billions of parameters. In such distributed environments, observability of both instances and ML chips becomes key to model performance fine-tuning and cost optimization.
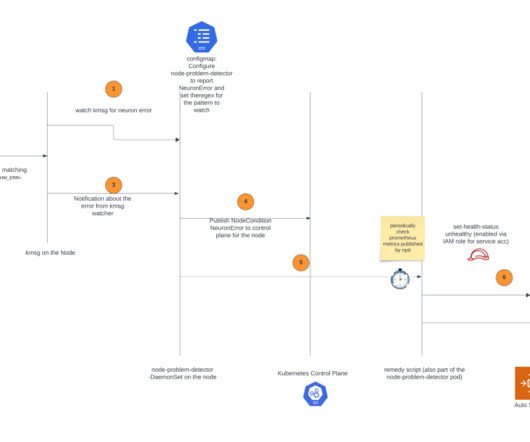
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). eks-5e0fdde Install the required AWS Identity and Access Management (IAM) role for the service account and the node problem detector plugin.
When the stakes are high, success requires not just cutting-edge technology, but the ability to operationalize it at scalea challenge that AWS has consistently solved for customers. To train generative AI models at enterprise scale, ServiceNow uses NVIDIA DGX Cloud on AWS. The team achieved 97.1%
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. The launcher will interface with your cluster with Slurm or Kubernetes native constructs.
Amazon Web Services (AWS) provides the essential compute infrastructure to support these endeavors, offering scalable and powerful resources through Amazon SageMaker HyperPod. To offer a more concrete look at these trends, the following is a deep dive into how climate tech startups are building FMs on AWS.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deep learning frameworks.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container , an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS).
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
We demonstrate this solution by walking you through a comprehensive step-by-step guide on how to fine-tune YOLOv8 , a real-time object detection model, on Amazon Web Services (AWS) using a custom dataset. You can train foundation models (FMs) for weeks and months without disruption by automatically monitoring and repairing training clusters.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
The seeds of a machine learning (ML) paradigm shift have existed for decades, but with the ready availability of scalable compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are transforming their businesses.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. For this post, we demonstrate SMP implementation on SageMaker trainings jobs.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. This entire workflow is shown in the following solution diagram.
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. This approach combines the efficiency of machine learning with human judgment in the following way: The ML model processes and classifies transactions rapidly.
The rise of generative AI has significantly increased the complexity of building, training, and deploying machine learning (ML) models. It now demands deep expertise, access to vast datasets, and the management of extensive compute clusters.
Understanding these advantages, we partnered with AWS to embark on a journey to develop HxGN Alix, an AI-powered digital worker using AWS generative AI services. The AWS services include: Amazon Elastic Kubernetes Service (Amazon EKS) We used Amazon EKS for compute and model deployment.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
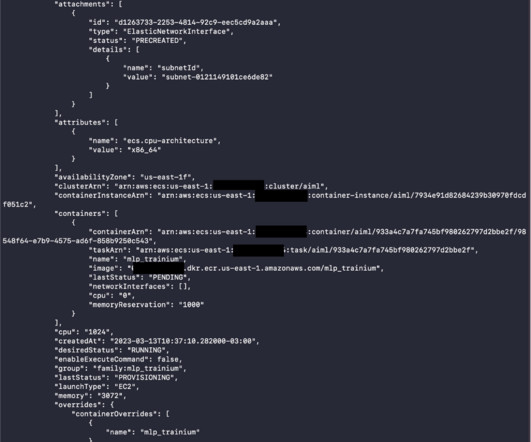
Running machine learning (ML) workloads with containers is becoming a common practice. What you get is an ML development environment that is consistent and portable. With containers, scaling on a cluster becomes much easier. With containers, scaling on a cluster becomes much easier. Run the ML task on Amazon ECS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content