This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
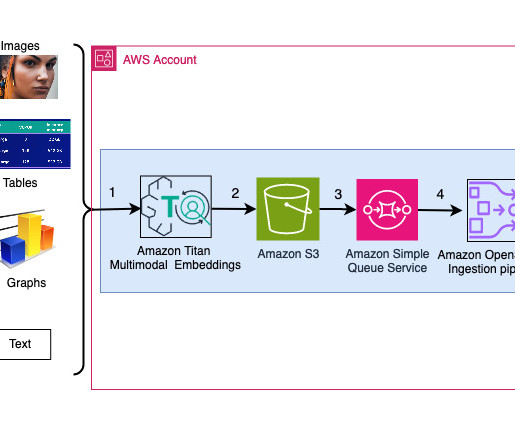
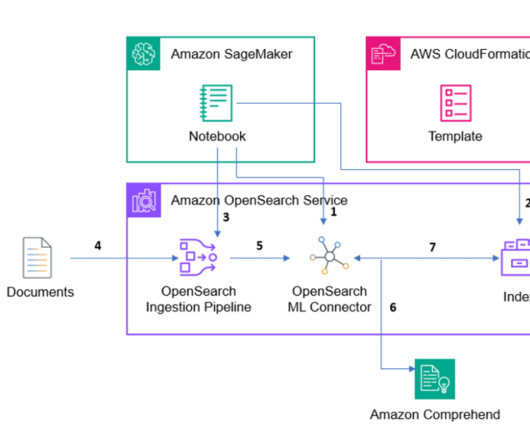
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
In this tutorial, well explore how OpenSearch performs k-NN (k-NearestNeighbor) search on embeddings. Each word or sentence is mapped to a high-dimensional vector space, where similar meanings cluster together. OpenSearch uses k-NearestNeighbors (k-NN) search to find the most similar embeddings in the dataset.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. The implementation included a provisioned three-node sharded OpenSearch Service cluster. Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks.
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. MongoDB Atlas Vector Search uses a technique called k-nearestneighbors (k-NN) to search for similar vectors. k-NN works by finding the k most similar vectors to a given vector.
Home Table of Contents Build a Search Engine: Deploy Models and Index Data in AWS OpenSearch Introduction What Will We Do in This Blog? However, we will also provide AWS OpenSearch instructions so you can apply the same setup in the cloud. This is useful for running OpenSearch locally for testing before deploying it on AWS.
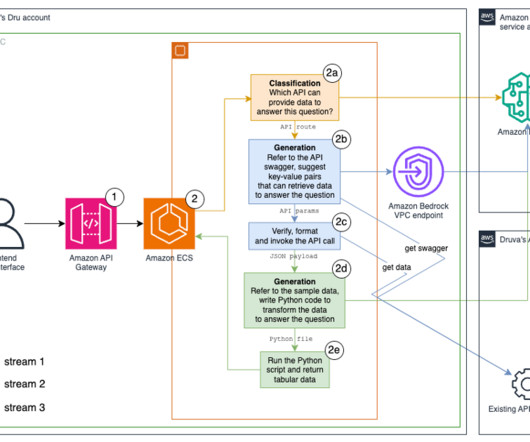
We tried different methods, including k-nearestneighbor (k-NN) search of vector embeddings, BM25 with synonyms , and a hybrid of both across fields including API routes, descriptions, and hypothetical questions. The request arrives at the microservice on our existing Amazon Elastic Container Service (Amazon ECS) cluster.
The listing indexer AWS Lambda function continuously polls the queue and processes incoming listing updates. With Amazon OpenSearch Service, you get a fully managed solution that makes it simple to deploy, scale, and operate OpenSearch in the AWS Cloud. For data handling, 24 data nodes (r6gd.2xlarge.search
We used AWS services including Amazon Bedrock , Amazon SageMaker , and Amazon OpenSearch Serverless in this solution. In this series, we use the slide deck Train and deploy Stable Diffusion using AWS Trainium & AWS Inferentia from the AWS Summit in Toronto, June 2023 to demonstrate the solution.
Many AWS media and entertainment customers license IMDb data through AWS Data Exchange to improve content discovery and increase customer engagement and retention. We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. Background. Solution overview. Prerequisites.
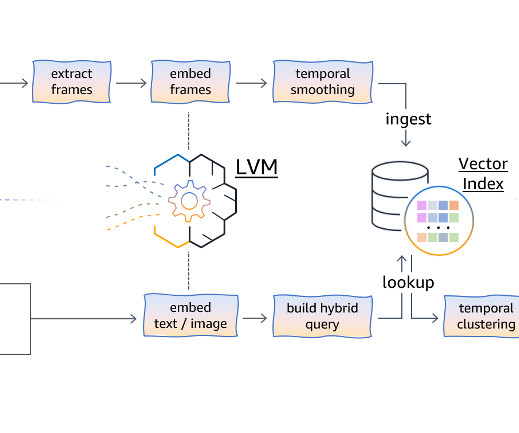
We introduce some use case-specific methods, such as temporal frame smoothing and clustering, to enhance the video search performance. Setting the search size, which can be effectively combined with temporal clustering. The retrieved frame embeddings undergo temporal clustering.
You can also use an AWS CloudFormation template by following the GitHub instructions to create a domain. By using an interface VPC endpoint (interface endpoint), the communication between your VPC and Studio is conducted entirely and securely within the AWS network. aws s3 cp $BUILD_ROOT/model.tar.gz $S3_PATH !bash
The integration with Amazon Bedrock is achieved through the Boto3 Python module, which serves as an interface to the AWS, enabling seamless interaction with Amazon Bedrock and the deployment of the classification model. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
You will execute scripts to create an AWS Identity and Access Management (IAM) role for invoking SageMaker, and a role for your user to create a connector to SageMaker. An AWS account You will need to be able to create an OpenSearch Service domain and two SageMaker endpoints. Python The code has been tested with Python version 3.13.
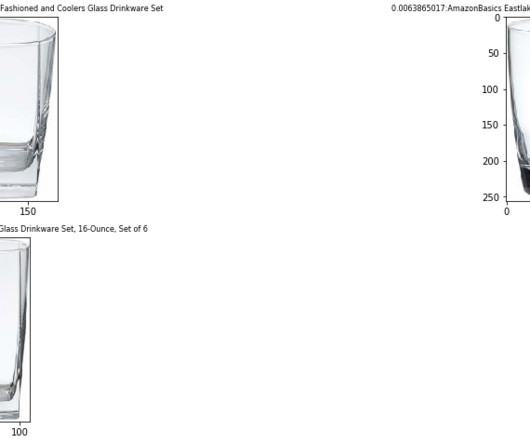
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. As an example, in the following figure, we separate Cover 3 Zone (green cluster on the left) and Cover 1 Man (blue cluster in the middle). She received her Ph.D.
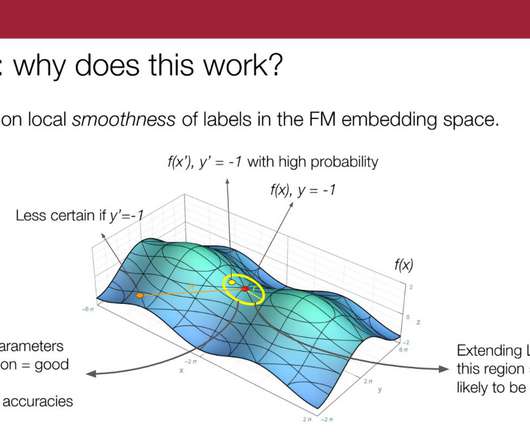
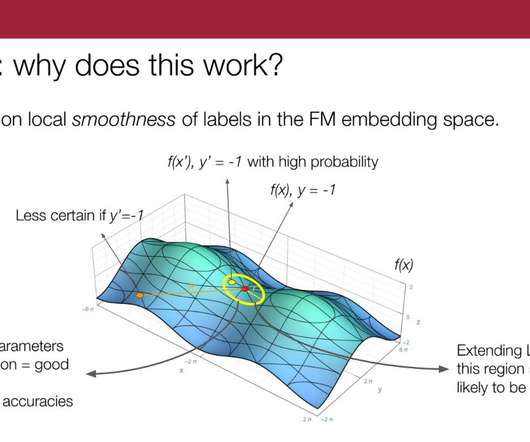
We tackle that by learning these clusters in the foundation models embedding space and providing those clusters as the subgroups—and basically learning a weak supervision model on each of those clusters. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
We tackle that by learning these clusters in the foundation models embedding space and providing those clusters as the subgroups—and basically learning a weak supervision model on each of those clusters. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. customer segmentation), clustering algorithms like K-means or hierarchical clustering might be appropriate.
To help you replicate this setup, weve provided the necessary source code, an Amazon SageMaker notebook, and an AWS CloudFormation template. This requires the OpenSearch Cluster to have fine grained access control enabled. Use the following steps to attach this role to the OpenSearch cluster.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content