This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deep learning frameworks.
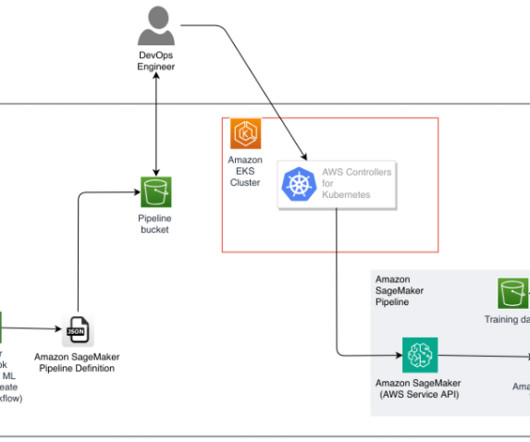
A challenge for DevOps engineers is the additional complexity that comes from using Kubernetes to manage the deployment stage while resorting to other tools (such as the AWS SDK or AWS CloudFormation ) to manage the model building pipeline. kubectl for working with Kubernetes clusters. eksctl for working with EKS clusters.
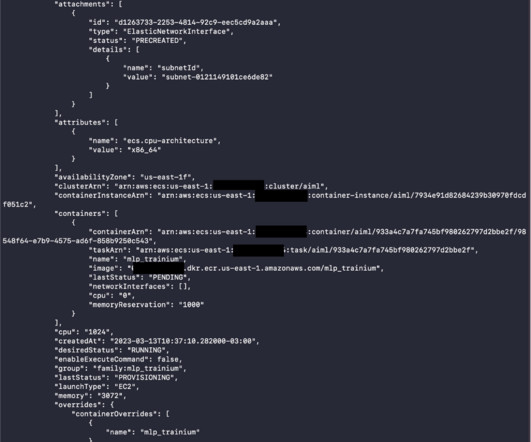
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deep learning training. Create a task definition to define an ML training job to be run by Amazon ECS.
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. A Ray cluster consists of a single head node and a number of connected worker nodes. Ray clusters and Kubernetes clusters pair well together.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The AML feature store standardizes variable definitions using scientifically validated algorithms.
It also comes with ready-to-deploy code samples to help you get started quickly with deploying GeoFMs in your own applications on AWS. For a full architecture diagram demonstrating how the flow can be implemented on AWS, see the accompanying GitHub repository. Lets dive in! Solution overview At the core of our solution is a GeoFM.
Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. The data scientist is responsible for moving the code into SageMaker, either manually or by cloning it from a code repository such as AWS CodeCommit.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. The following figure shows schema definition and model which reference it. There’s no sharing of underlying compute resources with other tenants.
Prerequisites You should have the following prerequisites: An AWS account A SageMaker notebook instance An S3 bucket to store the input data Process the data To start, upload the log dataset to an S3 bucket in your AWS account. aws ecr get-login --region $region --registry-ids $account_id --no-include-email) !aws client("sts").get_caller_identity().get("Account")
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses. Delete the MongoDB Atlas cluster. As always, AWS welcomes feedback.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
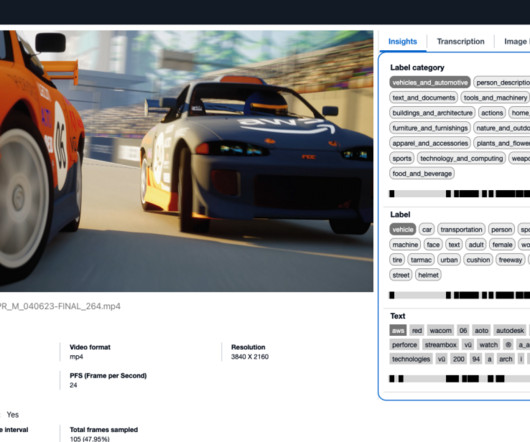
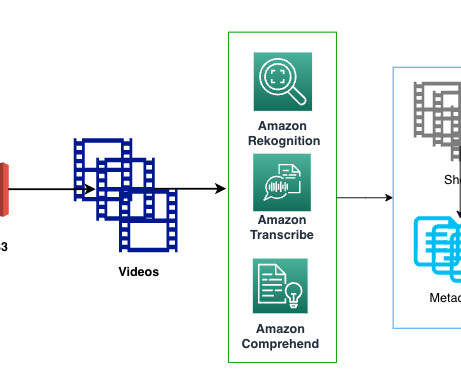
In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes. This solution, powered by AWS AI and generative AI services, meets these needs. Classify the video into IAB categories.
These services support single GPU to HyperPods (cluster of GPUs) for training and include built-in FMOps tools for tracking, debugging, and deployment. Solution overview CrewAI provides a robust framework for developing multi-agent systems that integrate with AWS services, particularly SageMaker AI.
Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure. You can use the provided AWS CloudFormation stack to set up the architectural components for this solution.
In this article we will speak about Serverless Machine learning in AWS, so sit back, relax, and enjoy! Introduction to Serverless Machine Learning in AWS Serverless computing reshapes machine learning (ML) workflow deployment through its combination of scalability and low operational cost, and reduced total maintenance expenses.
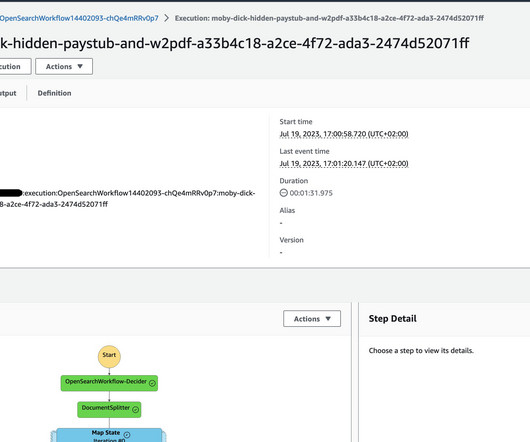
We’ll cover how technologies such as Amazon Textract, AWS Lambda , Amazon Simple Storage Service (Amazon S3), and Amazon OpenSearch Service can be integrated into a workflow that seamlessly processes documents. The main concepts used are the AWS Cloud Development Kit (CDK) constructs, the actual CDK stacks and AWS Step Functions.
Since then, this feature has been integrated into many of our managed Amazon Machine Images (AMIs), such as the Deep Learning AMI and the AWS ParallelCluster AMI. Prerequisites To simplify reproducing the entire stack from this post, we use a container that has all the required tooling (aws cli, eksctl, helm, etc.) already installed.
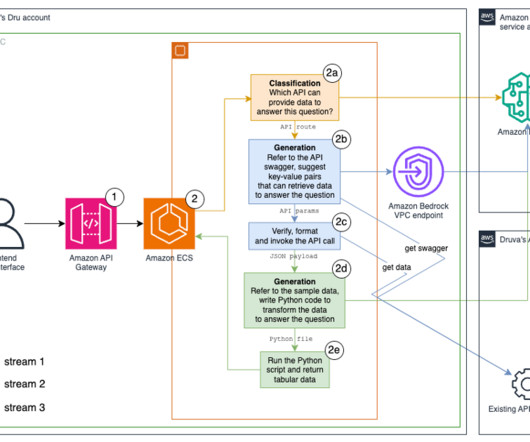
Using Amazon Bedrock aligned naturally with Druva’s existing environment on AWS, maintaining a secure and efficient extension of their capabilities. The request arrives at the microservice on our existing Amazon Elastic Container Service (Amazon ECS) cluster. Look up the API definition This step uses an FM to perform classification.
In the rest of this paper, we will explore how Cloud Pak for Integration, deployed on Red Hat OpenShift is the best way to provide integrations deploying in AWS. ROSA is jointly engineered and supported by AWS and Red Hat. Why ROSA for Cloud Pak for Integration in AWS? What is ROSA? Interested to hear more?
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. Create database connections The built-in SQL browsing and execution capabilities of SageMaker Studio are enhanced by AWS Glue connections. or later image versions.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. We developed an AWS Batch workshop that illustrates the steps to set up the distributed training cluster with AWS Batch. billion-parameter model using the wikicorpus-en dataset. Pre-training of a 1.5-billion-parameter
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. The full code can be found on the aws-samples-for-ray GitHub repository. XGBoost-Ray uses this information to distribute the training across all the nodes attached to the Ray cluster. You can specify resource requirements in actors too.
Problem definition Traditionally, the recommendation service was mainly provided by identifying the relationship between products and providing products that were highly relevant to the product selected by the customer. xlarge","Name":"Master Instance Group"},{"InstanceCount":2,"InstanceGroupType":"CORE","InstanceType":"r5.xlarge","Name":"Core
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Suppliers of data center GPUs include NVIDIA, AMD, Intel, and others.
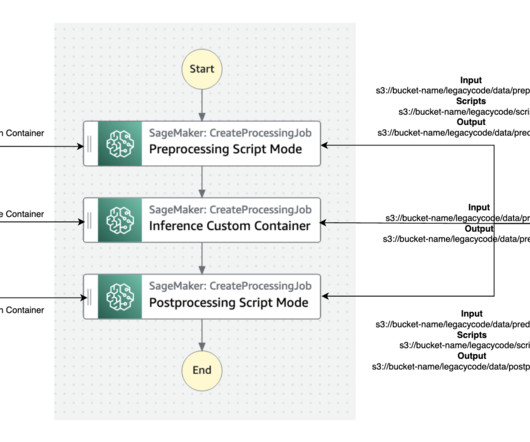
One of the several challenges faced was adapting the existing on-premises pipeline solution for use on AWS. The solution involved two key components: Modifying and extending existing code – The first part of our solution involved the modification and extension of our existing code to make it compatible with AWS infrastructure.
The AI and data science team dive into a plethora of multi-dimensional data and run a variety of use cases like player journey optimization, game action detection, hyper-personalization, customer 360, and more on AWS. Solution overview The following diagram illustrates the solution architecture. amazonaws.com/tensorflow-training:2.11.0-cpu-py39-ubuntu20.04-sagemaker",
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Machine Learning Operations (MLOps): Overview, Definition, and Architecture (by Kreuzberger, et al., AIIA MLOps blueprints.
For example, it can scale the data, perform univariate feature selection, conduct PCA at different variance threshold levels, and apply clustering. If it doesn’t exist, create a new AWS Identity and Access Management (IAM) role and attach the AmazonSageMakerFullAccess IAM policy. This solution will incur costs in your AWS account.
You can integrate a Data Wrangler data preparation flow into your machine learning (ML) workflows to simplify data preprocessing and feature engineering, taking data preparation to production faster without the need to author PySpark code, install Apache Spark, or spin up clusters. Sovik Kumar Nath is an AI/ML solution architect with AWS.
Infrastructure and development challenges Veriff’s backend architecture is based on a microservices pattern, with services running on different Kubernetes clusters hosted on AWS infrastructure. João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. Solutions Architect at AWS based in Helsinki, Finland.
Usually, if the dataset or model is too large to be trained on a single instance, distributed training allows for multiple instances within a cluster to be used and distribute either data or model partitions across those instances during the training process. Each account or Region has its own training instances.
Prerequisites To follow this tutorial, you need the following: An AWS account. AWS Identity and Access Management (IAM) permissions. Spark provides distributed processing on clusters to handle data that is too big for a single machine. Prior to joining AWS, Ninad worked as a software developer for 12+ years.
The processed videos are sent to AWS services like Amazon Rekognition, Amazon Transcribe, and Amazon Comprehend to generate metadata at shot level and video level. We use AWS Step Functions to orchestrate the entire pipeline. Search index creation We use an OpenSearch cluster (OpenSearch Service domain) with t3.medium.search
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. Software Development Layers.
Patrick Lewis “We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers.
Choosing the right method of machine learning deployment is crucial for optimal performance and scalability Alternatively, web services can offer more cost-effective and almost real-time predictions, especially when the model runs on a cluster or cloud service with readily available CPU power.
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. We included the steps to achieve this in the last section of the notebook.
To try out the solution in your own account, make sure that you have the following in place: An AWS account. To run this JumpStart solution and have the infrastructure deploy to your AWS account, you must create an active Amazon SageMaker Studio instance (see Onboard to Amazon SageMaker Studio ). Conclusion.
There are various implementations–from the industrial-grade AWS SageMaker Autopilot and Google Cloud Vertex AI , to offerings from smaller players–but, in a nutshell, some developers spotted that same for() loop and built a slick UI on top. I currently see an opening for clustering-as-a-service, in case you’re looking for ideas.)
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content