This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
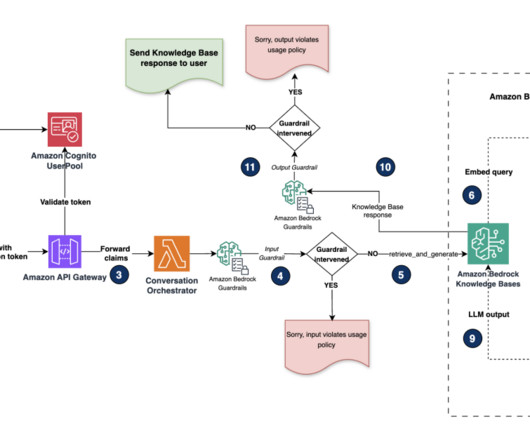
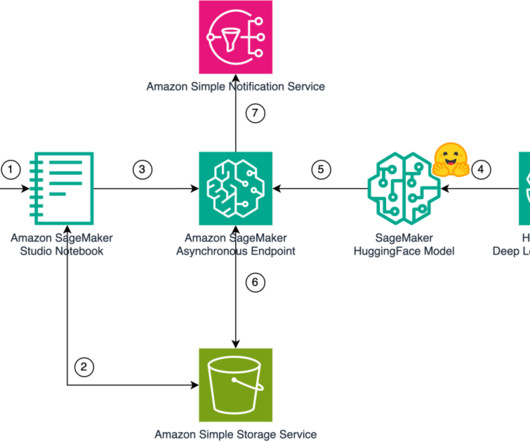
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. Additionally, we discuss how to handle integrations with AWS Lambda and Amazon CloudWatch after enabling Global Resiliency. We walk through the instructions to replicate the bot later in this post.
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
It employs advanced deeplearning technologies to understand user input, enabling developers to create chatbots, virtual assistants, and other applications that can interact with users in natural language. Version control – With AWS CloudFormation, you can use version control systems like Git to manage your CloudFormation templates.
When we launched LLM-as-a-judge (LLMaJ) and Retrieval Augmented Generation (RAG) evaluation capabilities in public preview at AWS re:Invent 2024 , customers used them to assess their foundation models (FMs) and generative AI applications, but asked for more flexibility beyond Amazon Bedrock models and knowledge bases. Original price: $153.15
About the Authors Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deeplearning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! You marked your calendars, you booked your hotel, and you even purchased the airfare. Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
run_opensearch.sh Running OpenSearch Locally A script to start OpenSearch using Docker for local testing before deploying to AWS. Register the Sentence Transformer model in AWS OpenSearch: AWS users must ensure that OpenSearch can access the model before indexing. These can be used for evaluation and comparison.
To assist in this effort, AWS provides a range of generative AI security strategies that you can use to create appropriate threat models. For all data stored in Amazon Bedrock, the AWS shared responsibility model applies.
Home Table of Contents Build a Search Engine: Deploy Models and Index Data in AWS OpenSearch Introduction What Will We Do in This Blog? However, we will also provide AWS OpenSearch instructions so you can apply the same setup in the cloud. This is useful for running OpenSearch locally for testing before deploying it on AWS.
You can recreate the example manually or using the AWS Cloud Development Kit (AWS CDK) by following our GitHub repository. However, booking, updating, or canceling a PTO request requires changes on a database and are actions that should be confirmed before execution. With over 10 years of experience in AI/ML.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
NIM is available as a paid offering as part of the NVIDIA AI Enterprise software subscription available on AWS Marketplace. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. Qing Lan is a Software Development Engineer in AWS.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
In this post, we show how you can run Stable Diffusion models and achieve high performance at the lowest cost in Amazon Elastic Compute Cloud (Amazon EC2) using Amazon EC2 Inf2 instances powered by AWS Inferentia2. versions on AWS Inferentia2 cost-effectively. You can run both Stable Diffusion 2.1 The Stable Diffusion 2.1
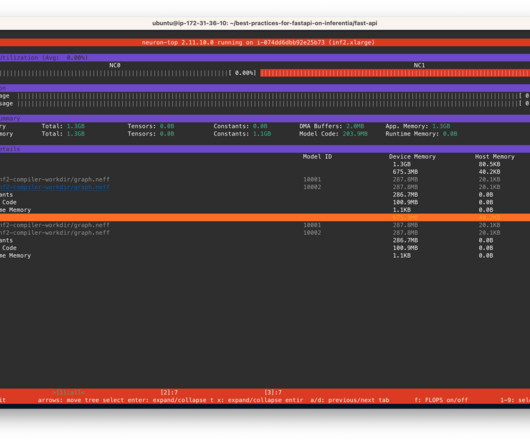
When deploying DeepLearning models at scale, it is crucial to effectively utilize the underlying hardware to maximize performance and cost benefits. In this post we walk you through the process of deploying FastAPI model servers on AWS Inferentia devices (found on Amazon EC2 Inf1 and Amazon EC Inf2 instances).
From the earliest days, Amazon has used ML for various use cases such as book recommendations, search, and fraud detection. Similar to the rest of the industry, the advancements of accelerated hardware have allowed Amazon teams to pursue model architectures using neural networks and deeplearning (DL).
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). To address customers’ requirements about data privacy and sovereignty, SnapLogic deploys the data plane within the customer’s VPC on AWS.
In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. Trn1 instances are purpose built for high-performance deeplearning model training while offering up to 50% cost-to-train savings over comparable GPU-based instances.
Solution overview The entire infrastructure of the solution is provisioned using the AWS Cloud Development Kit (AWS CDK), which is an infrastructure as code (IaC) framework to programmatically define and deploy AWS resources. AWS CDK version 2.0 AWS CDK version 2.0
Some examples include extracting players and positions in an NFL game summary, products mentioned in an AWS keynote transcript, or key names from an article on a favorite tech company. We extract the default generic entities through the AWS SDK for Python (Boto3) as follows: import pandas as pd comprehend_client = boto3.client("comprehend")
Too many students think that engineering is about getting the answer in the back of the book, not about making the trade-offs that are necessary in the real world. For example in Topic 1, the skills “AWS” and “cloud” map to the job titles cloud engineer, AWS solutions architect, and technology consultant.
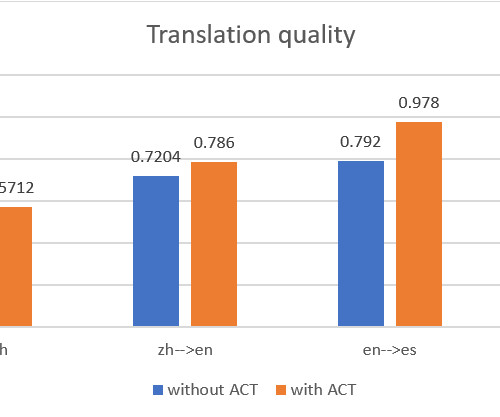
NMT is a deeplearning approach to translation that uses neural networks to learn the patterns of human language and generate translations. Offers seamless integration with other AWS services. Imagine LLMs as really smart translators who have been trained on a mountain of books and articles.
Dive into DeepLearning ( D2L.ai ) is an open-source textbook that makes deeplearning accessible to everyone. It is a challenging endeavor to have an online book that is continuously kept up to date, written by multiple authors, and available in multiple languages. In this post, we present a solution that D2L.ai
It uses advanced deeplearning technologies to accurately transcribe audio into text. The solution presented in this post is orchestrated using an AWS Step Functions state machine that is triggered when you upload a recording to the designated Amazon Simple Storage Service (Amazon S3) bucket.
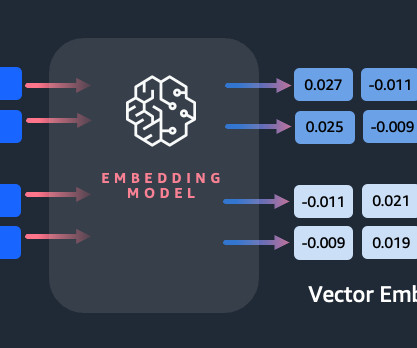
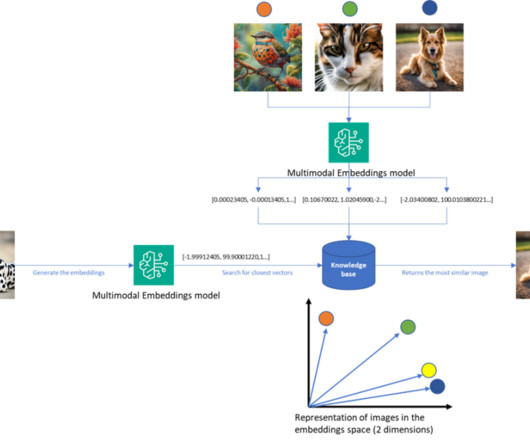
These models are based on deeplearning architectures such as Transformers, which can capture the contextual information and relationships between words in a sentence more effectively. You can use it via either the Amazon Bedrock REST API or the AWS SDK. Why do we need an embeddings model? Nitin Eusebius is a Sr.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Together, these elements lead to the start of a period of dramatic progress in ML, with NN being redubbed deeplearning. Thirdly, the presence of GPUs enabled the labeled data to be processed.
LLMs are large deeplearning models that are pre-trained on vast amounts of data. The solution uses various AWS services to create an end-to-end system that enables field technicians to capture label images, extract data using AI models, verify the accuracy, and seamlessly update the inventory database.
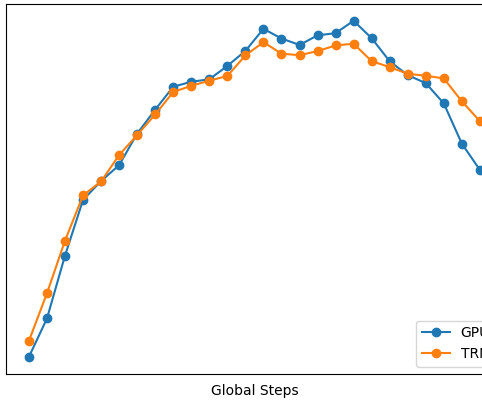
Model training was accelerated by 50% through the use of the SMDDP library, which includes optimized communication algorithms designed specifically for AWS infrastructure. For SageMaker distributed training, the instances need to be in the same AWS Region and Availability Zone. days in AWS vs. 9 days on their legacy platform).
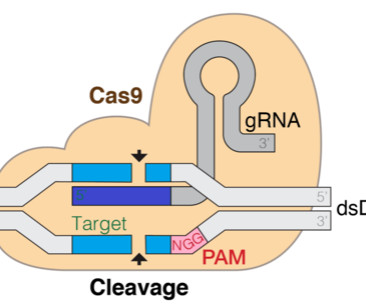
DNABERT 6 Dataset For this post, we use the gRNA data released by researchers in a paper about gRNA prediction using deeplearning. CRISPRon is a CNN based deeplearning model. We also provided code that can help you jumpstart your biology applications in AWS. Yudi Zhang is an Applied Scientist at AWS marketing.
Originating from advancements in artificial intelligence (AI) and deeplearning, these models are designed to understand and translate descriptive text into coherent, aesthetically pleasing music. Obtain the AWSDeepLearning Containers for Large Model Inference from pre-built HuggingFace Inference Containers.
The SMP configuration is as follows: { "hybrid_shard_degree": 16 } To learn more about the advantages of hybrid sharded data parallelism, refer to Near-linear scaling of gigantic-model training on AWS. He leads frameworks, compilers, and optimization techniques for deeplearning training.
When it comes to deploying models on SageMaker endpoints, you can containerize the models using specialized AWSDeepLearning Container (DLC) images available for popular open source libraries. We then identified two approaches for deploying and inferencing Llama 2 Chat models using AWS DLCs—LMI and Hugging Face TGI.
Knowledge Bases for Amazon Bedrock allows you to build performant and customized Retrieval Augmented Generation (RAG) applications on top of AWS and third-party vector stores using both AWS and third-party models. You can also use the StartIngestionJob API to trigger the sync via the AWS SDK.
Solution overview Scalable Capital’s ML infrastructure consists of two AWS accounts: one as an environment for the development stage and the other one for the production stage. To learn more about Hugging Face and SageMaker, refer to the following resources: Use Hugging Face with Amazon SageMaker What are AWSDeepLearning Containers?
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. “We You can deploy the solution in your own AWS account and try the example solution.
If you’ve enjoyed the list of courses at Gen AI 360, wait for this… Today, I am super excited to finally announce that we at towards_AI have released our first book: Building LLMs for Production. This 470-page book is all about LLMs and how to work with them. Good morning, fellow learners. Get your copy now! Our must-read articles 1.
To scale the proposed solution for production and streamline the deployment of AI models in the AWS environment, we demonstrate it using SageMaker endpoints. Prerequisites We have developed an AWS CloudFormation template that will create the SageMaker notebooks used to deploy the endpoints and run inference.
How I cleared AWS Machine Learning Specialty with three weeks of preparation (I will burst some myths of the online exam) How I prepared for the test, my emotional journey during preparation, and my actual exam experience Certified AWS ML Specialty Badge source Introduction:- I recently gave and cleared AWS ML certification on 29th Dec 2022.
About the Authors Abhi Shivaditya is a Senior Solutions Architect at AWS, working with strategic global enterprise organizations to facilitate the adoption of AWS services in areas such as Artificial Intelligence, distributed computing, networking, and storage. Dhawal Patel is a Principal Machine Learning Architect at AWS.
However, as the size and complexity of the deeplearning models that power generative AI continue to grow, deployment can be a challenging task. Then, we highlight how Amazon SageMaker large model inference deeplearning containers (LMI DLCs) can help with optimization and deployment.
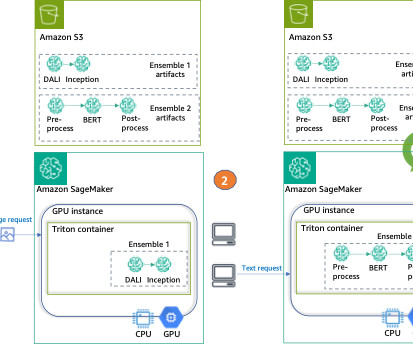
Recent scientific breakthroughs in deeplearning (DL), large language models (LLMs), and generative AI is allowing customers to use advanced state-of-the-art solutions with almost human-like performance. In this post, we show how to run multiple deeplearning ensemble models on a GPU instance with a SageMaker MME.
To remain competitive, capital markets firms are adopting Amazon Web Services (AWS) Cloud services across the trade lifecycle to rearchitect their infrastructure, remove capacity constraints, accelerate innovation, and optimize costs. trillion in assets across thousands of accounts worldwide.
SageMaker JumpStart SageMaker JumpStart serves as a model hub encapsulating a broad array of deeplearning models for text, vision, audio, and embedding use cases. With over 500 models, its model hub comprises both public and proprietary models from AWS’s partners such as AI21, Stability AI, Cohere, and LightOn.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content