This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArtificialIntelligence (AI) is all the rage, and rightly so. The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. There was no easy way to consolidate and analyze this data to more effectively manage our business.
Data lakes and datawarehouses are probably the two most widely used structures for storing data. DataWarehouses and Data Lakes in a Nutshell. A datawarehouse is used as a central storage space for large amounts of structured data coming from various sources. Key Differences.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
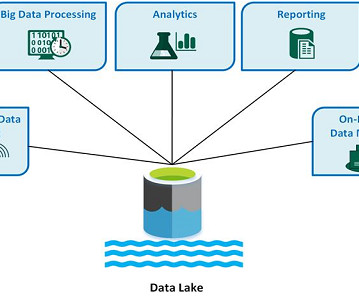
The challenges of a monolithic data lake architecture Data lakes are, at a high level, single repositories of data at scale. Data may be stored in its raw original form or optimized into a different format suitable for consumption by specialized engines.
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a data lake? Snowflake Snowflake is a cross-cloud platform that looks to break down data silos.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
Data science solves a business problem by understanding the problem, knowing the data that’s required, and analyzing the data to help solve the real-world problem. Machine learning (ML) is a subset of artificialintelligence (AI) that focuses on learning from what the data science comes up with.
Earlier this month in London, more than 1,600 data and analytics leaders and professionals gathered for the Gartner Data & Analytics Summit. It was probably a surprise to no one that artificialintelligence (AI) took center stage.
They set up a couple of clusters and began processing queries at a much faster speed than anything they had experienced with Apache Hive, a distributed datawarehouse system, on their data lake. It can ingest data from offline batch data sources (such as Hadoop and flat files) as well as online data sources (such as Kafka).
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like Natural Language Processing (NLP) and machine learning. Many find themselves swamped by the volume and complexity of unstructured data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content