This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. Xinyi Zhou is a Data Engineer at Omron Europe, bringing her expertise to the ODAP team led by Emrah Kaya.
Snowflake’s cloud-agnosticism, separation of storage and compute resources, and ability to handle semi-structured data have exemplified Snowflake as the best-in-class clouddata warehousing solution. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
Key Features Tailored for Data Science These platforms offer specialised features to enhance productivity. Managed services like AWS Lambda and Azure Data Factory streamline datapipeline creation, while pre-built ML models in GCPs AI Hub reduce development time. Below are key strategies for achieving this.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Purina used artificialintelligence (AI) and machine learning (ML) to automate animal breed detection at scale. Tayo Olajide is a seasoned CloudData Engineering generalist with over a decade of experience in architecting and implementing data solutions in cloud environments.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW CloudData Hub (BMW’s data lake on AWS) and on-premises databases. Furthermore, the notebooks can be integrated into the corporate Git repositories to collaborate using version control.
And, they’re still a key element of the infrastructure that makes private clouds possible at many organizations. Instead of performing major surgery on their critical business systems, enterprises are opting for real-time data integration built around inherently reliable and scalable change data capture (CDC) technology.
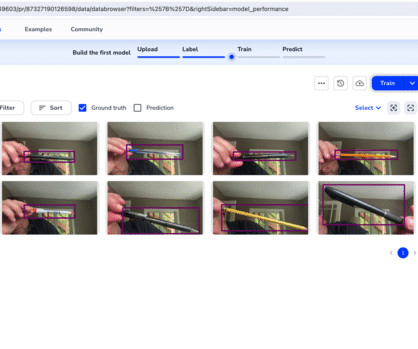
Amazon SageMaker Ground Truth is a fully managed data labeling service that provides flexibility to build and manage custom workflows. With Ground Truth, you can label image, video, and point clouddata for object detection, object tracking, and semantic segmentation tasks.
Data Engineering Summit Our second annual Data Engineering Summit will be in-person for the first time! Like our first Data Engineering Summit , this event will bring together the leading experts in data engineering and thousands of practitioners to explore different strategies for making data actionable.
As enterprise technology landscapes grow more complex, the role of data integration is more critical than ever before. Wide support for enterprise-grade sources and targets Large organizations with complex IT landscapes must have the capability to easily connect to a wide variety of data sources.
This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time. Its open-source nature means it’s continually evolving, thanks to contributions from its user community.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack.
Whatever your approach may be, enterprise data integration has taken on strategic importance. Artificialintelligence (AI) algorithms are trained to detect anomalies. Today’s enterprises need real-time or near-real-time performance, depending on the specific application. Timing matters.
Large manufacturers are starting to use computer vision artificialintelligence (AI) to detect defects cheaper and more efficiently than using human eyes. Detecting product defects can be time-consuming, costly (both for paying people to catch them and if you don’t catch them soon enough), and tedious.
Cloud Adoption Will Continue Steadily Cloud computing and its inherent scalability and elasticity offer distinct advantages, especially with respect to AI/ML and advanced analytics. As clouddata platforms and powerful analytics tools gain in popularity, the march toward the cloud continues at a rapid pace.
Whatever your approach may be, enterprise data integration has taken on strategic importance. Artificialintelligence (AI) algorithms are trained to detect anomalies. Today’s enterprises need real-time or near-real-time performance, depending on the specific application. Timing matters.
Real-time analytics and BI: Combine data from existing sources with new data to unlock new, faster insights without the cost and complexity of duplicating and moving data across different environments. The post Exploring the AI and data capabilities of watsonx appeared first on IBM Blog.
Talend Talend is a leading open-source ETL platform that offers comprehensive solutions for data integration, data quality , and clouddata management. It supports both batch and real-time data processing , making it highly versatile. It is well known for its data provenance and seamless data routing capabilities.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse.
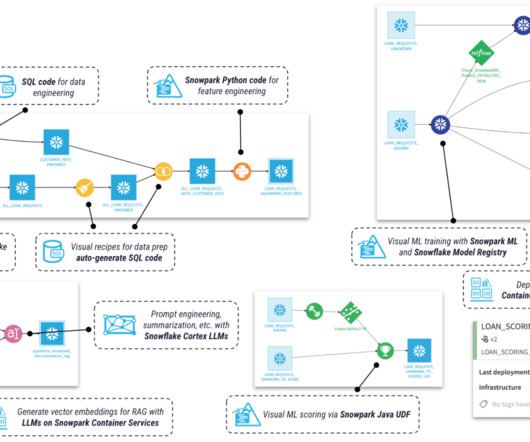
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content