This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
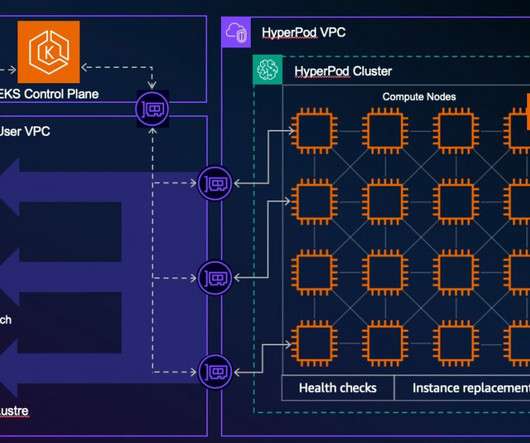
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
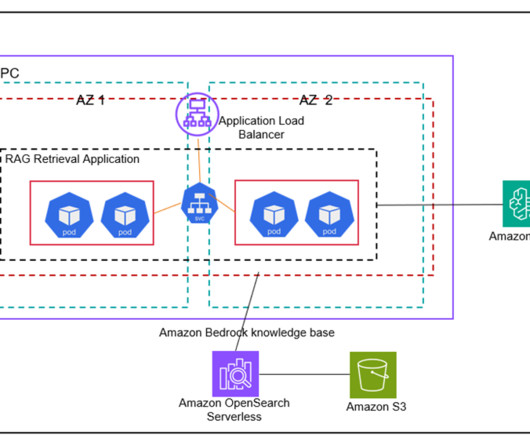
Generative artificialintelligence (AI) applications are commonly built using a technique called Retrieval Augmented Generation (RAG) that provides foundation models (FMs) access to additional data they didnt have during training. Install the AWS Command Line Interface (AWS CLI). Sonnet on Amazon Bedrock. Install Docker.
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
Amazon Web Services (AWS) provides the essential compute infrastructure to support these endeavors, offering scalable and powerful resources through Amazon SageMaker HyperPod. Midway through 2023, we saw the next wave of climate tech startups building sophisticated intelligent assistants by fine-tuning existing LLMs for specific use cases.
At ByteDance, we collaborated with Amazon Web Services (AWS) to deploy multimodal large language models (LLMs) for video understanding using AWS Inferentia2 across multiple AWS Regions around the world. Solution overview Weve collaborated with AWS since the first generation of Inferentia chips.
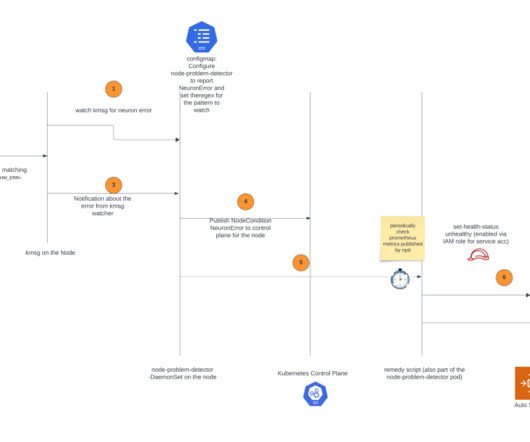
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). eks-5e0fdde Install the required AWS Identity and Access Management (IAM) role for the service account and the node problem detector plugin.
Solution overview Implementing the solution consists of the following high-level steps: Set up your environment and the permissions to access Amazon HyperPod clusters in SageMaker Studio. You can now use SageMaker Studio to discover the SageMaker HyperPod clusters, and view cluster details and metrics.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Responsibility for maintenance and troubleshooting: Rockets DevOps/Technology team was responsible for all upgrades, scaling, and troubleshooting of the Hadoop cluster, which was installed on bare EC2 instances.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deep learning frameworks.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
Recognizing the transformative benefits of generative AI for enterprises, we at Hexagons Asset Lifecycle Intelligence division sought to enhance how users interact with our Enterprise Asset Management (EAM) products. We finalized the following architecture to serve our technical needs.
AWS was delighted to present to and connect with over 18,000 in-person and 267,000 virtual attendees at NVIDIA GTC, a global artificialintelligence (AI) conference that took place March 2024 in San Jose, California, returning to a hybrid, in-person experience for the first time since 2019.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. Surya Kari is a Senior Generative AI Data Scientist at AWS.
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. A Ray cluster consists of a single head node and a number of connected worker nodes. Ray clusters and Kubernetes clusters pair well together.
Amazon Web Services (AWS) is committed to supporting the development of cutting-edge generative artificialintelligence (AI) technologies by companies and organizations across the globe. Let’s dive in and explore how these organizations are transforming what’s possible with generative AI on AWS.
It also comes with ready-to-deploy code samples to help you get started quickly with deploying GeoFMs in your own applications on AWS. For a full architecture diagram demonstrating how the flow can be implemented on AWS, see the accompanying GitHub repository. Lets dive in! Solution overview At the core of our solution is a GeoFM.
At AWS, we have played a key role in democratizing ML and making it accessible to anyone who wants to use it, including more than 100,000 customers of all sizes and industries. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
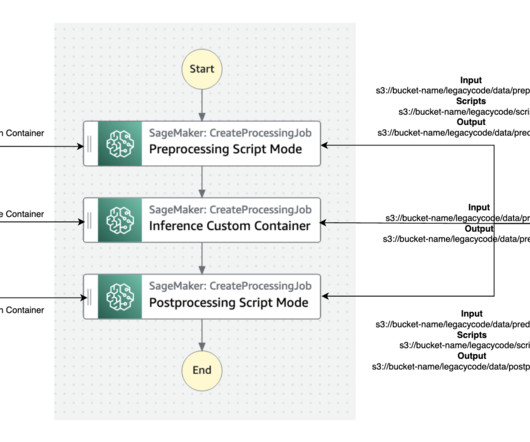
We demonstrate this solution by walking you through a comprehensive step-by-step guide on how to fine-tune YOLOv8 , a real-time object detection model, on Amazon Web Services (AWS) using a custom dataset. You can train foundation models (FMs) for weeks and months without disruption by automatically monitoring and repairing training clusters.
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
With HyperPod, users can begin the process by connecting to the login/head node of the Slurm cluster. You can execute each step in the training pipeline by initiating the process through the SageMaker control plane using APIs, AWS Command Line Interface (AWS CLI), or the SageMaker ModelTrainer SDK.
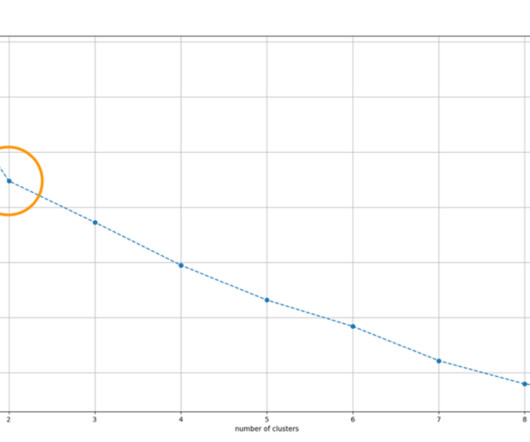
As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. Larger clusters, more failures, smaller MTBF As cluster size increases, the entropy of the system increases, resulting in a lower MTBF. It implies that if a single instance fails, it stops the entire job.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise.
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container , an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS). The Container Insights dashboard also shows cluster status and alarms.
NinjaTech AI’s mission is to make everyone more productive by taking care of time-consuming complex tasks with fast and affordable artificialintelligence (AI) agents. In this post, we describe how we built our cutting-edge productivity agent NinjaLLM, the backbone of MyNinja.ai, using AWS Trainium chips. MyNinja.ai
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Large language models (LLMs) are making a significant impact in the realm of artificialintelligence (AI). Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart.
Close collaboration with AWS Trainium has also played a major role in making the Arcee platform extremely performant, not only accelerating model training but also reducing overall costs and enforcing compliance and data integrity in the secure AWS environment. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge
Each of these products are infused with artificialintelligence (AI) capabilities to deliver exceptional customer experience. During this journey, we collaborated with our AWS technical account manager and the Graviton software engineering teams.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificialintelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. The data scientist is responsible for moving the code into SageMaker, either manually or by cloning it from a code repository such as AWS CodeCommit.
Prerequisites To use the methods presented in this post, you need an AWS account with access to Amazon SageMaker , Amazon Bedrock , and Amazon Simple Storage Service (Amazon S3). Statement: 'AWS is Amazon subsidiary that provides cloud computing services.' Finally, we compare approaches in terms of their performance and latency.
Integration with existing systems on AWS: Lumi seamlessly integrated SageMaker Asynchronous Inference endpoints with their existing loan processing pipeline. Using Databricks on AWS for model training, they built a pipeline to host the model in SageMaker AI, optimizing data flow and results retrieval. Follow him on LinkedIn.
How to create an artificialintelligence? The creation of artificialintelligence (AI) has long been a dream of scientists, engineers, and innovators. Understanding artificialintelligence Before diving into the process of creating AI, it is important to understand the key concepts and types of AI.
It is used by businesses across industries for a wide range of applications, including fraud prevention, marketing automation, customer service, artificialintelligence (AI), chatbots, virtual assistants, and recommendations. It provides a large cluster of clusters on a single machine.
CBRE is unlocking the potential of artificialintelligence (AI) to realize value across the entire commercial real estate lifecycle—from guiding investment decisions to managing buildings. AWS Prototyping developed an AWS Cloud Development Kit (AWS CDK) stack for deployment following AWS best practices.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. IAM roles : Assign appropriate AWS Identity and Access Management (IAM) roles to the tasks for accessing other AWS resources securely.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content