This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Predicting the elections, however, presents challenges unique to it, such as the dynamic nature of voter preferences, non-linear interactions, and latent biases in the data. The points to cover in this article are as follows: Generating synthetic data to illustrate ML modelling for election outcomes.
🤪 If you are like me, needing to write in multiple data-wrangling packages, including pySpark, and want to make life easier, this article is just for you! This practice vastly enhances the speed of my datapreparation for machine learning projects. within each project folder. Let’s get started.
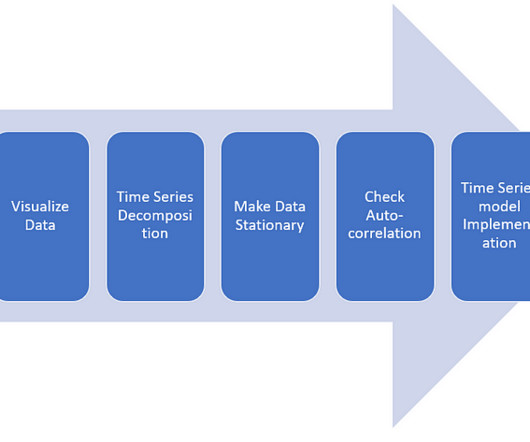
Please refer to Part 1– to understand what is Sales Prediction/Forecasting, the Basic concepts of Time series modeling, and EDA I’m working on Part 3 where I will be implementing Deep Learning and Part 4 where I will be implementing a supervised ML model. DataPreparation — Collect data, Understand features 2.
In general, the results of current journal articles on AI (even peer-reviewed) are irreproducible. Datapreparation: This step includes the following tasks: data preprocessing, data cleaning, and exploratory data analysis (EDA). 85% or more of AI projects fail [1][2].
” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape. The magic of “What does a data scientist do?”
Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. Data Science and Data Analysis play pivotal roles in today’s digital landscape. This article will explore these cycles, from data acquisition to deployment and monitoring.
You have to learn only those parts of technology that are useful in data science as well as help you land a job. Don’t worry; you have landed at the right place; in this article, I will give you a crystal clear roadmap to learning data science. Because this is the only effective way to learn Data Analysis.
A small portion of the LLM ecosystem; image from scalevp.com In this article, we will provide a comprehensive guide to training, deploying, and improving LLMs. In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning.
The inferSchema parameter is set to True to infer the data types of the columns, and header is set to True to use the first row as headers. For a comprehensive understanding of the practical applications, including a detailed code walkthrough from datapreparation to model deployment, please join us at the ODSC APAC conference 2023.
In this article, I will share my learnings of how successful ML platforms work in an eCommerce and what are the best practices a Team needs to follow during the course of building it. The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring.
An ETL process was built to take the CSV, find the corresponding text articles and load the data into a SQLite database. The text is then broken down into sentences per document, and those sentences are mapped to sentence embeddings using a BM25 + fastText method described in this Medium article.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content