This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Mechanics of data virtualization Understanding how data virtualization works reveals its benefits in organizations. Middleware role Data virtualization often functions as middleware that bridges various datamodels and repositories, including cloud datalakes and on-premise warehouses.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
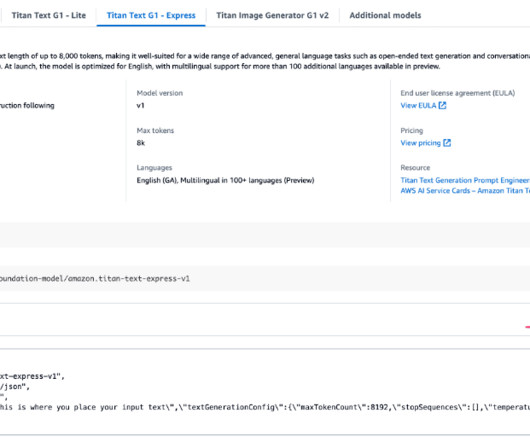
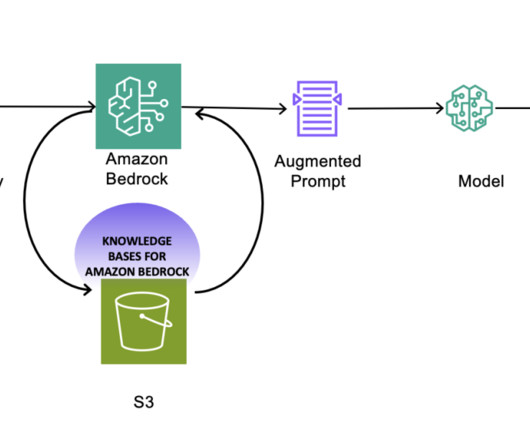
For example, if you’re asking the FM for an article or story, you might want to stream the output of the generated content. Import the dependencies and create the Amazon Bedrock client: import boto3, json bedrock_runtime = boto3.client( Import the dependencies and create the Amazon Bedrock client: import boto3, json bedrock_runtime = boto3.client(
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
Article on Azure ML by Bethany Jepchumba and Josh Ndemenge of Microsoft In this article, I will cover how you can train a model using Notebooks in Azure Machine Learning Studio. At the end of this article, you will learn how to use Pytorch pretrained DenseNet 201 model to classify different animals into 48 distinct categories.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
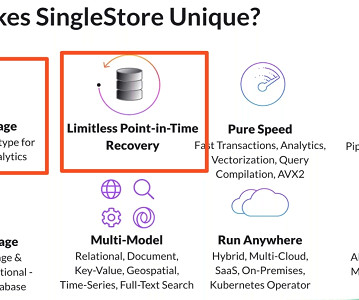
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how datamodels and algorithms rely on powerful and versatile data infrastructure.
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. No-code/low-code experience using a diagram view in the data preparation layer similar to Dataflows.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. million by 2028.
Staffed by experienced enterprise professionals with an average of nearly 25 tenure years, Precisely Strategic Services is proud to have earned a reputation as a top-tier data-centric management consulting organization. This article offers a few examples that illustrate some of the most popular use cases for data-driven strategic services.
In this article, we want to dig deeper into the fundamentals of machine learning as an engineering discipline and outline answers to key questions: Why does ML need special treatment in the first place? ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses.
The traditional data science workflow , as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps: Ask a question. Get the data. Explore the data. Model the data. A data catalog can assist directly with every step, but model development.
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like Natural Language Processing (NLP) and machine learning. Many find themselves swamped by the volume and complexity of unstructured data.
AWS offers a GDPR-compliant AWS Data Processing Addendum (AWS DPA), which helps you to comply with GDPR contractual obligations. The AWS DPA is incorporated into the AWS Service Terms. Krishna Prasad is a Senior Solutions Architect in Strategic Accounts Solutions Architecture team at AWS.
As you delve into the landscape of MLOps in 2023, you will find a plethora of tools and platforms that have gained traction and are shaping the way models are developed, deployed, and monitored. Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you render audio/video?
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. How to properly manage unstructured data.
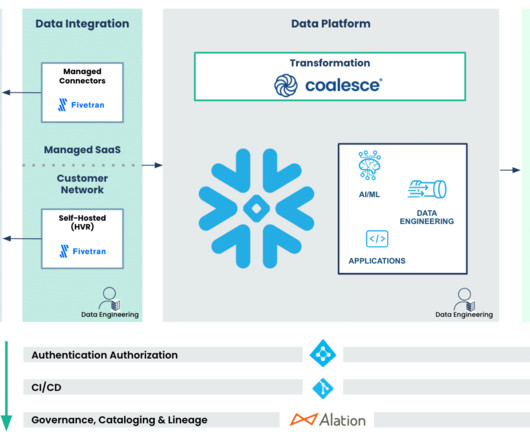
This article was co-written by Justin Delisi & Sam Hall. Simple Data and Infrastructure Management Snowflake separates compute from storage, automatically scaling up or down instantly and independently based on your needs. Additionally, change data markers are not available for many of these tables.
This announcement is interesting and causes some of us in the tech industry to step back and consider many of the factors involved in providing data technology […]. The post Where Is the Data Technology Industry Headed? Click here to learn more about Heine Krog Iversen.
However, most enterprises are hampered by data strategies that leave teams flat-footed when […]. The post Why the Next Generation of Data Management Begins with Data Fabrics appeared first on DATAVERSITY. Click to learn more about author Kendall Clark. The mandate for IT to deliver business value has never been stronger.
Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. They offer a variety of services, including data warehousing, datalakes, and machine learning. ArangoDB ArangoDB is a company that provides a database platform for graph and document data.
In this article, you’ll discover what a Snowflake data warehouse is, its pros and cons, and how to employ it efficiently. The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. What makes Snowflake so unique, and are there any caveats to it?
They are interesting to an extent, but mostly, they feel like a late-night re-run and remind me that data work is hard. If you haven’t heard about metrics stores yet, they’re “newish,” so you likely will. So, what is a metrics store? Most of the young vendors trying to create this category will tell you that […]
A collection of facts from which inferences can be made is called data. Data is the cornerstone of contemporary society and is crucial to many facets of people’s lives. In order to gain knowledge and make wise decisions, […] The post Data Provisioning: Ingest, Curate, and Publish appeared first on DATAVERSITY.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage.
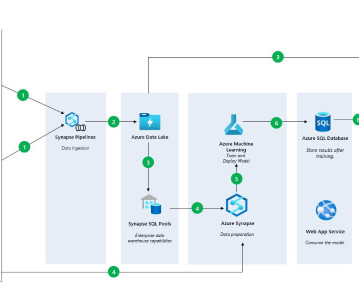
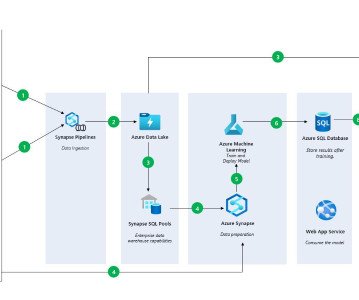
It lets them focus more on deploying new models than maintaining existing ones. It provides the ability to focus on new models instead of putting too much effort into maintaining existing models. In this article, you will: 1 Explore what the architecture of an ML pipeline looks like, including the components.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content