This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark). such data resources are cleaned, transformed, and analyzed by using tools like Python, R, SQL, and big data technologies such as Hadoop and Spark.
They pop up in news articles, job descriptions, and tech discussions. Big Data technologies include Hadoop, Spark, and NoSQL databases. Big Data Technologies Enable Data Science at Scale Tools like Hadoop and Spark were developed specifically to handle the challenges of Big Data. It can be confusing! What exactly is Big Data?
Commonly used technologies for data storage are the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage, as well as tools like Apache Hive, Apache Spark, and TensorFlow for data processing and analytics. Contact: kai.waehner@confluent.io / Twitter / LinkedIn.
John Deighton recently posted about this in an article on The Economic Times. Google’s Hadoop allowed for unlimited data storage on inexpensive servers, which we now call the Cloud. Big data has led to some huge changes in the way we live. John Deighton is a leading expert on big data technology.
This article helps you choose the right path by exploring their differences, roles, and future opportunities. Big data platforms such as Apache Hadoop and Spark help handle massive datasets efficiently. They must also stay updated on tools such as TensorFlow, Hadoop, and cloud-based platforms like AWS or Azure.
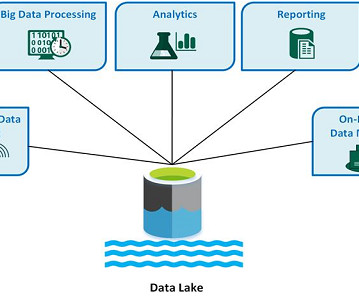
Hadoop, Snowflake, Databricks and other products have rapidly gained adoption. In this article, we’ll focus on a data lake vs. data warehouse. Apache Hadoop, for example, was initially created as a mechanism for distributed storage of large amounts of information. Other platforms defy simple categorization, however.
Microsoft’s Azure Data Lake The Azure Data Lake is considered to be a top-tier service in the data storage market. Amazon Web Services Similar to Azure, Amazon Simple Storage Service is an object storage service offering scalability, data availability, security, and performance.
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. Among these tools, Apache Hadoop, Apache Spark, and Apache Kafka stand out for their unique capabilities and widespread usage. million by 2028.
This article will serve as an ultimate guide to choosing between Data Science and Data Analytics. At the end of this article, you will fully understand what it entails to be a data scientist or data analyst. Before going into the main purpose of this article, what is data? Experience with cloud platforms like; AWS, AZURE, etc.
This article compares Tableau and Power BI, examining their features, pricing, and suitability for different organisations. This article will guide readers in selecting the right BI tool—Tableau or Power BI—for their needs in 2024. Tableau supports integrations with third-party tools, including Salesforce, Hadoop, and Google Analytics.
This article explores the top 10 AI jobs in India and the essential skills required to excel in these roles. Key Skills Experience with cloud platforms (AWS, Azure). Hadoop , Apache Spark ) is beneficial for handling large datasets effectively. India’s AI talent pool is expected to grow over 1.25 million by 2027.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Big Data Technologies: Hadoop, Spark, etc. Big Data Processing: Apache Hadoop, Apache Spark, etc.
This article endeavors to alleviate those confusions. This is an architecture that’s well suited for the cloud since AWS S3 or Azure DLS2 can provide the requisite storage. Multiple products exist in the market, including Databricks, Azure Synapse and Amazon Athena. The concepts and values are overlapping. It can be codified.
This article will discuss managing unstructured data for AI and ML projects. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. Apache Hadoop Apache Hadoop is an open-source framework that supports the distributed processing of large datasets across clusters of computers.
In this article, we’ll explore how Comet can be useful for training, developing, and deploying large-scale machine learning models. In this stage, the language model is trained on a large corpus of text, such as news articles, books, or web pages, to learn the patterns and structures of natural language.
In this article, we will discuss the importance of data versioning control in machine learning and explore various methods and tools for implementing it with different types of data sources. It supports most major cloud providers, such as AWS, GCP, and Azure. The remote repository can be on the same computer, or it can be on the cloud.
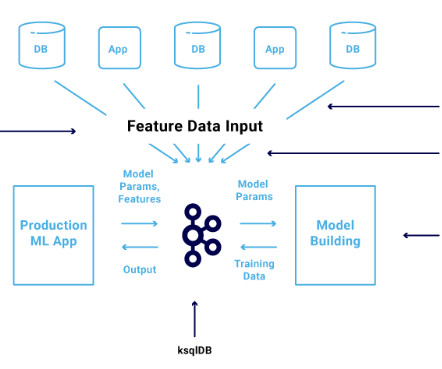
In this article, I will share my learnings of how successful ML platforms work in an eCommerce and what are the best practices a Team needs to follow during the course of building it. Final thoughts This article covered the major components of an ML platform and how to build them for an eCommerce business. But how to build it?
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. Platforms like Azure Data Lake and AWS Lake Formation can facilitate big data and AI processing.
All the clouds are different, and for us GCP offers some cool benefits that we will highlight in this article vs the AWS AI Services or Azure Machine Learning. Dataproc Process large datasets with Spark and Hadoop before feeding them into your ML pipeline. What Exactly is GCP AI Platform?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content