This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
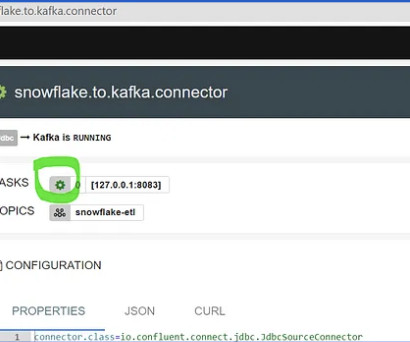
You can safely use an ApacheKafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. Without data engineering , companies would struggle to analyse information and make informed decisions. What Does a Data Engineer Do?
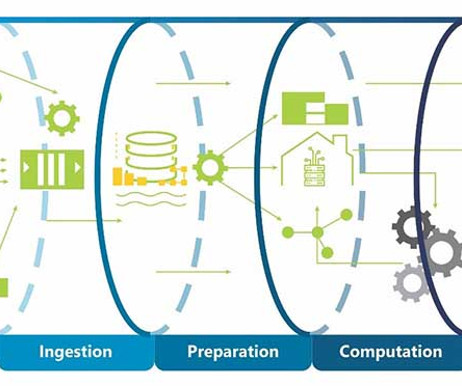
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. Big data pipelines operate similarly to traditional ETL (Extract, Transform, Load) pipelines but are designed to handle much larger data volumes.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. What is ApacheKafka, and How is it Used in Building Real-time Data Pipelines? ApacheKafka is an open-source event distribution platform. Example: openssl rsa -in C:tmpnew_rsa_key_v1.p8
This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. From extracting information from databases and spreadsheets to ingesting streaming data from IoT devices and social media platforms, It’s the foundation upon which data-driven initiatives are built.
Thomson Reuters (TR) is one of the world’s most trusted information organizations for businesses and professionals. TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. ETL Design Pattern Here is an example of how the ETL design pattern can be used in a real-world scenario: A healthcare organization wants to analyze patient data to improve patient outcomes and operational efficiency.
The goal is to ensure that data is available, reliable, and accessible for analysis, ultimately driving insights and informed decision-making within organisations. Their work ensures that data flows seamlessly through the organisation, making it easier for Data Scientists and Analysts to access and analyse information.
Overview In the era of Big Data , organizations inundated with vast amounts of information generated from various sources. Apache NiFi, an open-source data ingestion and distribution platform, has emerged as a powerful tool designed to automate the flow of data between systems. How Does Apache NiFi Ensure Data Integrity?
It covers best practices for ensuring scalability, reliability, and performance while addressing common challenges, enabling businesses to transform raw data into valuable, actionable insights for informed decision-making. They facilitate the seamless flow of information from diverse sources to actionable insights.
This involves working closely with data analysts and data scientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making. With the rise of big data, data engineering has become critical for organizations looking to make sense of the vast amounts of information at their disposal.
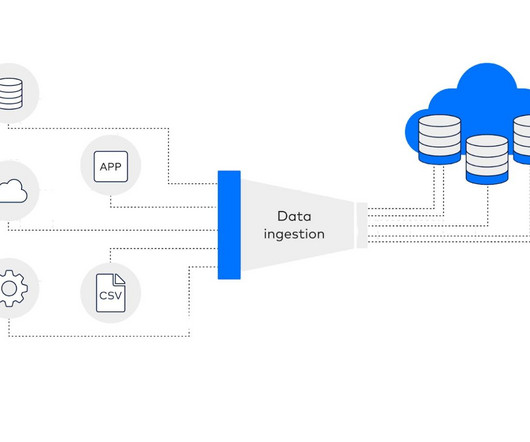
Real-time data ingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions. What is Real-Time Data Ingestion?
One thing is clear : unstructured data doesn’t mean it lacks information. All forms of data must have some form of information, or else they won’t be considered data. Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information.
Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions. Pricing It is free to use and is licensed under Apache License Version 2.0. This is what data processing pipelines do for you.
Organisations must develop strategies to store and manage this vast amount of information effectively. Data Integration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis. Knowledge of RESTful APIs and authentication methods is essential.
Before you start looking into the specific tools, you can find a summary table containing the most important information on the covered orchestration tool. Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines.
Instead of trying to build a perfect, complete customer model from the get-go, it starts with small, standardized pieces of information – let’s call them data atoms (or atomic data). Think of it as the smallest, indivisible unit of customer information. Rich Context: Each event carries with it a wealth of contextual information.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content