
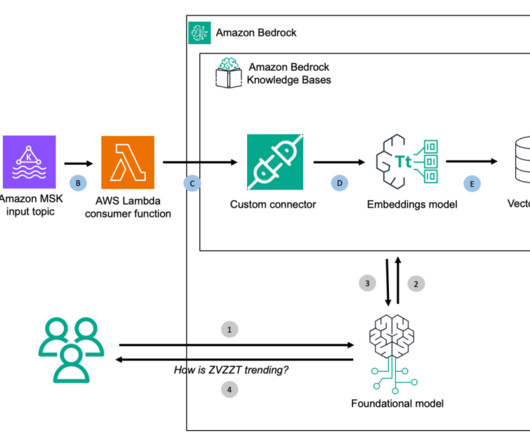
Stream ingest data from Kafka to Amazon Bedrock Knowledge Bases using custom connectors
AWS Machine Learning Blog
APRIL 18, 2025
This feature chunks and converts input data into embeddings using your chosen Amazon Bedrock model and stores everything in the backend vector database. Amazon MSK is a streaming data service that manages Apache Kafka infrastructure and operations, making it straightforward to run Apache Kafka applications on Amazon Web Services (AWS).










Let's personalize your content