This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dale Carnegie” ApacheKafka is a Software Framework for storing, reading, and analyzing streaming data. The Internet of Things(IoT) devices can generate a large […]. The post Build a Simple Realtime Data Pipeline appeared first on Analytics Vidhya. We learn by doing.
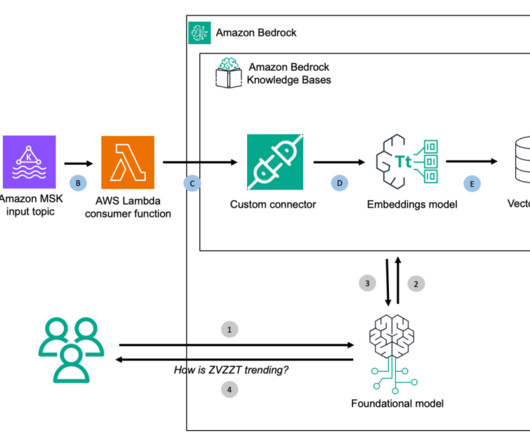
Through this capability, Amazon Bedrock Knowledge Bases supports the ingestion of streaming data, which means developers can add, update, or delete data in their knowledge base through direct API calls. The solution enables real-time analysis of customer feedback through vector embeddings and large language models (LLMs).
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
The machine learning model is part of the Stream processing engine, and it provides the logic that helps the streaming data pipeline expose features within the stream and potentially within a historical data store. It can be used to collect, store, and process streaming data in real-time.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content