This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
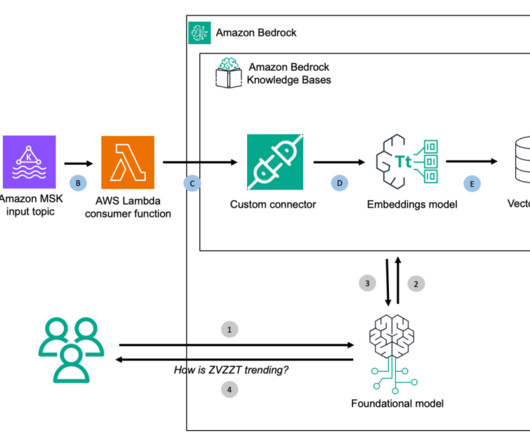
This feature chunks and converts input data into embeddings using your chosen Amazon Bedrock model and stores everything in the backend vector database. Amazon MSK is a streaming data service that manages ApacheKafka infrastructure and operations, making it straightforward to run ApacheKafka applications on Amazon Web Services (AWS).
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
Within this article, we will explore the significance of these pipelines and utilise robust tools such as ApacheKafka and Spark to manage vast streams of data efficiently. ApacheKafkaApacheKafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications.
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Available Service information One or more regions affected Products Americas (regions) Europe (regions) Asia Pacific (regions) Middle East (regions) Africa (regions) Multi-regions Global Access Approval Access Context Manager Access Transparency Agent Assist AI Platform Prediction AI Platform Training AlloyDB for PostgreSQL Anthos Service Mesh API (..)
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., Clusters : Clusters are groups of interconnected nodes that work together to process and store data.
ApacheKafka is a well-known open-source event store and stream processing platform and has grown to become the de facto standard for data streaming. ApacheKafka transfers data without validating the information in the messages. What is a schema registry? A schema registry also validates evolution of schemas.
However, it lacked essential services required for machine learning (ML) applications, such as frontend and backend infrastructure, DNS, load balancers, scaling, blob storage, and managed databases. At that time, the application was deployed as a single monolithic container, which included Kafka and a database.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Statistics Kafka handles over 1.1
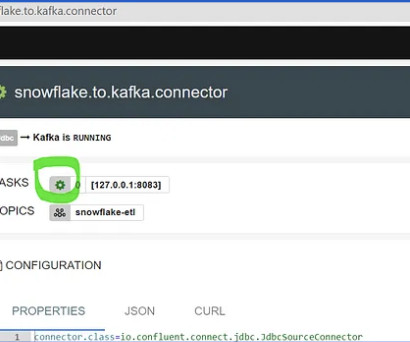
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka. Looking for additional help?
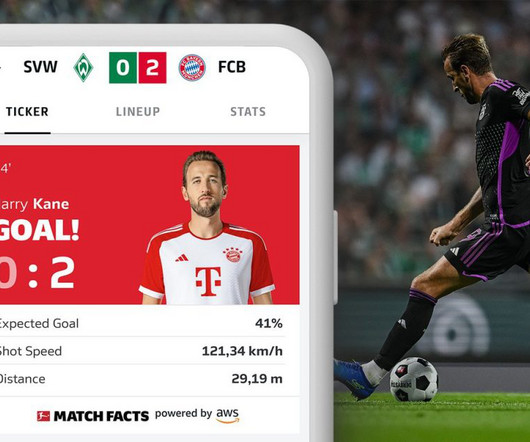
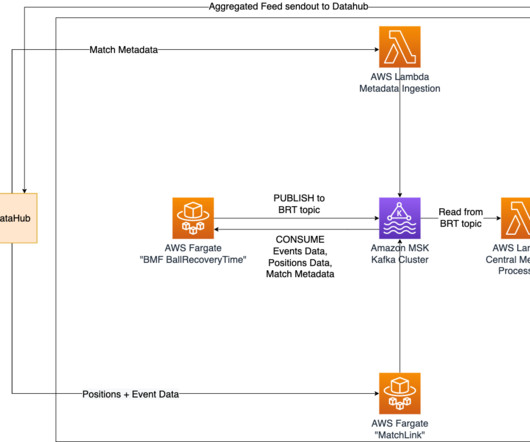
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. km/h with a distance to goal of 20.61
Processing frameworks like Hadoop enable efficient data analysis across clusters. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). What is a Data Lake, And How Does It Differ from a Traditional Database? What is Big Data?
Processing frameworks like Hadoop enable efficient data analysis across clusters. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). What is a Data Lake, And How Does It Differ from a Traditional Database? What is Big Data?
Variety Data comes in multiple forms, from highly organised databases to messy, unstructured formats like videos and social media text. Structured data is organised in tabular formats like databases, while unstructured data, such as images or videos, lacks a predefined format. Explain the Role of Apache HBase.
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. Additionally, the ball recovery times are sent to a specific topic in the MSK cluster, where they can be accessed by other Bundesliga Match Facts.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database. The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub.
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). Understanding the differences between SQL and NoSQL databases is crucial for students. Once data is collected, it needs to be stored efficiently.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Scalability : NiFi can be deployed in a clustered environment, enabling organizations to scale their data processing capabilities as their data needs grow. It can connect to various database s, file systems, and cloud storage solutions, enabling seamless data transfer without significant downtime.
This involves working with various data storage technologies, such as databases and data warehouses, and ensuring that the data is easily accessible and can be analyzed efficiently. Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data.
Typical examples include: Airbyte Talend ApacheKafkaApache Beam Apache Nifi While getting control over the process is an ideal position an organization wants to be in, the time and effort needed to build such systems are immense and frequently exceeds the license fee of a commercial offering. Talend Free to use.
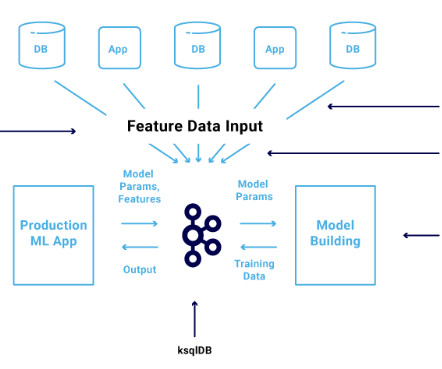
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., The exploration of common machine learning pipeline architecture and patterns starts with a pattern found in not just machine learning systems but also database systems, streaming platforms, web applications, and modern computing infrastructure. 1 Data Ingestion (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content