
Building the future of construction analytics: CONXAI’s AI inference on Amazon EKS
AWS Machine Learning Blog
FEBRUARY 7, 2025
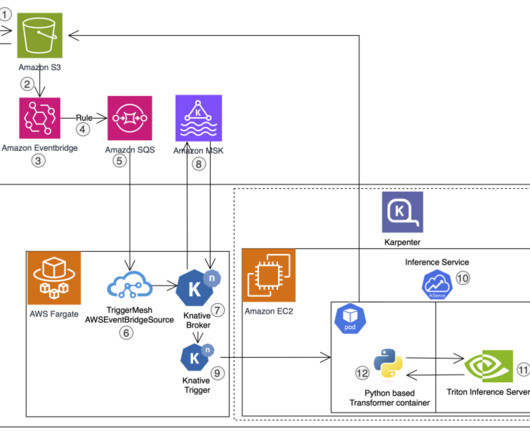
It is backed by Amazon Managed Streaming for Apache Kafka (Amazon MSK) (8). The transformer gets a CloudEvent with the reference of the image Amazon S3 path, downloads it, and performs model inference over HTTP. The resources in the Kubernetes cluster are deployed in a private subnet.










Let's personalize your content