This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Best Big Data Tools Popular tools such as ApacheHadoop, Apache Spark, Apache Kafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Use Cases : Yahoo!
The Rise of Augmented Analytics Augmented analytics is revolutionizing how data insights are generated by integrating artificial intelligence (AI) and machine learning (ML) into analytics workflows. Over 77% of AI-related job postings now require machine learning expertise, reflecting its critical role in data science jobs.
Business Analytics requires business acumen; Data Science demands technical expertise in coding and ML. Big data platforms such as ApacheHadoop and Spark help handle massive datasets efficiently. They must also stay updated on tools such as TensorFlow, Hadoop, and cloud-based platforms like AWS or Azure.
With Amazon EMR, which provides fully managed environments like ApacheHadoop and Spark, we were able to process data faster. SageMaker pipeline for training SageMaker Pipelines helps you define the steps required for ML services, such as preprocessing, training, and deployment, using the SDK.
Check out this course to build your skillset in Seaborn — [link] Big Data Technologies Familiarity with big data technologies like ApacheHadoop, Apache Spark, or distributed computing frameworks is becoming increasingly important as the volume and complexity of data continue to grow. in these fields.
Managing unstructured data is essential for the success of machine learning (ML) projects. This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to properly manage unstructured data.
One popular example of the MapReduce pattern is ApacheHadoop, an open-source software framework used for distributed storage and processing of big data. Hadoop provides a MapReduce implementation that allows developers to write applications that process large amounts of data in parallel across a cluster of commodity hardware.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and ApacheHadoop.
Proficiency in ML is understood when these are not just present in the aspirant in conceptual ways but also in terms of its applications in solving business problems. Machine Learning: Data Science aspirants need to have a good and concise understanding on Machine Learning algorithms including both supervised and unsupervised learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


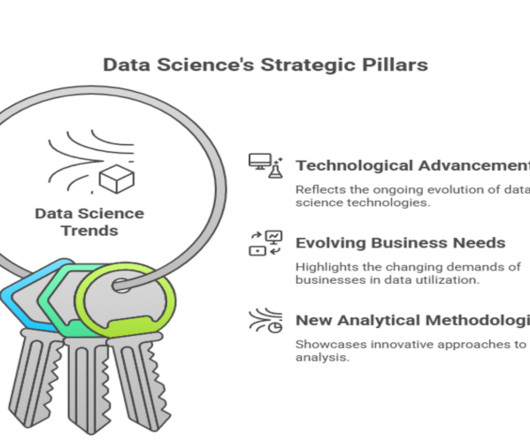

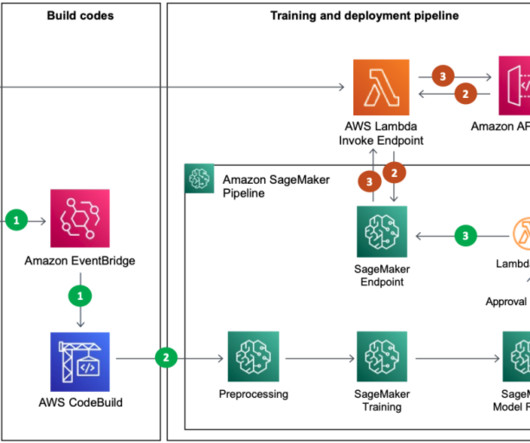




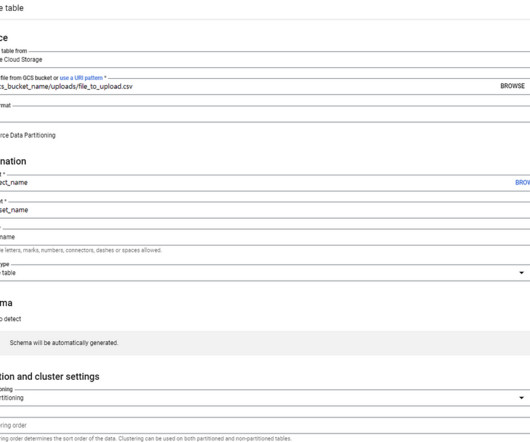

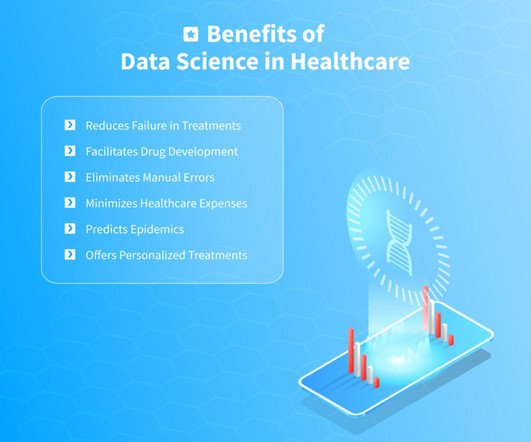






Let's personalize your content