

Big data management
Dataconomy
MAY 26, 2025
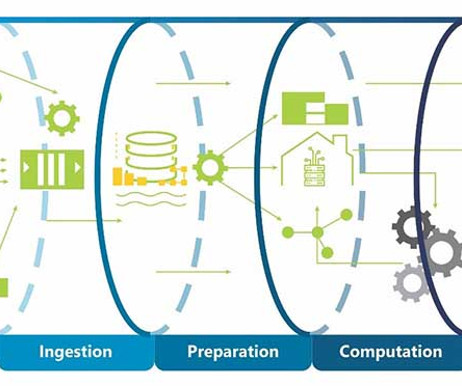
As businesses increasingly rely on data to drive strategies and decisions, effective management of this information becomes essential for achieving competitive advantage and insights. Platforms and tools Organizations often rely on advanced tools such as Apache Hadoop and Apache Spark to streamline data handling.















Let's personalize your content