This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Virginia Tech and Microsoft unveil the Algorithm of Thoughts, a breakthrough AI method supercharging idea exploration and reasoning prowess in Large Language Models (LLMs). Moreover, these approaches integrate external processes to influence token generation by modifying the contextual information.
In machine learning, few ideas have managed to unify complexity the way the periodic table once did for chemistry. Now, researchers from MIT, Microsoft, and Google are attempting to do just that with I-Con, or Information Contrastive Learning. A state-of-the-art image classification algorithm requiring zero human labels.
Zero-shot, one-shot, and few-shot learning are redefining how machines adapt and learn, promising a future where adaptability and generalization reach unprecedented levels. Source: Photo by Hal Gatewood on Unsplash In this exploration, we navigate from the basics of supervisedlearning to the forefront of adaptive models.
Summary: Machine Learningalgorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learningalgorithms.
Self-supervisedlearning (SSL) has emerged as a powerful technique for training deep neural networks without extensive labeled data. However, unlike supervisedlearning, where labels help identify relevant information, the optimal SSL representation heavily depends on assumptions made about the input data and desired downstream task.
Human-in-the-loop machine learning is a methodology that emphasizes the critical role of human feedback in the machine learning lifecycle. Instead of relying solely on automated algorithms, HITL processes involve human experts to validate, refine, and augment the learning models.
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world.
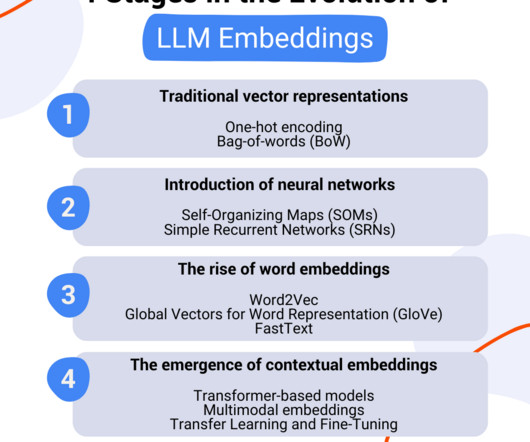
Stage 2: Introduction of neural networks The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
A keen awareness of where a model lies on the bias-variance spectrum can lead to more informed decisions during the modeling process. Types of errors in machine learning Beyond bias and variance, specific types of errors characterize model performance issues. What is underfitting?
Linear regression stands out as a foundational technique in statistics and machine learning, providing insights into the relationships between variables. This method enables analysts and practitioners to create predictive models that can inform decision-making across many fields. What is linear regression?
They dive deep into artificial neural networks, algorithms, and data structures, creating groundbreaking solutions for complex issues. These professionals venture into new frontiers like machine learning, natural language processing, and computer vision, continually pushing the limits of AI’s potential.
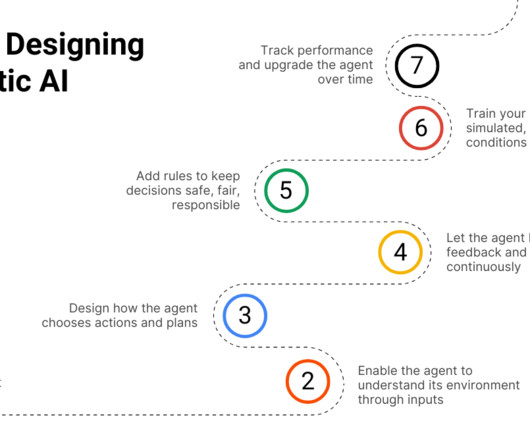
It takes in data, makes sense of it, and uses that information to plan its next move. Its about creating AI that does not just do, but thinks, learns, and acts on its own. By basing decisions on data and algorithms rather than gut feelings, businesses can reduce the influence of bias in critical systems.
The world of multi-view self-supervisedlearning (SSL) can be loosely grouped into four families of methods: contrastive learning, clustering, distillation/momentum, and redundancy reduction. This work not only brings new theoretical insights but also introduces practical tools to optimize self-supervised models.
Unsupervised learning is a fascinating area within machine learning that uncovers hidden patterns in data without the need for pre-labeled examples. By allowing algorithms to learn autonomously, it opens the door to various innovative applications across different fields. What is unsupervised learning?
Stage 2: Introduction of neural networks The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
Accordingly, Machine Learning allows computers to learn and act like humans by providing data. Apparently, ML algorithms ensure to train of the data enabling the new data input to make compelling predictions and deliver accurate results. Therefore, SupervisedLearning vs Unsupervised Learning is part of Machine Learning.
In their quest for effectiveness and well-informed decision-making, businesses continually search for new ways to collect information. QR codes can contain a huge amount of information, such as text, URLs, contact details, and more. In the realm of AI and ML, QR codes find diverse applications across various domains.
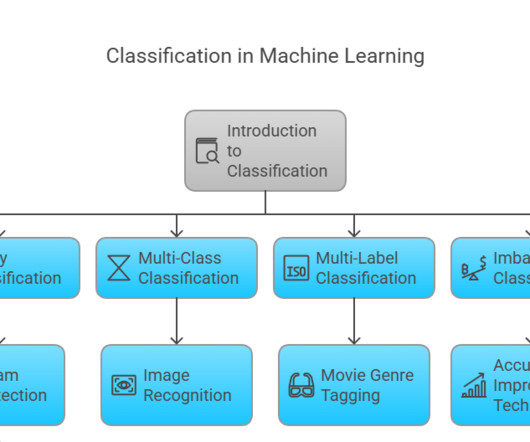
Binary classification is a supervisedlearning method designed to categorize data into one of two possible outcomes. Overview of classification in machine learning Classification serves as a foundational method in machine learning, where algorithms are trained on labeled datasets to make predictions.
Currently, hand-crafted compression algorithms, often designed for general image data like JPEG2000, are applied. From Data Cubes to Embeddings During the development phase in March, participants will pretrain their encoders using self-supervisedlearning methods that underpin neural compression and EO foundation models.
SupervisedLearning First, what exactly is supervisedlearning? It is the most common type of machine learning that you will use. In supervised machine learning, the machine learningalgorithm is trained on a labeled dataset. This is where supervisedlearning would come in handy.
The classification model learns from the training data, identifying the distinguishing characteristics between each class, enabling it to make informed predictions. Classification in machine learning can be a versatile tool with numerous applications across various industries.
It is a form of AI that learns, adapts, and improves as it encounters changes, both in data and the environment. Unlike traditional AI, which follows set rules and algorithms and tends to fall apart when faced with obstacles, adaptive AI systems can modify their behavior based on their experiences. What is Adaptive AI?
These figures underscore the pressing need for awareness and solutions regarding the challenges faced by Machine Learning professionals. Key Takeaways Data quality is crucial; poor data leads to unreliable Machine Learning models. Algorithmic bias can result in unfair outcomes, necessitating careful management.
From predicting disease outbreaks to identifying complex medical patterns and helping researchers develop targeted therapies, the potential applications of machine learning in healthcare are vast and varied. What is machine learning? From personalized medicine to disease prevention, the possibilities are endless.
Zero-shot, one-shot, and few-shot learning are redefining how machines adapt and learn, promising a future where adaptability and generalization reach unprecedented levels. Source: Photo by Hal Gatewood on Unsplash In this exploration, we navigate from the basics of supervisedlearning to the forefront of adaptive models.
Support Vector Machines (SVM) are a type of supervisedlearningalgorithm designed for classification and regression tasks. In the context of SVMs, it serves as the decision boundary that separates different classes of data, allowing for distinct classifications in supervisedlearning.
Interpretability and Explainable AI Learning on Graphs and Other Geometries & Topologies Learning Theory Neurosymbolic & Hybrid AI Systems (Physics-Informed, Logic & Formal Reasoning, etc.) Optimization Other Topics in Machine Learning (i.e.,
By dividing the workload and data across multiple nodes, distributed learning enables parallel processing, leading to faster and more efficient training of machine learning models. There are various types of machine learningalgorithms, including supervisedlearning, unsupervised learning, and reinforcement learning.
Imagine a world where computers can’t interpret the visual information around them without a little human assistance. These labels provide crucial context for machine learning models, enabling them to make informed decisions and predictions. That’s where data annotation comes into play.
In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the Decision Tree. In contrast, Unsupervised Learning occurs when we lack prior knowledge of the target variable. This often occurs in Cluster Analysis, where we identify clusters without prior information.
However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions. This is the k-nearest neighbor (k-NN) algorithm. For more information, refer to Create a VPC.
On the other hand, artificial intelligence is the simulation of human intelligence in machines that are programmed to think and learn like humans. By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informed decisions and take autonomous actions.
Additionally, it is crucial to comprehend the fundamental concepts that underlie AI, including neural networks, algorithms, and data structures. AI systems use a combination of algorithms, machine learning techniques, and data analytics to simulate human intelligence. What is artificial intelligence?
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
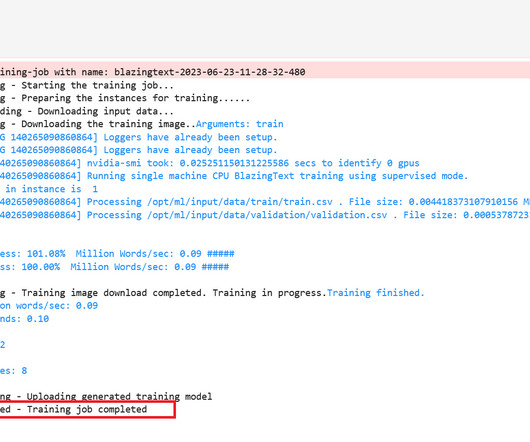
It’s important to take extra precautions to protect your device and sensitive information. The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. The BlazingText algorithm expects a single preprocessed text file with space-separated tokens.
Summary: This blog highlights ten crucial Machine Learningalgorithms to know in 2024, including linear regression, decision trees, and reinforcement learning. Each algorithm is explained with its applications, strengths, and weaknesses, providing valuable insights for practitioners and enthusiasts in the field.
These complex algorithms are the backbone upon which our modern technological advancements rest and which are doing wonders for natural language communication. PaLM 2 stands for “ Progressive and Adaptive Language Model 2 ” and Llama 2 is short for “ Language Learning and Mastery Algorithm 2 ”.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, K Nearest Neighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? You just want to create and analyze simple maps not to learn algebra all over again.
By leveraging labeled training data, these models learn the underlying patterns and associations between input features and the desired outcome. This knowledge empowers the models to make informed predictions for new and unseen data, opening up a world of possibilities in diverse domains such as finance, healthcare, retail, and more.
First, there is a lack of scalability with conventional supervisedlearning approaches. In contrast, self-supervisedlearning can leverage audio-only data, which is available in much larger quantities across languages. This requires the learningalgorithm to be flexible, efficient, and generalizable.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. Introduction Machine Learning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions.
Understanding fine-tuning, even if not doing it yourself, aids in informed decision-making. This allows them to learn a wide range of tasks, such as text generation, translation, and question-answering. One common approach is to use supervisedlearning. This process involves retraining LLMs on new data.
We’re educating the computer to learn from data (the equivalent of practice), to make informed predictions (akin to riding the bicycle), and to progressively improve with each iteration. In the context of Machine Learning, data can be anything from images, text, numbers, to anything else that the computer can process and learn from.
Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models. Sometimes the unsupervised algorithm will happen to produce the output you want, but other times it won’t.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content