This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rapid Automatic Keyword Extraction(RAKE) is a Domain-Independent keyword extraction algorithm in NaturalLanguageProcessing. It is an Individual document-oriented dynamic Information retrieval method. Concept of RAKE is built on three matrices Word Degree (deg(w)), Word Frequency (freq(w)), Ratio of […].
Introduction DocVQA (Document Visual Question Answering) is a research field in computer vision and naturallanguageprocessing that focuses on developing algorithms to answer questions related to the content of a document, like a scanned document or an image of a text document.
NaturalLanguageProcessing (NLP) is revolutionizing the way we interact with technology. By enabling computers to understand and respond to human language, NLP opens up a world of possibilitiesfrom enhancing user experiences in chatbots to improving the accuracy of search engines.
Naturallanguageprocessing (NLP) is a fascinating field at the intersection of computer science and linguistics, enabling machines to interpret and engage with human language. What is naturallanguageprocessing (NLP)? Identifying spam and filtering digital communication.
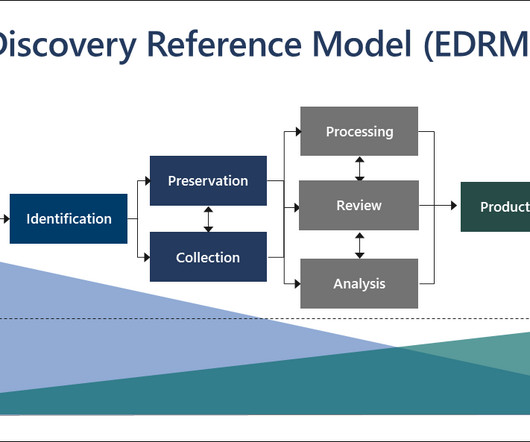
It is the process of identifying, collecting, and producing electronically stored information (ESI) in response to a request for production in a lawsuit or investigation. Anyhow, with the exponential growth of digital data, manual document review can be a challenging task.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
Intelligent documentprocessing (IDP) is transforming the way businesses manage their documentation and data management processes. By harnessing the power of emerging technologies, organizations can automate the extraction and handling of data from various document types, significantly enhancing operational workflows.
It includes tasks requiring advanced reasoning and nuanced language understanding, essential for real-world applications. The complexity of SuperGLUE tasks drives researchers to develop more sophisticated models, leading to advanced algorithms and techniques. For example, virtual assistants that need to understand customer queries.
In this paper we present a new method for automatic transliteration and segmentation of Unicode cuneiform glyphs using NaturalLanguageProcessing (NLP) techniques. Cuneiform is one of the earliest known writing system in the world, which documents millennia of human civilizations in the ancient Near East.
10+ Python packages for NaturalLanguageProcessing that you can’t miss, along with their corresponding code.Foto di Max Duzij su Unsplash NaturalLanguageProcessing is the field of Artificial Intelligence that involves text analysis. It combines statistics and mathematics with computational linguistics.
Over the past few years, a shift has shifted from NaturalLanguageProcessing (NLP) to the emergence of Large Language Models (LLMs). By analyzing diverse data sources and incorporating advanced machine learning algorithms, LLMs enable more informed decision-making, minimizing potential risks.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. This post is co-written with Ken Tsui, Edward Tsoi and Mickey Yip from Apoidea Group. SuperAcc has demonstrated significant improvements in the banking sector.
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. The knowledge base architecture focuses on processing and storing agronomic data, providing quick and reliable access to critical information. What corn hybrids do you suggest for my field?”.
The learning program is typically designed for working professionals who want to learn about the advancing technological landscape of language models and learn to apply it to their work. It covers a range of topics including generative AI, LLM basics, naturallanguageprocessing, vector databases, prompt engineering, and much more.
This technology allows data to be represented in a way that captures its underlying structure, enabling algorithms to process it more effectively. Embeddings in machine learning refer to the numerical representations that convert categorical data into a format conducive for algorithms to process.
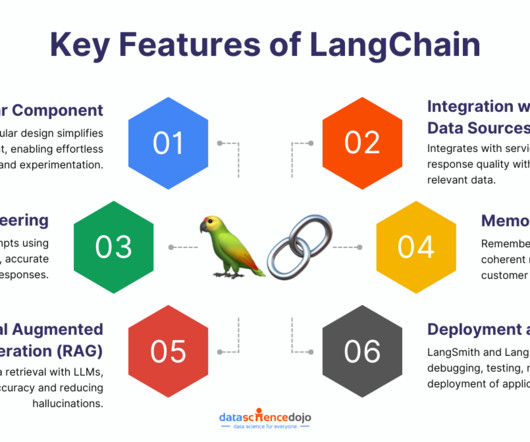
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. The model then uses a clustering algorithm to group the sentences into clusters. It works by first embedding the sentences in the text using BERT.
For example, if you’re building a chatbot, you can combine modules for naturallanguageprocessing (NLP), data retrieval, and user interaction. RAG Workflows RAG is a technique that helps LLMs fetch relevant information from external databases or documents to ground their responses in reality.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Key components include machine learning, which allows systems to learn from data, and naturallanguageprocessing, enabling machines to understand and respond to human language. Reasoning: It selects the appropriate algorithms to derive desired outcomes.
Here are some key ways data scientists are leveraging AI tools and technologies: 6 Ways Data Scientists are Leveraging Large Language Models with Examples Advanced Machine Learning Algorithms: Data scientists are utilizing more advanced machine learning algorithms to derive valuable insights from complex and large datasets.
Healthcare system faces persistent challenges due to its heavy reliance on manual processes and fragmented communication. Providers struggle with the administrative burden of documentation and coding, which consumes 2531% of total healthcare spending and detracts from their ability to deliver quality care.
This can include databases, documents, emails, and other internal repositories. NaturalLanguageProcessing (NLP) plays a significant role here by assisting in comprehending complex data. Users input search terms, and search algorithms work to return relevant results.
GPT-4 with Vision combines naturallanguageprocessing capabilities with computer vision. It could be a game-changer in digitizing written or printed documents by converting images of text into a digital format. Object Detection GPT-4V has superior object detection capabilities.
Text classification, text summarization TF-IDF embeddings Represent text as a bag of words, where each word is assigned a weight based on its frequency and inverse document frequency. TF-IDF TF-IDF (term frequency-inverse document frequency) is a statistical measure that is used to quantify the importance of a word in a document.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. To learn more, refer to the API documentation. Clean up After you’re done running the notebook, delete all resources that you created in the process.
Merlin is a comprehensive AI-powered assistant designed to enhance productivity by integrating advanced naturallanguageprocessing (NLP) models like GPT-4 and Claude-3 into everyday tasks. While the process was smooth, we found that the output wasn’t entirely accurate based on our input.
I work on machine learning for naturallanguageprocessing, and I’m particularly interested in few-shot learning, lifelong learning, and societal and health applications such as abuse detection, misinformation, mental ill-health detection, and language assessment. Data science is a broad field.
See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. One more embellishment is to use a graph neural network (GNN) trained on the documents.
Language models, a recent advanced technology that is blooming more and more as the days go by. These complex algorithms are the backbone upon which our modern technological advancements rest and which are doing wonders for naturallanguage communication. These are more than just names; they are the cutting edge of NLP.
In contrast, unstructured data, such as text documents or images, lacks this formal structure, while semi-structured data sits somewhere in between, containing both organized elements and free-form content. Facilitated data analysis Structured data significantly supports analytical processes.
The platform helped the agency digitize and process forms, pictures, and other documents. Using the platform, which uses Amazon Textract , AWS Fargate , and other services, the agency gained a four-fold productivity improvement by streamlining and automating labor-intensive manual processes.
A user asking a scientific question aims to translate scientific intent, such as I want to find patients with a diagnosis of diabetes and a subsequent metformin fill, into algorithms that capture these variables in real-world data. An in-context learning technique that includes semantically relevant solved questions and answers in the prompt.
It is fast, scalable, and supports a variety of machine learning algorithms. They are used in a variety of AI applications, such as image search, naturallanguageprocessing, and recommender systems. Milvus is used by companies such as Alibaba, Baidu, and Tencent.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for naturallanguageprocessing tasks. invocations is the endpoint that receives client inference POST The format of the request and the response is up to the algorithm.
AI startups often focus on developing cutting-edge technology and algorithms that analyze and process large amounts of data quickly and accurately. The new age focus uses naturallanguageprocessing to help businesses create more effective marketing messages. Lumin8ai.com Luminate.ai
This is particularly advantageous in areas where labeled data is scarce, such as naturallanguageprocessing and computer vision. This approach can highlight the subtleties within complex datasets, making it easier for algorithms to distinguish between relevant and irrelevant information. What is contrastive learning?
Data archiving is the systematic process of securely storing and preserving electronic data, including documents, images, videos, and other digital content, for long-term retention and easy retrieval. Lastly, data archiving allows organizations to preserve historical records and documents for future reference.
GPT-4 with Vision combines naturallanguageprocessing capabilities with computer vision. It could be a game-changer in digitizing written or printed documents by converting images of text into a digital format. Object Detection GPT-4V has superior object detection capabilities.
GPT-4 with Vision combines naturallanguageprocessing capabilities with computer vision. It could be a game-changer in digitizing written or printed documents by converting images of text into a digital format. Object Detection: GPT-4V has superior object detection capabilities.
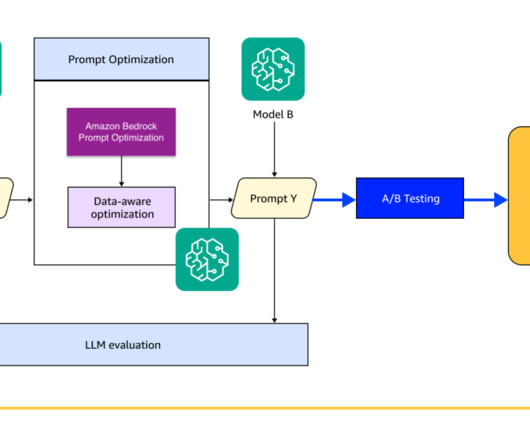
The following example shows how prompt optimization converts a typical prompt for a summarization task on Anthropics Claude Haiku into a well-structured prompt for an Amazon Nova model, with sections that begin with special markdown tags such as ## Task, ### Summarization Instructions , and ### Document to Summarize.
The Evolution of NLP Models NaturalLanguageProcessing (NLP) has transformed how machines understand and generate human language. From simple text processing to powerful language models capable of complex text generation, the journey of NLP has been remarkable. Photo by Joshua Hoehne on Unsplash 1.
Their architecture is a beacon of parallel processing capability, enabling the execution of thousands of tasks simultaneously. This attribute is particularly beneficial for algorithms that thrive on parallelization, effectively accelerating tasks that range from complex simulations to deep learning model training.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content