This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Data collection and storage These engineers design frameworks to collect data from diverse sources and store it in systems like data warehouses and datalakes, ensuring efficient data retrieval and processing.
This data is then integrated into centralized databases for further processing and analysis. Data Cleaning and Preprocessing IoT data can be noisy, incomplete, and inconsistent. Data engineers employ data cleaning and preprocessing techniques to ensure dataquality, making it ready for analysis and decision-making.
This stage includes: Cleaning and converting data: Ensuring dataquality by removing inconsistencies and converting data into usable formats. Organizing it: Structuring data in a way that facilitates easy access and processing. Unsupervised learning: Allowing models to find patterns in unlabeled data.
Open-source datasets: Utilize publicly available data for training models. Building a datalake A datalake is a central repository that allows for the storage of vast amounts of structured and unstructured data. Testing set: Evaluates model performance against unseen data, identifying its weaknesses.
Predictive analytics: Predictive analytics leverages historical data and statistical algorithms to make predictions about future events or trends. Machine learning and AI analytics: Machine learning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Apache Superset remains popular thanks to how well it gives you control over your data. Algorithm-visualizer GitHub | Website Algorithm Visualizer is an interactive online platform that visualizes algorithms from code. The no-code visualization builds are a handy feature.
Data: the foundation of your foundation model Dataquality matters. An AI model trained on biased or toxic data will naturally tend to produce biased or toxic outputs. When objectionable data is identified, we remove it, retrain the model, and repeat. Data curation is a task that’s never truly finished.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
Developed by Salesforce, Einstein Discovery enables people to create powerful predictive models without needing to write algorithms. This offers everyone from data scientists to advanced analysts to business users an intuitive, no-code environment that empowers quick and confident decisions guided by ethical, transparent AI.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
For the preceding techniques, the foundation should provide scalable infrastructure for data storage and training, a mechanism to orchestrate tuning and training pipelines, a model registry to centrally register and govern the model, and infrastructure to host the model. She has presented her work at various learning conferences.
For these reasons, finding and evaluating data is often time-consuming. Instead of spending most of their time leveraging their unique skillsets and algorithmic knowledge, data scientists are stuck sorting through data sets, trying to determine what’s trustworthy and how best to use that data for their own goals.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. Why Are Data Transformation Tools Important?
Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of Artificial Intelligence (AI) possible. DataQuality When using a data pipeline, data consistency, quality, and reliability are often greatly improved.
Building an Open, Governed Lakehouse with Apache Iceberg and Apache Polaris (Incubating) Yufei Gu | Senior Software Engineer | Snowflake In this session, you’ll explore how open-source table formats are revolutionizing data architectures by enabling the power and efficiency of data warehouses within datalakes.
In general, this data has no clear structure because it may manifest real-world complexity, such as the subtlety of language or the details in a picture. Advanced methods are needed to process unstructured data, but its unstructured nature comes from how easily it is made and shared in today's digital world. Tools like Unstructured.io
DataLake vs. Data Warehouse Distinguishing between these two storage paradigms and understanding their use cases. Students should learn how datalake s can store raw data in its native format, while data warehouses are optimised for structured data.
Developed by Salesforce, Einstein Discovery enables people to create powerful predictive models without needing to write algorithms. This offers everyone from data scientists to advanced analysts to business users an intuitive, no-code environment that empowers quick and confident decisions guided by ethical, transparent AI.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party big data sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
Common options include: Relational Databases: Structured storage supporting ACID transactions, suitable for structured data. NoSQL Databases: Flexible, scalable solutions for unstructured or semi-structured data. Data Warehouses : Centralised repositories optimised for analytics and reporting.
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a data warehouse or datalake. DataLakes: These store raw, unprocessed data in its original format.
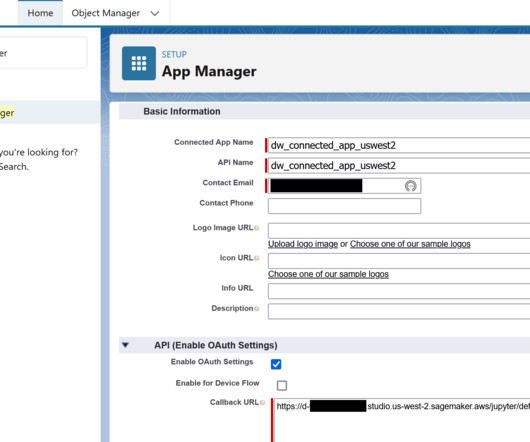
For more information about this process, refer to New — Introducing Support for Real-Time and Batch Inference in Amazon SageMaker Data Wrangler. Although we use a specific algorithm to train the model in our example, you can use any algorithm that you find appropriate for your use case. Dharmendra Kumar Rai (DK Rai) is a Sr.
HPCC Systems — The Kit and Kaboodle for Big Data and Data Science Bob Foreman | Software Engineering Lead | LexisNexis/HPCC Join this session to learn how ECL can help you create powerful data queries through a comprehensive and dedicated datalake platform. Check them out for free!
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
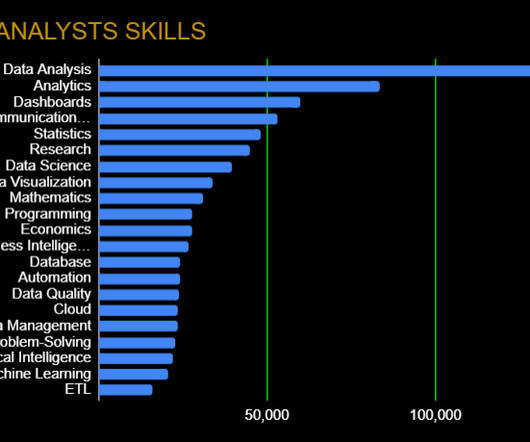
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of Artificial Intelligence (AI) possible. DataQuality When using a data pipeline, data consistency, quality, and reliability are often greatly improved.
Data Processing : You need to save the processed data through computations such as aggregation, filtering and sorting. Data Storage : To store this processed data to retrieve it over time – be it a data warehouse or a datalake. This ensures that the data is accurate, consistent, and reliable.
Here are some specific reasons why they are important: Data Integration: Organizations can integrate data from various sources using ETL pipelines. This provides data scientists with a unified view of the data and helps them decide how the model should be trained, values for hyperparameters, etc.
DataQuality Next, dive into the details of your data. Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your cloud data warehouse.
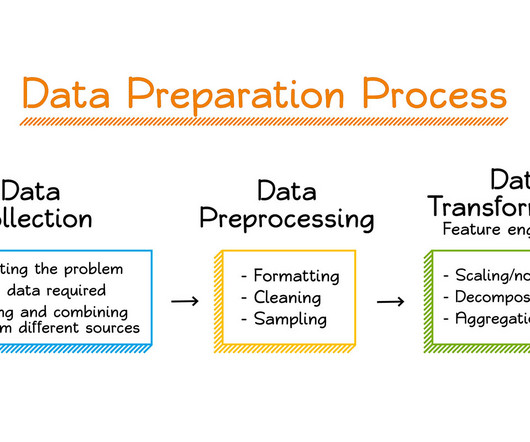
While data preparation for machine learning may not be the most “glamorous” aspect of a data scientist’s job, it is the one that has the greatest impact on the quality of model performance and consequently the business impact of the machine learning product or service.
Olalekan said that most of the random people they talked to initially wanted a platform to handle dataquality better, but after the survey, he found out that this was the fifth most crucial need. And when the platform automates the entire process, it’ll likely produce and deploy a bad-quality model.
The pipelines are interoperable to build a working system: Data (input) pipeline (data acquisition and feature management steps) This pipeline transports raw data from one location to another. Model/training pipeline This pipeline trains one or more models on the training data with preset hyperparameters.
Let’s break down why this is so powerful for us marketers: Data Preservation : By keeping a copy of your raw customer data, you preserve the original context and granularity. DataQuality Management : Persistent staging provides a clear demarcation between raw and processed customer data. New user sign-up?
The benefits of this solution are: You can flexibly achieve data cleaning, sanitizing, and dataquality management in addition to chunking and embedding. You can build and manage an incremental data pipeline to update embeddings on Vectorstore at scale. You can choose a wide variety of embedding models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content