This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Author(s): Sanjay Nandakumar Originally published on Towards AI. Methodology Overview In our work, we follow these steps: Data Generation: Generate a synthetic dataset that contains effects on the behaviour of voters. Model Fitting and Training: Various ML models trained on sub-patterns in data.
This includes sourcing, gathering, arranging, processing, and modeling data, as well as being able to analyze large volumes of structured or unstructured data. The goal of datapreparation is to present data in the best forms for decision-making and problem-solving.
From data management to model fine-tuning, LLMOps ensures efficiency, scalability, and risk mitigation. As LLMs redefine AI capabilities, mastering LLMOps becomes your compass in this dynamic landscape. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production.
ZURU collaborated with AWS Generative AI Innovation Center and AWS Professional Services to implement a more accurate text-to-floor plan generator using generative AI. Following this filtering mechanism, data points not achieving 100% accuracy on instruction adherence are removed from the training dataset.
Last Updated on August 17, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. Jason Leung on Unsplash AI is still considered a relatively new field, so there are really no guides or standards such as SWEBOK. 85% or more of AI projects fail [1][2]. 85% or more of AI projects fail [1][2].
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, data silos, broken machine learning models, and locked ROI. ExploratoryDataAnalysis After we connect to Snowflake, we can start our ML experiment.
It ensures that the data used in analysis or modeling is comprehensive and comprehensive. Integration also helps avoid duplication and redundancy of data, providing a comprehensive view of the information. EDA provides insights into the data distribution and informs the selection of appropriate preprocessing techniques.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Summary: Vertex AI is a comprehensive platform that simplifies the entire Machine Learning lifecycle. From datapreparation and model training to deployment and management, Vertex AI provides the tools and infrastructure needed to build intelligent applications.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Email classification project diagram The workflow consists of the following components: Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratorydataanalysis (EDA), data cleaning and preparation, and building prototype models.
” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape. Machine learning and AI : Are you ready to casting predictive spells?
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and clean data from multiple sources, ensuring it is suitable for analysis. This step ensures that all relevant data is available in one place.
Example Use Cases Altair is commonly used in ExploratoryDataAnalysis (EDA) to quickly visualise data distributions, relationships, and trends. Automated Data Handling: Automatically manages datapreparation and processing for visualisations.
Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development. Python is renowned for its simplicity and versatility, making it an ideal choice for AI applications.
After reading the book, ML practitioners and leaders will know how to deploy their ML models to production and scale their AI initiatives, while overcoming the challenges many other businesses are facing. The book contains a full chapter dedicated to generative AI. Why Did the Authors Decide to Write this Book?
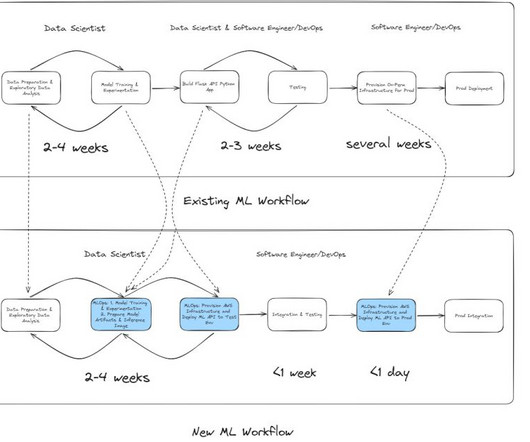
Legacy workflow: On-premises ML development and deployment When the data science team needed to build a new fraud detection model, the development process typically took 24 weeks. This new design accelerates model development and deployment, so Radial can respond faster to evolving fraud detection challenges.
It accomplishes this by finding new features, called principal components, that capture the most significant patterns in the data. These principal components are ordered by importance, with the first component explaining the most variance in the data. Data cleaning : Handle missing values and outliers if necessary.
We will also explore the opportunities and factors to be taken into account while using ChatGPT for Data Science. Leveraging ChatGPT for Data Science ChatGPT for DataAnalysis ChatGPT is a useful tool for Data Scientists. It facilitates exploratoryDataAnalysis and provides quick insights.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. The Microsoft Certified: Azure Data Scientist Associate certification is highly recommended, as it focuses on the specific tools and techniques used within Azure.
There is a position called Data Analyst whose work is to analyze the historical data, and from that, they will derive some KPI s (Key Performance Indicators) for making any further calls. For DataAnalysis you can focus on such topics as Feature Engineering , Data Wrangling , and EDA which is also known as ExploratoryDataAnalysis.
The inferSchema parameter is set to True to infer the data types of the columns, and header is set to True to use the first row as headers. For a comprehensive understanding of the practical applications, including a detailed code walkthrough from datapreparation to model deployment, please join us at the ODSC APAC conference 2023.
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring. As an example for catalogue data, it’s important to check if the set of mandatory fields like product title, primary image, nutritional values, etc.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. I’ll show you best practices for using Jupyter Notebooks for exploratorydataanalysis. When data science was sexy , notebooks weren’t a thing yet.
Last Updated on July 19, 2023 by Editorial Team Author(s): Anirudh Chandra Originally published on Towards AI. That post was dedicated to an exploratorydataanalysis while this post is geared towards building prediction models. DataPreparation Photo by Bonnie Kittle […]
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content