This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Author(s): Sanjay Nandakumar Originally published on Towards AI. Model Fitting and Training: Various ML models trained on sub-patterns in data. EDA will start by visualizing the distribution of the various features and the relationships between the features and the target variable.
From data management to model fine-tuning, LLMOps ensures efficiency, scalability, and risk mitigation. As LLMs redefine AI capabilities, mastering LLMOps becomes your compass in this dynamic landscape. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production.
Last Updated on August 17, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. Jason Leung on Unsplash AI is still considered a relatively new field, so there are really no guides or standards such as SWEBOK. 85% or more of AI projects fail [1][2]. 85% or more of AI projects fail [1][2].
Last Updated on June 25, 2024 by Editorial Team Author(s): Mena Wang, PhD Originally published on Towards AI. Image generated by Gemini Spark is an open-source distributed computing framework for high-speed data processing. This practice vastly enhances the speed of my datapreparation for machine learning projects.
Integration also helps avoid duplication and redundancy of data, providing a comprehensive view of the information. Exploratory data analysis (EDA) Before preprocessing data, conducting exploratory data analysis is crucial to understand the dataset’s characteristics, identify patterns, detect outliers, and validate missing values.
Summary: Vertex AI is a comprehensive platform that simplifies the entire Machine Learning lifecycle. From datapreparation and model training to deployment and management, Vertex AI provides the tools and infrastructure needed to build intelligent applications.
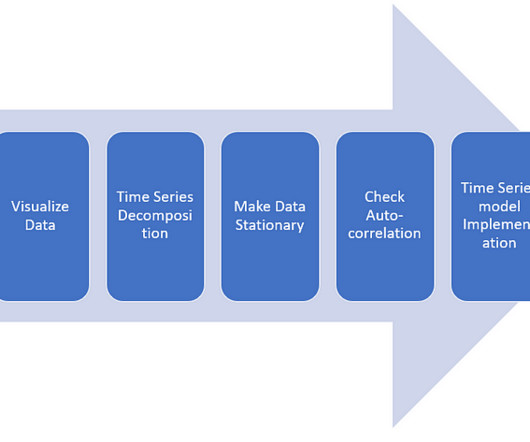
Last Updated on July 19, 2023 by Editorial Team Author(s): Yashashri Shiral Originally published on Towards AI. DataPreparation — Collect data, Understand features 2. Visualize Data — Rolling mean/ Standard Deviation— helps in understanding short-term trends in data and outliers.
Email classification project diagram The workflow consists of the following components: Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratory data analysis (EDA), data cleaning and preparation, and building prototype models.
Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development. Python is renowned for its simplicity and versatility, making it an ideal choice for AI applications.
” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape. Machine learning and AI : Are you ready to casting predictive spells?
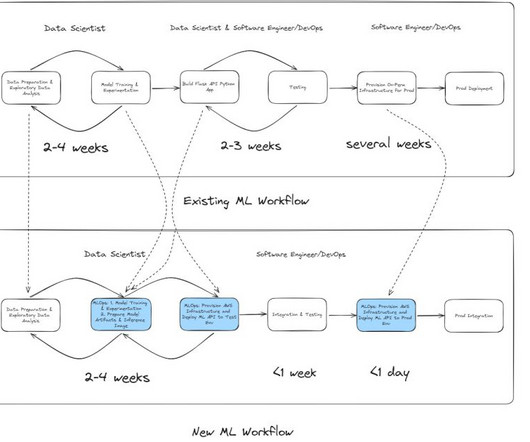
Legacy workflow: On-premises ML development and deployment When the data science team needed to build a new fraud detection model, the development process typically took 24 weeks. This new design accelerates model development and deployment, so Radial can respond faster to evolving fraud detection challenges.
Additionally, you will work closely with cross-functional teams, translating complex data insights into actionable recommendations that can significantly impact business strategies and drive overall success. Also Read: Explore data effortlessly with Python Libraries for (Partial) EDA: Unleashing the Power of Data Exploration.
After reading the book, ML practitioners and leaders will know how to deploy their ML models to production and scale their AI initiatives, while overcoming the challenges many other businesses are facing. The book contains a full chapter dedicated to generative AI. Why Did the Authors Decide to Write this Book?
For ML model development, the size of a SageMaker notebook instance depends on the amount of data you need to load in-memory for meaningful exploratory data analyses (EDA) and the amount of computation required. As with SageMaker notebooks, you can also feed AWS CUR data into QuickSight for reporting or visualization purposes.
For Data Analysis you can focus on such topics as Feature Engineering , Data Wrangling , and EDA which is also known as Exploratory Data Analysis. First learn the basics of Feature Engineering, and EDA then take some different-different data sheets (data frames) and apply all the techniques you have learned to date.
Example Use Cases Altair is commonly used in Exploratory Data Analysis (EDA) to quickly visualise data distributions, relationships, and trends. Aesthetic Mapping: Utilises color, size, and shape to represent data variables. Automated Data Handling: Automatically manages datapreparation and processing for visualisations.
The inferSchema parameter is set to True to infer the data types of the columns, and header is set to True to use the first row as headers. For a comprehensive understanding of the practical applications, including a detailed code walkthrough from datapreparation to model deployment, please join us at the ODSC APAC conference 2023.
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring. So, we need to build a verification layer that runs based on a set of rules to verify and validate data before preparing it for model training.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content