This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
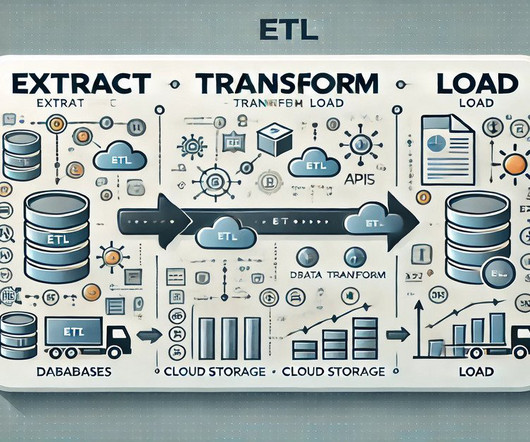
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
Business leaders risk compromising their competitive edge if they do not proactively implement generative AI (gen AI). However, businesses scaling AI face entry barriers. This situation will exacerbate data silos, increase costs and complicate the governance of AI and data workloads.
In today’s data-driven environment, enterprises face the challenge of transforming massive volumes of raw data into actionable insights efficiently. Achieving AI success depends on building a robust and scalable data infrastructure.
Datapipelines are like insurance. ETL processes are constantly toiling away behind the scenes, doing heavy lifting to connect the sources of data from the real world with the warehouses and lakes that make the data useful. You only know they exist when something goes wrong.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETLpipeline orchestration. ETL ProcessBasics So what exactly is ETL?
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Key Takeaways Trusted data is critical for AI success. Data integration ensures your AI initiatives are fueled by complete, relevant, and real-time enterprise data, minimizing errors and unreliable outcomes that could harm your business. Data integration solves key business challenges.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
In todays fast-moving machine learning and AI landscape, access to top-tier tools and infrastructure is a game-changer for any data science team. Thats why AI creditsvouchers that grant free or discounted access to cloud services and machine learning platformsare increasingly valuable. AI Credit Partners: Whos OfferingWhat?
This post is a bitesize walk-through of the 2021 Executive Guide to Data Science and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Automation Automating datapipelines and models ➡️ 6. Download the free, unabridged version here.
Last Updated on March 21, 2023 by Editorial Team Author(s): Data Science meets Cyber Security Originally published on Towards AI. Navigating the World of Data Engineering: A Beginner’s Guide. A GLIMPSE OF DATA ENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? What are ETL and datapipelines?
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Data is the differentiator as business leaders look to utilize their competitive edge as they implement generative AI (gen AI). Leaders feel the pressure to infuse their processes with artificial intelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement.
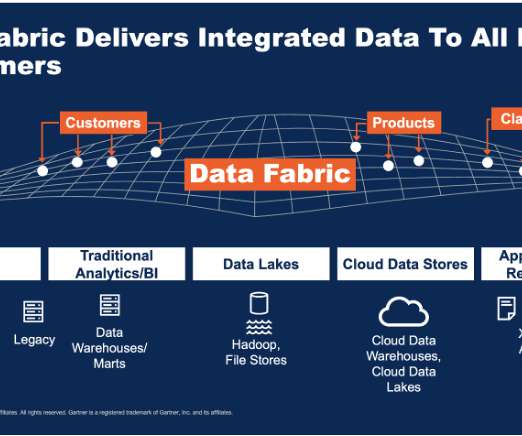
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
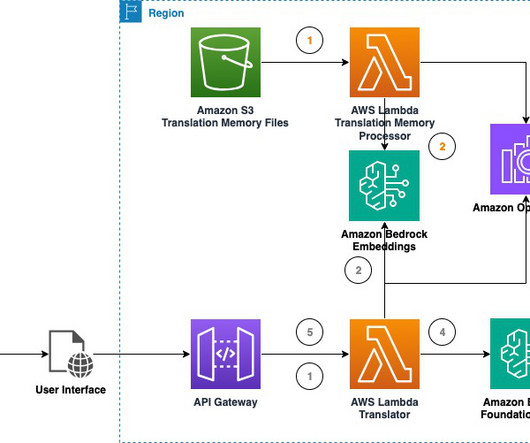
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. Qiong (Jo) Zhang , PhD, is a Senior Partner Solutions Architect at AWS, specializing in AI/ML.
It is used by businesses across industries for a wide range of applications, including fraud prevention, marketing automation, customer service, artificial intelligence (AI), chatbots, virtual assistants, and recommendations. we have Databricks which is an open-source, next-generation data management platform.
Modern AI success stories share a common backbone: realtime data streaming. As Gartner notes in its 2025 Strategic Technology Trends , organizations that operationalize continuous data flows will forge safely into the future with responsible innovation, leveraging AI to out-maneuver slower, batchoriented competitors.
Many customers are building generative AI apps on Amazon Bedrock and Amazon CodeWhisperer to create code artifacts based on natural language. Amazon Bedrock is the easiest way to build and scale generative AI applications with foundation models (FMs). Using AI, AutoLink automatically identified and suggested potential matches.
It is critical for AI models to capture not only the context, but also the cultural specificities to produce a more natural sounding translation. For instance, if you want to keep the phrase Gen AI untranslated regardless of the language, you can configure the custom terminology as illustrated in the following screenshot.
To solve this problem, we had to design a strong datapipeline to create the ML features from the raw data and MLOps. Multiple data sources ODIN is an MMORPG where the game players interact with each other, and there are various events such as level-up, item purchase, and gold (game money) hunting.
Whether youre new to AI development or an experienced practitioner, this post provides step-by-step guidance and code examples to help you build more reliable AI applications. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
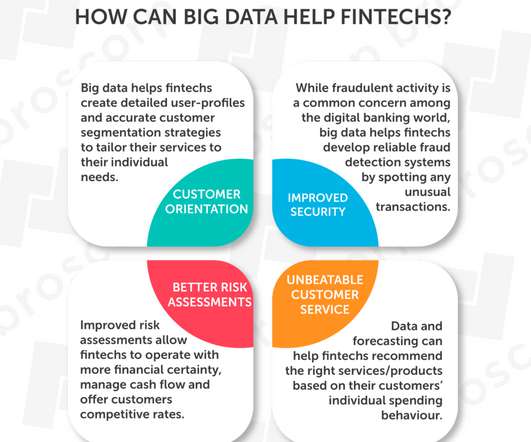
Businesses in the Fintech industry can harness the power of big data to personalize chatbot customer service. AI-powered chatbots will access raw data, allowing them to answer customer questions accurately and straight to the point. ETL and Business Intelligence solutions make dealing with large volumes of data easy.
The Rise of AI Engineering andMLOps 20182019: Early discussions around MLOps and AI engineering were sparse, primarily focused on general machine learning best practices. 20232024: AI engineering became a hot topic, expanding beyond MLOps to include AI agents, autonomous systems, and scalable model deployment techniques.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. Lets look at how generative AI can help solve this problem. Refer to Configure security in Amazon SageMaker AI for details.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Implement data lineage tooling and methodologies: Tools are available that help organizations track the lineage of their data sets from ultimate source to target by parsing code, ETL (extract, transform, load) solutions and more. Your data scientists, executives and customers will thank you!
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible.
As a bonus, well check out Matillions AI Copilot and see how AI can help take workflow design to the next level. For those unfamiliar with GIT or GIT practices, please refer Git for Business Users with Matillion DPC What is a Matillion Pipeline? For additional Matillion AI Features, visit Matillion AI Overview.
Over the years, businesses have increasingly turned to Snowflake AIData Cloud for various use cases beyond just data analytics and business intelligence. However, one consistent challenge customers face is efficiently integrating and moving data between on-premises systems, cloud environments, and other data sources.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Further expanding the capabilities of AI in marketing, Zeta Global has developed AI Lookalikes.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud data warehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
It’s distributed both in the cloud and on-premises, allowing extensive use and movement across clouds, apps and networks, as well as stores of data at rest. An architecture designed for data democratization aims to be flexible, integrated, agile and secure to enable the use of data and artificial intelligence (AI) at scale.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
Read this e-book on building strong governance foundations Why automated data lineage is crucial for success Data lineage , the process of tracking the flow of data over time from origin to destination within a datapipeline, is essential to understand the full lifecycle of data and ensure regulatory compliance.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring data quality and integrity.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























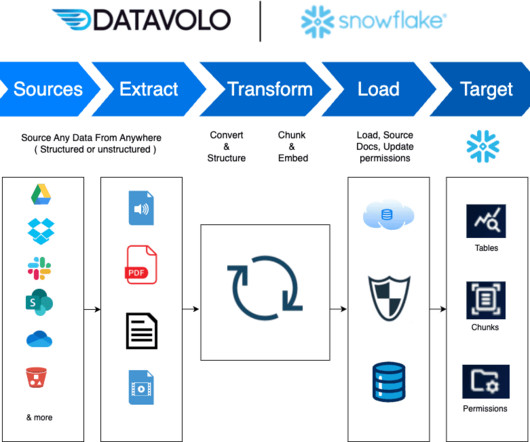














Let's personalize your content