This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To reduce costs while continuing to use the power of AI , many companies have shifted to fine tuning LLMs on their domain-specific data using Parameter-Efficient Fine Tuning (PEFT). Manually managing such complexity can often be counter-productive and take away valuable resources from your businesses AI development.
In this post, we introduce an innovative solution for end-to-end model customization and deployment at the edge using Amazon SageMaker and Qualcomm AI Hub. After fine-tuning, we show you how to optimize the model with Qualcomm AI Hub so that it’s ready for deployment across edge devices powered by Snapdragon and Qualcomm platforms.
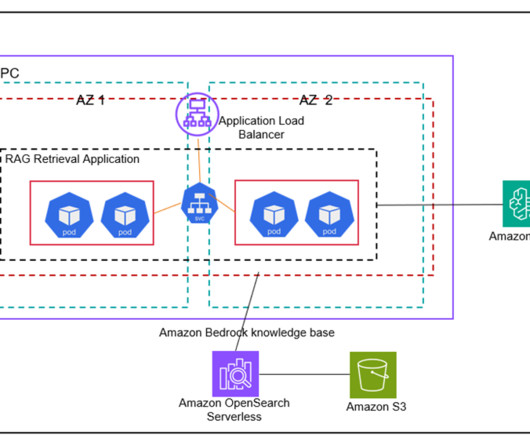
You can chat with your structured data by setting up structured data ingestion from AWS Glue Data Catalog tables and Amazon Redshift clusters in a few steps, using the power of Amazon Bedrock Knowledge Bases structured data retrieval. Developers often face challenges integrating structured data into generative AI applications.
With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. These batches are then evenly distributed across the machines in a cluster. format("/".join(tile_prefix),
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
Just two days ago, Chinese AI startup DeepSeek quietly dropped a bombshell on Hugging Face: a 685-billion-parameter large language model called DeepSeek-V3-0324. Just a massive set of model weights, an MIT license, and a few technical whispers that were enough to set the AI community ablaze. Download it and see for yourself.
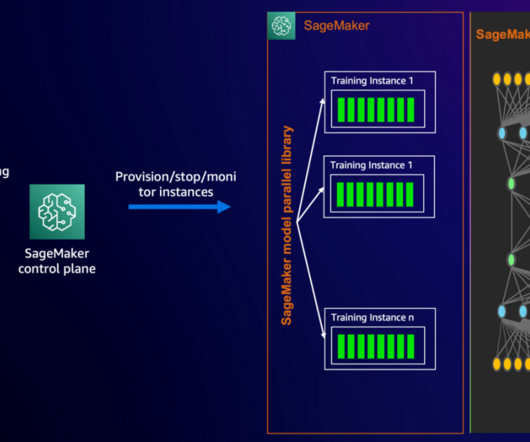
Increasingly, organizations across industries are turning to generative AI foundation models (FMs) to enhance their applications. The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. recipes=recipe-name.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Generative artificial intelligence (AI) applications are commonly built using a technique called Retrieval Augmented Generation (RAG) that provides foundation models (FMs) access to additional data they didnt have during training. Deploy the solution The solution is available for download on the GitHub repo. Sonnet on Amazon Bedrock.
Business use case After its public release, DeepSeek-R1 model, developed by DeepSeek AI , showed impressive results across multiple evaluation benchmarks. To learn more details about these service features, refer to Generative AI foundation model training on Amazon SageMaker.
In the context of generative AI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space. To do so, find the best extracted image in the local directory created when the images were downloaded.
Companies across various scales and industries are using large language models (LLMs) to develop generative AI applications that provide innovative experiences for customers and employees. By offloading the management and maintenance of the training cluster to SageMaker, we reduce both training time and our total cost of ownership (TCO).
CONXAI Technology GmbH is pioneering the development of an advanced AI platform for the Architecture, Engineering, and Construction (AEC) industry. Our platform uses advanced AI to empower construction domain experts to create complex use cases efficiently. These camera feeds can be analyzed using AI to extract valuable insights.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. Customers such as Stability AI use SageMaker HyperPod to train their foundation models, including Stable Diffusion. “As
Jump Right To The Downloads Section Introduction What Is AWS OpenSearch? Amazon OpenSearch Service is a fully managed solution that simplifies the deployment, operation, and scaling of OpenSearch clusters in the AWS Cloud. For this setup: Choose 1 data node and let it handle both data processing and cluster management.
Author(s): Edoardo De Nigris Originally published on Towards AI. This article aims to demonstrate how generative AI models can provide a fresh lens for aggregating and summarizing the collective voices on a single topic, like a movie. A cohesive, AI-generated film critique that is both comprehensive and multifaceted.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
This post is a bitesize walk-through of the 2021 Executive Guide to Data Science and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Download the free, unabridged version here. Case-studies from real-life business scenarios and advice you can act on.
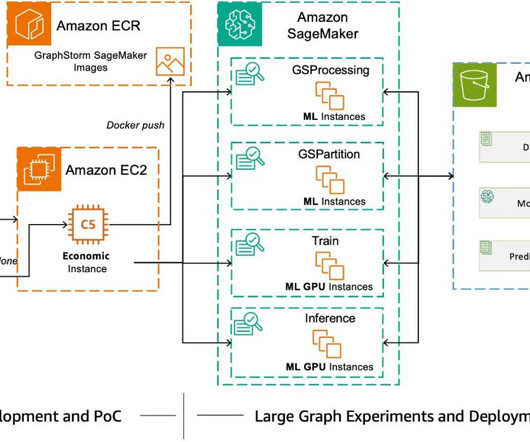
Although GraphStorm can run efficiently on single instances for small graphs, it truly shines when scaling to enterprise-level graphs in distributed mode using a cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances or Amazon SageMaker. Today, AWS AI released GraphStorm v0.4. This dataset has approximately 170,000 nodes and 1.2
Distributed model training requires a cluster of worker nodes that can scale. Amazon Elastic Kubernetes Service (Amazon EKS) is a popular Kubernetes-conformant service that greatly simplifies the process of running AI/ML workloads, making it more manageable and less time-consuming. Cluster with p4de.24xlarge
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. As part of a single cluster run, you can spin up a cluster of Trn1 instances with Trainium accelerators. Trn1 UltraClusters can host up to 30,000 Trainium devices and deliver up to 6 exaflops of compute in a single cluster.
Retrieval Augmented Generation (RAG) enhances AI responses by combining the generative AI models capabilities with information from external data sources, rather than relying solely on the models built-in knowledge.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
His mission is to enable customers achieve their business goals and create value with data and AI. His mission is to enable customers achieve their business goals and create value with data and AI. He helps architect solutions across AI/ML applications, enterprise data platforms, data governance, and unified search in enterprises.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. Delete the Aurora MySQL instance and Aurora cluster.
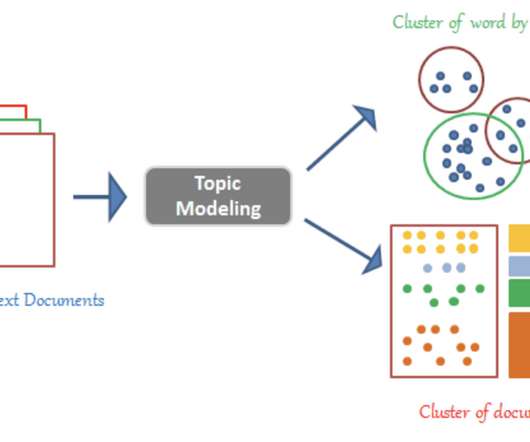
Latent Dirichlet Allocation (LDA) Topic Modeling LDA is a well-known unsupervised clustering method for text analysis. Then, the topic model applies a hierarchical clustering algorithm using conversation vectors from the output of the summary model. The IBM Build Lab team is here to work with you on your AI journey.
Last Updated on February 29, 2024 by Editorial Team Author(s): Hira Akram Originally published on Towards AI. Install Java and Download Kafka: Install Java on the EC2 instance and download the Kafka binary: 4. It communicates with the Cluster Manager to allocate resources and oversee task progress.
In the fast-moving world of AI and data science, high-quality financial datasets are essential for building effective models. Whether its algorithmic trading , risk assessment, fraud detection , credit scoring, or market analysis, the accuracy and depth of financial data can make or break an AI-driven solution.
Asian technology stocks fell sharply Monday as Chinese AI startup DeepSeek sparked sector-wide concerns about artificial intelligence investment sustainability and pricing pressures, triggering selloffs in chip-related shares while boosting some Chinese tech giants. and Advantest plunging 8.8%. the worst performer in Japans Nikkei 225.
Last Updated on April 30, 2024 by Editorial Team Author(s): Harpreet Sahota Originally published on Towards AI. You’ll sign up for a Qdrant cloud account, install the necessary libraries, set up our environment variables, and instantiate a cluster — all the necessary steps to start building something. Click on the “Clusters” menu item.
Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) with these solutions has become increasingly popular. Despite their wealth of general knowledge, state-of-the-art LLMs only have access to the information they were trained on.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
Large language models (LLMs) are making a significant impact in the realm of artificial intelligence (AI). For more information on Trainium Accelerator chips, refer to Achieve high performance with lowest cost for generative AI inference using AWS Inferentia2 and AWS Trainium on Amazon SageMaker.
Solution overview To demonstrate container-based GPU metrics, we create an EKS cluster with g5.2xlarge instances; however, this will work with any supported NVIDIA accelerated instance family. Create an EKS cluster with a node group This group includes a GPU instance family of your choice; in this example, we use the g5.2xlarge instance type.
SageMaker supports various data sources and access patterns, distributed training including heterogenous clusters, as well as experiment management features and automatic model tuning. When an On-Demand job is launched, it goes through five phases: Starting, Downloading, Training, Uploading, and Completed.
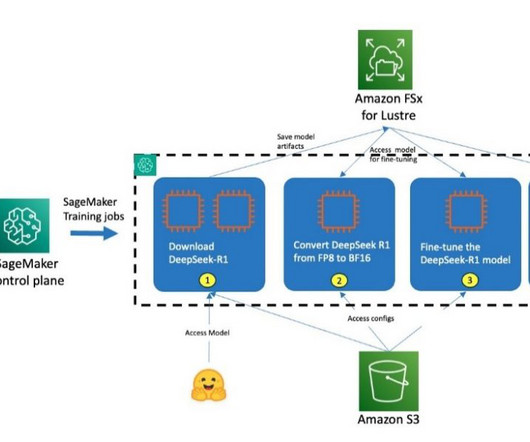
DeepSeek-R1 is a large language model (LLM) developed by DeepSeek AI that uses reinforcement learning to enhance reasoning capabilities through a multi-stage training process from a DeepSeek-V3-Base foundation. We demonstrate how to deploy these models on SageMaker AI inference endpoints.
To build a production-grade AI system today (for example, to do multilingual sentiment analysis of customer support conversations), what are the primary technical challenges? For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time.
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
We believe generative AI has the potential over time to transform virtually every customer experience we know. Innovative startups like Perplexity AI are going all in on AWS for generative AI. And at the top layer, we’ve been investing in game-changing applications in key areas like generative AI-based coding.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. Fine-tuning is quite easy.
Generative AI has emerged as a powerful tool for content creation, offering several key benefits that can significantly enhance the efficiency and effectiveness of content production processes such as creating marketing materials, image generation, content moderation etc.
Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. Download the GitHub repository Complete the following steps to download the GitHub repo: In the SageMaker notebook, on the File menu, choose New and Terminal.
Solution overview GPT NeoX and Pythia models GPT NeoX and Pythia are the open-source causal language models by Eleuther-AI with approximately 20 billion parameters in NeoX and 6.9 Next, we also evaluate the loss trajectory of the model training on AWS Trainium and compare it with the corresponding run on a P4d (Nvidia A100 GPU cores) cluster.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content