This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It allows your business to ingest continuous data streams as they happen and bring them to the forefront for analysis, enabling you to keep up with constant changes. ApacheKafka boasts many strong capabilities, such as delivering a high throughput and maintaining a high fault tolerance in the case of application failure.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigData analytics provides a competitive advantage and drives innovation across various industries.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
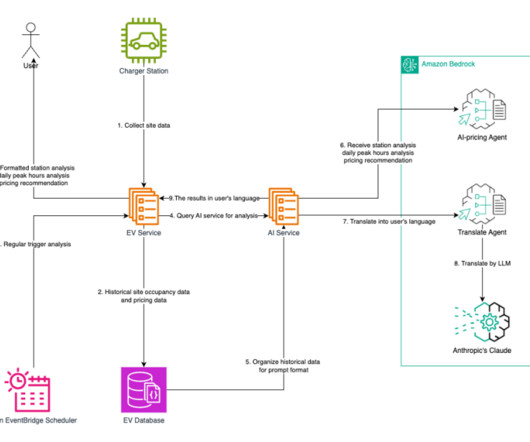
To solve this, Noodoe has integrated large language models (LLMs) through Amazon Bedrock and Amazon Bedrock Agents to deliver intelligent automation, real-time data access, and multilingual support. In this post, we explore how Noodoe uses AI and Amazon Bedrock to optimize EV charging operations.
Choosing between them depends on your systems needsRabbitMQ is best for workflows, while Kafka is ideal for event-driven architectures and bigdata processing. Two of the most popular message brokers are RabbitMQ and ApacheKafka. Kafka excels in real-time data streaming and scalability.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. offers Data Science courses covering essential data tools with a job guarantee. It integrates well with various data sources, making analysis easier.
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
CONXAI Technology GmbH is pioneering the development of an advanced AI platform for the Architecture, Engineering, and Construction (AEC) industry. Our platform uses advanced AI to empower construction domain experts to create complex use cases efficiently. These camera feeds can be analyzed using AI to extract valuable insights.
Summary: Netflix’s sophisticated BigData infrastructure powers its content recommendation engine, personalization, and data-driven decision-making. As a pioneer in the streaming industry, Netflix utilises advanced data analytics to enhance user experience, optimise operations, and drive strategic decisions.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
The concept of streaming data was born of necessity. More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. But insights derived from day-old data don’t cut it. How do streaming data pipelines work? Many scenarios call for up-to-the-minute information.
By leveraging AI for real-time event processing, businesses can connect the dots between disparate events to detect and respond to new trends, threats and opportunities. AI and event processing: a two-way street An event-driven architecture is essential for accelerating the speed of business.
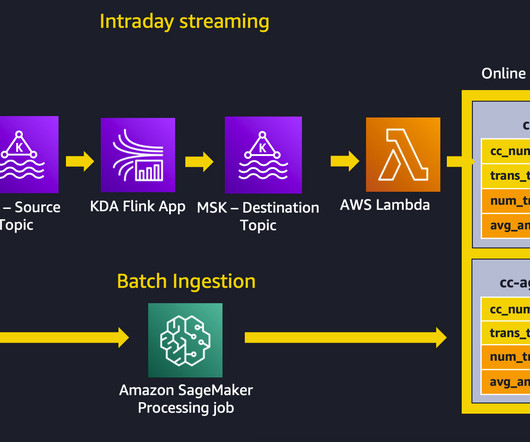
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
Summary: The future of Data Science is shaped by emerging trends such as advanced AI and Machine Learning, augmented analytics, and automated processes. As industries increasingly rely on data-driven insights, ethical considerations regarding data privacy and bias mitigation will become paramount.
The rapid evolution of AI is transforming nearly every industry/domain, and software engineering is no exception. Well, the thing is that AI technologies are doing a few things. If you’re not leveraging AI yet, it’s time to start. At West, you’ll learn even more about AI’s role in reshaping software engineering.
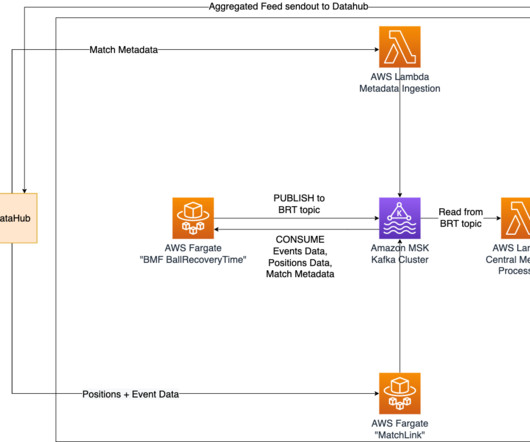
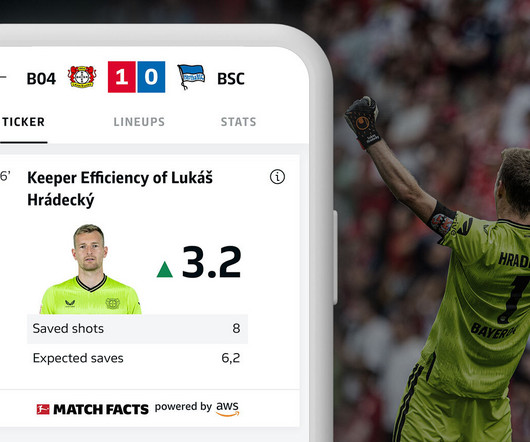
How it’s implemented Positional data from an ongoing match, which is recorded at a sampling rate of 25 Hz, is utilized to determine the time taken to recover the ball. This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time.
It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform bigdata analytics and gain valuable insights from their data. In a Hadoop cluster, data stored in the Hadoop Distributed File System (HDFS), which spreads the data across the nodes.
AI and Bias: How to Detect It and How to Prevent It Sandra Wachter, PhD | Professor, Technology and Regulation | Oxford Internet Institute, University of Oxford In recognition of the extensive biases and inequality that are present in training data, there has been much work done to test for bias in machine learning and AI systems.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration.
This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to properly manage unstructured data. The different tools used in unstructured data management. What is Unstructured Data?
Defining clear objectives and selecting appropriate techniques to extract valuable insights from the data is essential. Here are some project ideas suitable for students interested in bigdata analytics with Python: 1. Implement real-time analytics to monitor trends or anomalies in the data.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. million by 2028.
They provide flexibility in data models and can scale horizontally to manage large volumes of data. NoSQL is well-suited for bigdata applications and real-time analytics, allowing organisations to adapt to rapidly changing data landscapes. Examples include MongoDB, Cassandra, and Redis.
The machine learning model is part of the Stream processing engine, and it provides the logic that helps the streaming data pipeline expose features within the stream and potentially within a historical data store. It can be used to collect, store, and process streaming data in real-time.
The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub. The message broker can then distribute the events to various subscribers such as data processing pipelines, machine learning models, and real-time analytics dashboards. Local AI Solutions Mlearning.ai
Data Storage : To store this processed data to retrieve it over time – be it a data warehouse or a data lake. Data Consumption : You have reached a point where the data is ready for consumption for AI, BI & other analytics. Provides data security using AI & blockchain technologies.
For every xSaves prediction, it produces a message with the prediction as a payload, which then gets distributed by a central message broker running on Amazon Managed Streaming for ApacheKafka (Amazon MSK). The information also gets stored in a data lake for future auditing and model improvements.
1 Data Ingestion (e.g., ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., OpenAI, on the other hand, has been at the forefront of advancements in generative AI models, such as GPT-3, which heavily rely on embeddings. pandas, NumPy) 3 Feature Engineering and Selection (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content