

Fine-tuning large language models (LLMs) for 2025
Dataconomy
NOVEMBER 11, 2024
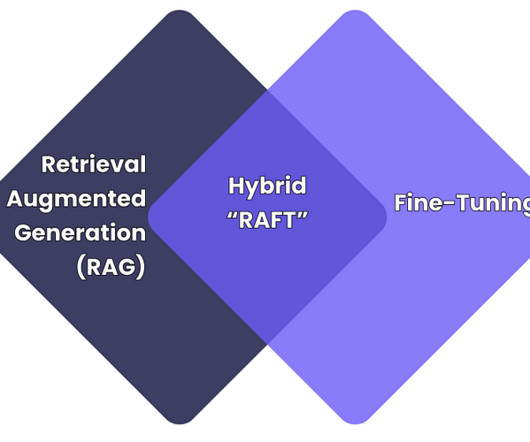
RAG helps models access a specific library or database, making it suitable for tasks that require factual accuracy. What is Retrieval-Augmented Generation (RAG) and when to use it Retrieval-Augmented Generation (RAG) is a method that integrates the capabilities of a language model with a specific library or database.
















Let's personalize your content