This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields. They cover everything from the basics like embeddings and vector databases to the newest breakthroughs in tools.
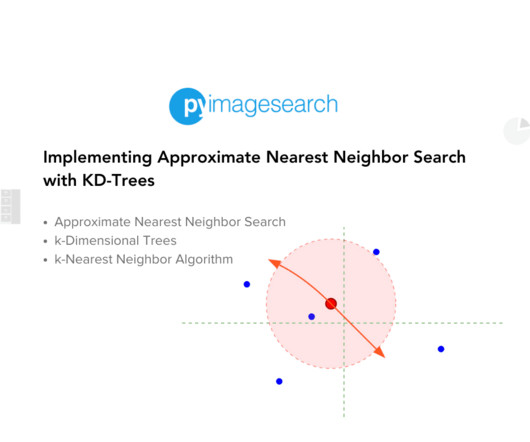
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. Imagine a database with billions of samples ( ) (e.g., So, how can we perform efficient searches in such big databases?
Last Updated on December 24, 2024 by Editorial Team Author(s): Igor Novikov Originally published on Towards AI. DatapreparationDatapreparation is a critical step, as the quality of your data directly impacts the performance and accuracy of your model. In most cases the answer is no, they dont need it.
Last Updated on November 9, 2024 by Editorial Team Author(s): Houssem Ben Braiek Originally published on Towards AI. Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Writing Output: Centralizing data into a structure, like a delta table. This member-only story is on us.
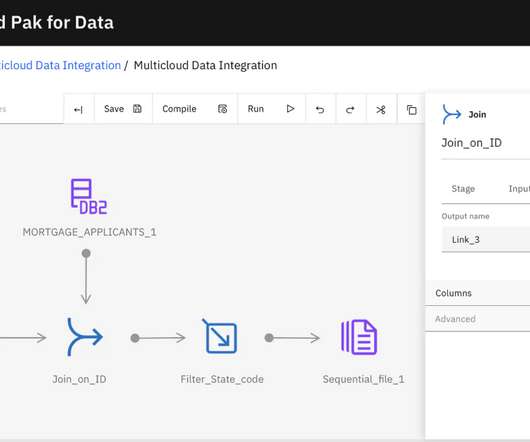
Next Generation DataStage on Cloud Pak for Data Ensuring high-quality data A crucial aspect of downstream consumption is data quality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis.
In this post, we highlight the advanced data augmentation techniques and performance improvements in Amazon Bedrock Model Distillation with Metas Llama model family. Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities.
The assistant is connected to internal and external systems, with the capability to query various sources such as SQL databases, Amazon CloudWatch logs, and third-party tools to check the live system health status. Creating ETL pipelines to transform log dataPreparing your data to provide quality results is the first step in an AI project.
Ensuring high-quality data A crucial aspect of downstream consumption is data quality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis. Let’s use address data as an example.
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
Last Updated on December 20, 2024 by Editorial Team Author(s): Towards AI Editorial Team Originally published on Towards AI. This week in Whats AI, we dive into what precisely a vector database is, how it stores and searches data, the difference between indexing and a database, and the newest trends in vector databases.
Last Updated on January 29, 2024 by Editorial Team Author(s): Cassidy Hilton Originally published on Towards AI. Recapping the Cloud Amplifier and Snowflake Demo The combined power of Snowflake and Domo’s Cloud Amplifier is the best-kept secret in data management right now — and we’re reaching new heights every day.
Optimising Power BI reports for performance ensures efficient data analysis. Power BI proficiency opens doors to lucrative data analytics and business intelligence opportunities, driving organisational success in today’s data-driven landscape. How do you load data into Power BI?
Using skills such as statistical analysis and data visualization techniques, prompt engineers can assess the effectiveness of different prompts and understand patterns in the responses. This skill focuses on minimizing the resources and time required for an LLM to generate output based on your prompts.
At ODSC Europe 2024 , Noe Achache, Engineering Manager & Generative AI Lead at Sicara, spoke about the performance challenges and outlined key lessons and best practices for creating successful, high-performing LLM-based solutions. Real-world applications often expose gaps that proper datapreparation could have preempted.
This entails breaking down the large raw satellite imagery into equally-sized 256256 pixel chips (the size that the mode expects) and normalizing pixel values, among other datapreparation steps required by the GeoFM that you choose. For scalability and search performance, we index the embedding vectors in a vector database.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
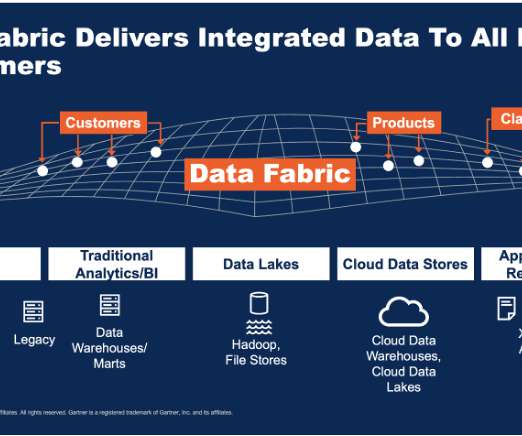
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes.
Embeddings can be stored in a database and are used to enable streamlined and more accurate searches. You can use an embeddings model in Amazon Bedrock to create vectors of your organization’s data, which can then be used to enable semantic search. Post the fastest time and you’ll win a ticket back to Vegas for the 2024 Championship!
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches. One day is usually adequate for development use.
We expect our first Trainium2 instances to be available to customers in 2024. In early 2024, customers will also be able to redact personally identifiable information (PII) in model responses. or “Should I use a relational or non-relational database?”). Which of these would be best if I want to use containers?”
It is designed to enhance the performance of generative models by providing them with highly relevant context retrieved from a large database or knowledge base. Table 1: Key Results from ViDoRe Benchmark (source: Emanuilov, 2024 ) What Is LLaVA? LLaVA (Large Language and Vision Assistant) ( Liu et al.,
billion in 2024, at a CAGR of 10.7%. R and Other Languages While Python dominates, R is also an important tool, especially for statistical modelling and data visualisation. Data Collection: Sources and Types of DataData comes in various forms , broadly categorised as structured and unstructured.
In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip. Historical data is normally (but not always) independent inter-day, meaning that days can be parsed independently. For processing the huge data volumes of FM building, PBAs are essential.
It is projected to grow at a CAGR of 34.20% in the forecast period (2024-2031). Common Challenges in DataPreparation One of the most common challenges when preparing UCI datasets is dealing with missing data. The global Machine Learning market continues to expand. It was valued at USD 35.80 billion by 2031.
Last Updated on December 24, 2024 by Editorial Team Author(s): Igor Novikov Originally published on Towards AI. DatapreparationDatapreparation is a critical step, as the quality of your data directly impacts the performance and accuracy of your model. In most cases the answer is no, they dont need it.
Standalone vector indexes like FAISS can significantly improve the search and retrieval of vector embeddings, but they lack capabilities that exist in any database. Because vector databases are built on top of vector indexes, there are additional features that typically contribute additional latency.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content