This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Modern datapipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
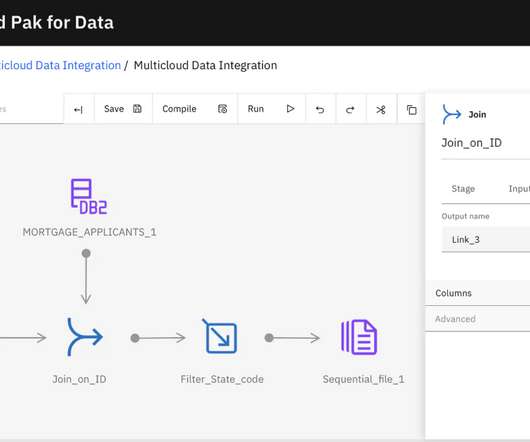
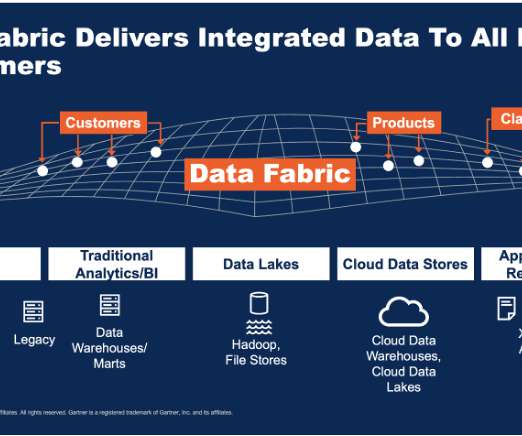
One of the key elements that builds a data fabric architecture is to weave integrated data from many different sources, transform and enrich data, and deliver it to downstream data consumers. As a part of datapipeline, Address Verification Interface (AVI) can remediate bad address data.
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
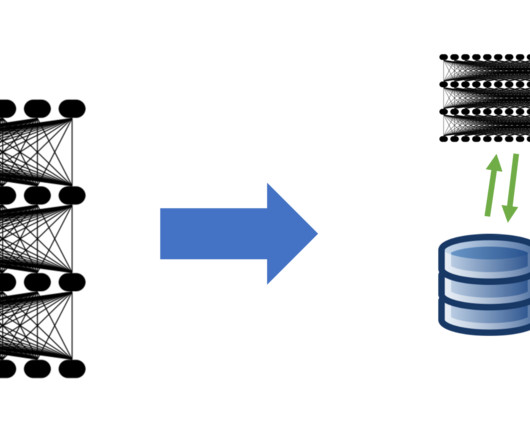
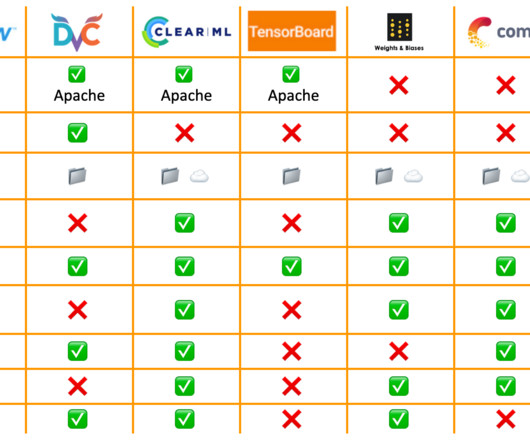
Using data versioning can make it possible to have the snapshot of the training data and experimentation results to make the implementation easier at each iteration. The above challenges can be tackled by using the following eight data version control tools. Most developers are familiar with Git for source code versioning.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
Leaders feel the pressure to infuse their processes with artificial intelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement. Indeed, IDC has predicted that by the end of 2024, 65% of CIOs will face pressure to adopt digital tech , such as generative AI and deep analytics.
With 2024 surging along, the world of AI and the landscape being created by large language models continues to evolve in a dynamic manner. Innovative AI Tools for 2024 Cosmopedia Now think about this. Whether you’re managing datapipelines or deploying machine learning models, Thunder makes the process smooth and efficient.
Last Updated on February 29, 2024 by Editorial Team Author(s): Hira Akram Originally published on Towards AI. Diagram by author As technology continues to advance, the generation of data increases exponentially. In this dynamically changing landscape, businesses must pivot towards data-driven models to maintain a competitive edge.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. This section explores essential aspects of Data Engineering.
These systems represent data as knowledge graphs and implement graph traversal algorithms to help find content in massive datasets. These systems are not only useful for a wide range of industries, they are fun for data engineers to work on. So get your pass today, and keep yourself ahead of the curve.
The recent Snowflake Summit 2024 brought plenty of exciting upcoming features, GA announcements, strategic partnerships, and many more opportunities for customers on the Snowflake AI Data Cloud to innovate. Likewise, Snowflake Summit 2024 showed no shortage of exciting upcoming features for Snowflake Cortex AI.
We argue that compound AI systems will likely be the best way to maximize AI results in the future , and might be one of the most impactful trends in AI in 2024. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably. Why Use Compound AI Systems?
Implementing Face Recognition and Verification Given that we want to identify people with id-1021 to id-1024 , we are given 1 image (or a few samples) of each person, which allows us to add the person to our face recognition database. On Lines 40 and 41 , we define the path to our face database (i.e.,
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches. One day is usually adequate for development use.
Best MLOps Tools & Platforms for 2024 In this section, you will learn about the top MLOps tools and platforms that are commonly used across organizations for managing machine learning pipelines. Data storage and versioning Some of the most popular data storage and versioning tools are Git and DVC.
DagsHub MLflow By using DagsHub’s MLflow implementation, the remote setup is done for us, eliminating the need to store experiment data locally or host the server ourselves. It additionally covers features such as live logging, experiment database, artifact storage, model registry, and deployment.
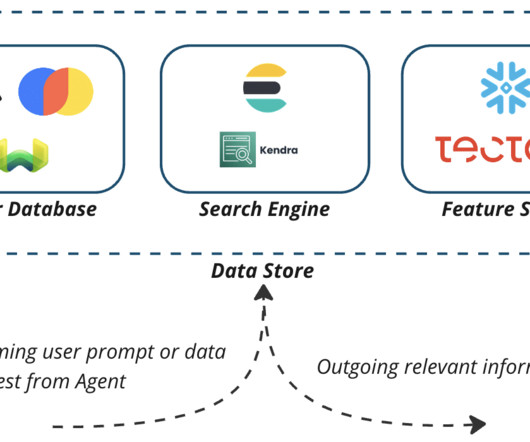
At the time of writing this blog, the year is 2024, and companies that have not yet adopted Gen AI may be feeling the pressure of being left behind. Technology Choices for Generative AI Applications Data Store Vector databases have emerged as the go-to data store solution in demos and quickstarts for generative AI applications built with RAG.
She’ll cover the distinct challenges that come with handling different data types and how modern tools can turn what feels like chaos into a manageable, streamlined architecture. Data lakes allow for the ingestion of vast amounts of data — regardless of type or format — without the need for a pre-defined schema.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. The stepsinclude: Extraction : Data is collected from multiple sources (databases, APIs, flatfiles).
This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration. Let’s unlock the power of ETL Tools for seamless data handling. Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central data warehouse.
Data engineers will also work with data scientists to design and implement datapipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. Learn more about the cloud.
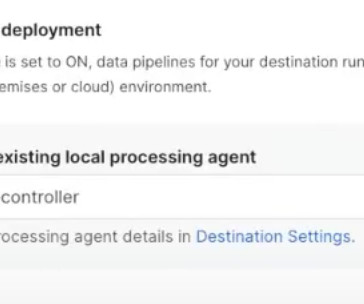
Fortunately, Fivetran’s new Hybrid Architecture addresses this security need and now these organizations (and others) can get the best of both worlds: a managed platform and pipelines processed in their own environment. What is the Hybrid Deployment Model?
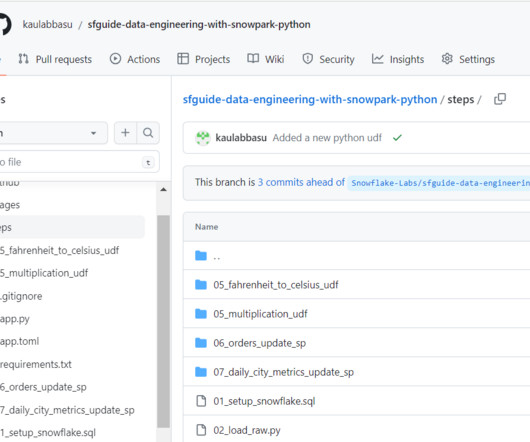
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. Validating the Deployment in Snowflake Existence – The newly created Python UDF should be present under the Analytics schema under the HOL_DB database.
From structured data sources like ERPs, CRM, and relational data stores to unstructured data such as PDFs, images, and videos, enterprises are confronted with the daunting challenge of keeping up with their ever-expanding data ecosystem. Interest in leveraging Fivetran?
Introduction Big Data continues transforming industries, making it a vital asset in 2025. The global Big Data Analytics market, valued at $307.51 billion in 2024 and reach a staggering $924.39 Companies actively seek experts to manage and analyse their data-driven strategies. billion in 2023, is projected to grow to $348.21
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. Choose an option for allowing unredacted logs for the Lambda function in the datapipeline. This allows you to control which IAM principals are allowed to decrypt the data and view it. Choose Create data source.
Open Data Science AI News Blog Recap DOD Urged to Accelerate AI Adoption Amid Rising Global Threats ( Source ) Anthropic Eyes $40 Billion Valuation in New Funding Round ( Source ) Meta to Launch AI Celebrity Voices from Judi Dench, John Cena, and Other Celebrities ( Source ) Celebrities Fall Victim to ‘Goodbye Meta AI’ Hoax as Fake Privacy Message (..)
Ref DappRadar Jan 17, 2024 Ocean Predictoor Volume vs time. Ref DappRadar Jan 17, 2024 Our main internal goal overall is to make $ trading, and then take those learnings to the community in the form of product updates, and related communications. It’s centered around a data lake with tiers from raw → refined.
This blog was originally written by Keith Smith and updated for 2024 by Justin Delisi. Snowflake’s Data Cloud has emerged as a leader in cloud data warehousing. A cloud data warehouse is designed to combine a concept that every organization knows, namely a data warehouse, and optimizes the components of it, for the cloud.
The upcoming ODSC West 2024 conference provides valuable insights into the key trends shaping the future of LLMs. 1, From Experimentation to Implementation: Building the LLM-Powered Future The theme of building and deploying LLM applications resonates strongly throughout the ODSC West 2024 lineup.
We will understand the dataset and the datapipeline for our application and discuss the salient features of the NSL framework in detail. config.py ) The datapipeline (i.e., Next, in the 3rd part of this tutorial series, we will discuss two types of adversarial attacks used to engineer adversarial examples.
We argue that compound AI systems will likely be the best way to maximize AI results in the future , and might be one of the most impactful trends in AI in 2024. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably. Why Use Compound AI Systems?
This capability is essential for businesses aiming to make informed decisions in an increasingly data-driven world. In 2024, the global Time Series Forecasting market was valued at approximately USD 214.6 billion in 2024 and is projected to reach a mark of USD 1339.1 databases, APIs, CSV files). billion by 2030.
billion and will grow to reach nearly $19 billion in 2024. How are blockchain organizations tackling data management? To learn the answer, we sat down with Karla Kirton , Data Architect at Blockdaemon, a blockchain company, to discuss data strategy , decentralization, and how implementing Alation has supported them.
In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip. An important part of the datapipeline is the production of features, both online and offline. All the way through this pipeline, activities could be accelerated using PBAs.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. Jython is to be used for database connectivity only. The default value is Python3.
Other good-quality datasets that aren’t currently FHIR but can be easily converted include Centers for Medicare & Medicaid Services (CMS) Public Use Files (PUF) and eICU Collaborative Research Database from MIT (Massachusetts Institute of Technology). He has worked with multiple federal agencies to advance their data and AI goals.
2024 thus stands to be a pivotal year for the future of AI, as researchers and enterprises seek to establish how this evolutionary leap in technology can be most practically integrated into our everyday lives. As the pace of progress accelerates, the ever-expanding capabilities of state-of-the-art models will garner the most media attention.
An example of naming intermediate sub-directory and model file name Models The example below illustrates that intermediate models do not need to be physically present in the target database. Staging models are believed to be the atomic units for data modeling and hold transformed source data as per the requirements.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. What Does a Data Engineer Do?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content