This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Last Updated on April 11, 2024 by Editorial Team Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors.
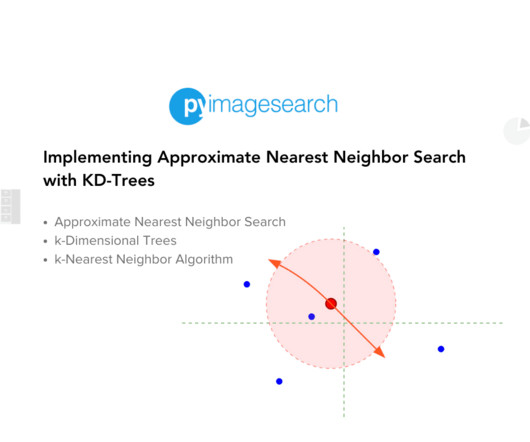
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate NearestNeighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
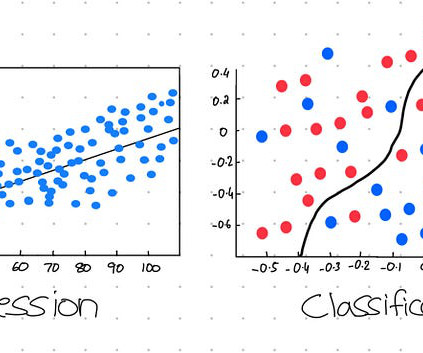
Last Updated on September 3, 2024 by Editorial Team Author(s): Surya Maddula Originally published on Towards AI. Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. This member-only story is on us.
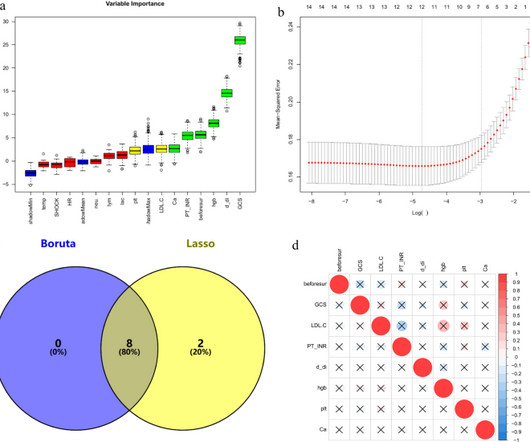
The analysis included 218 patients admitted to Qilu Hospital of Shandong University from July 2011 to April 2024. Feature selection via the Boruta and LASSO algorithms preceded the construction of predictive models using Random Forest, Decision Tree, K-NearestNeighbors, Support Vector Machine, LightGBM, and XGBoost.
Last Updated on May 1, 2024 by Editorial Team Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. We shall look at various types of machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code.
Using Guardrails for Trustworthy AI, Projected AI Trends for 2024, and the Top Remote AI Jobs in 2024 How to Use Guardrails to Design Safe and Trustworthy AI In this article, you’ll get a better understanding of guardrails within the context of this post and how to set them at each stage of AI design and development.
Last Updated on May 13, 2024 by Editorial Team Author(s): Cristian Rodríguez Originally published on Towards AI. Ensemble models can be generated using a single algorithm with numerous variations, known as a homogeneous ensemble, or by using different techniques, known as a heterogeneous ensemble [3].
Last Updated on April 4, 2024 by Editorial Team Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. Created by the author with DALL E-3 Machine learning algorithms are the “cool kids” of the tech industry; everyone is talking about them as if they were the newest, greatest meme.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. The goal is to index these five webpages dynamically using a common embedding algorithm and then use a retrieval (and reranking) strategy to retrieve chunks of data from the indexed knowledge base to infer the final answer.
Last Updated on January 29, 2024 by Editorial Team Author(s): Shivamshinde Originally published on Towards AI. Examples of hyperparameters for algorithms Advantages and Disadvantages of hyperparameter tuning How to perform hyperparameter tuning?– kernel: This hyperparameter decides which kernel to be used in the algorithm.
Top Python Libraries of 2023 and 2024 NumPy NumPy is the gold standard for scientific computing in Python and is always considered amongst top Python libraries. Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many data scientists.
The global Machine Learning market is rapidly growing, projected to reach US$79.29bn in 2024 and grow at a CAGR of 36.08% from 2024 to 2030. Types of inductive bias include prior knowledge, algorithmic bias, and data bias. This bias allows algorithms to make informed guesses when faced with incomplete or sparse data.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Looking for the source code to this post?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content