This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here, we outline the essential skills and qualifications that pave way for data science careers: Proficiency in Programming Languages – Mastery of programming languages such as Python, R, and SQL forms the foundation of a data scientist’s toolkit.
Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift. Learn more about these new generative AI features to increase productivity including Amazon Q generative SQL in Amazon Redshift. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
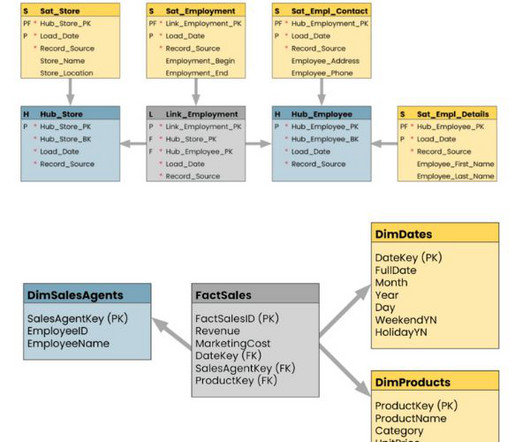
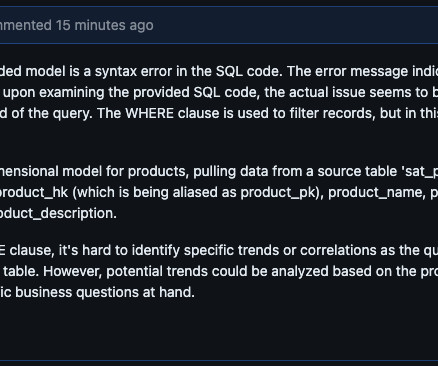
Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL. But why is SQL, or Structured Query Language , so important to learn? Let’s start with the first clause often learned by new SQL users, the WHERE clause.
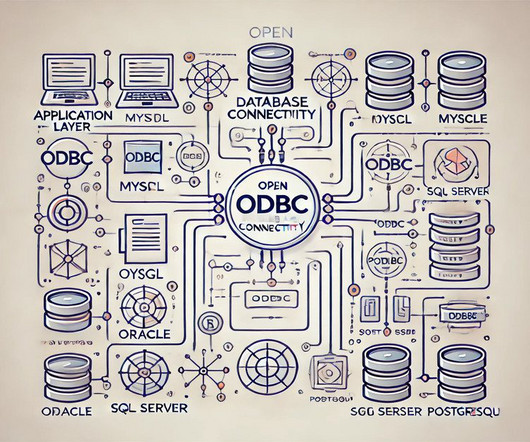
billion in 2023, is projected to grow at a remarkable CAGR of 19.50% from 2024 to 2032. Each database type requires its specific driver, which interprets the application’s SQL queries and translates them into a format the database can understand. The ODBC market , valued at USD 1.5 INSERT : Add new records to a table.
It allows developers to easily connect to databases, execute SQL queries, and retrieve data. It operates as an intermediary, translating Java calls into SQL commands the database understands. million in 2023 and is projected to reach $9,049.24 billion in 2023 and is expected to reach $186.97 from 2023 to 2030.
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provides a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. What is Matillion ETL?
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provide a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. In our case, this table is “orders.”
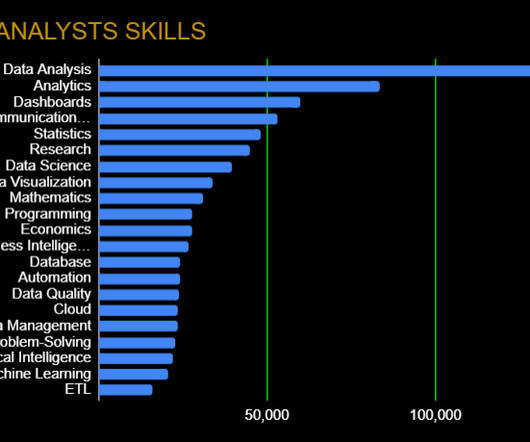
We looked at over 25,000 job descriptions, and these are the data analytics platforms, tools, and skills that employers are looking for in 2023. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. As part of the initial ETL, this raw data can be loaded onto tables using AWS Glue.
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. This allowed them to focus on SQL-based query optimization to the nth degree. What is Presto?
Redefining cloud database innovation: IBM and AWS In late 2023, IBM and AWS jointly announced the general availability of Amazon relational database service (RDS) for Db2. Unlock competitive advantages with accelerated data insights through an AI-powered conversational interface, with no SQL expertise required.
The said destination could be a reverse ETL pattern for an operational system, a data lake for machine learning or data science , or an extract process to copy data to an Access database for end users—the goal is to identify if these destinations will need support from the Snowflake platform. SQL Server Agent jobs).
Kuber Sharma Director, Product Marketing, Tableau Kristin Adderson August 22, 2023 - 12:11am August 22, 2023 Whether you're a novice data analyst exploring the possibilities of Tableau or a leader with years of experience using VizQL to gain advanced insights—this is your list of key Tableau features you should know, from A to Z.
Context In early 2023, Zeta’s machine learning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Snowflake Cortex stood out as the ideal choice for powering the model due to its direct access to data, intuitive functionality, and exceptional performance in handling SQL tasks. Looking at the SQL code, it appears that CONTRACT_BREAK is hardcoded as a constant value ‘1’ in the final SELECT statement.
Example template for an exploratory notebook | Source: Author How to organize code in Jupyter notebook For exploratory tasks, the code to produce SQL queries, pandas data wrangling, or create plots is not important for readers. In those cases, most of the data exploration and wrangling will be done through SQL. documentation.
What are the best data preprocessing tools of 2023? In 2023, several data preprocessing tools have emerged as top choices for data scientists and analysts. Toad Data Point Toad Data Point is a user-friendly tool that makes querying and updating data with SQL simple and efficient.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity. billion in 2023 and is projected to reach USD 55.96 billion in 2023 and is projected to grow from USD 218.33 The global data storage market was valued at USD 186.75
As Netezza creeps closer to its end-of-life date in early 2023, you may be looking for options to migrate to, this post will provide valuable insights into why Snowflake may be the best choice. Complete SQL Database No need to learn new tools as Snowflake supports the tools millions of business users already know how to use today.
For example, you can use alerts to send notifications, capture data, or execute SQL commands when certain events or thresholds are reached in your data. As Snowflake’s 2023 Partner of the Year , phData has unmatched experience with Snowflake migrations, platform management, automation needs, and machine learning foundations.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
Here’s what you’ll discover: Diverse Data Sources: Learn to import not just plain text files but also data from a variety of other software formats, including Excel spreadsheets, SQL, and relational databases. Importing from SQL databases Python has excellent support for interacting with databases.
Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. It’s not a widely known programming language like Java, Python, or SQL. ECL sounds compelling, but it is a new programming language and has fewer users than languages like Python or SQL.
The next generation of Db2 Warehouse SaaS and Netezza SaaS on AWS fully support open formats such as Parquet and Iceberg table format, enabling the seamless combination and sharing of data in watsonx.data without the need for duplication or additional ETL. Information about potential future products may not be incorporated into any contract.
Related article How to Build ETL Data Pipelines for ML See also MLOps and FTI pipelines testing Once you have built an ML system, you have to operate, maintain, and update it. Reference table for which technologies to use for your FTI pipelines for each ML system. Typically, these activities are collectively called “ MLOps.”
More about Neptune: Working with artifacts: versioning datasets in runs How to version datasets or models stored in the S3 compatible storage Dolt Dolt is a SQL database that is created for versioning and sharing data. With lakeFS it is possible to test ETLs on top of production data, in isolation, without copying anything.
billion in 2023 and may grow at a CAGR of 14.9% Hive leverages HDFS to host structured tables, enabling analytical queries through a familiar SQL interface. Below are two prominent scenarios: Batch Data Processing Scenarios Companies use HDFS to handle large-scale ETL ( Extract, Transform, Load ) tasks and offline analytics.
The Ultimate Modern Data Stack Migration Guide phData Marketing July 18, 2023 This guide was co-written by a team of data experts, including Dakota Kelley, Ahmad Aburia, Sam Hall, and Sunny Yan. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. Related post MLOps Landscape in 2023: Top Tools and Platforms Read more Why have a DAG within a DAG?
The Data Engineer has an IAM ETL role and runs the extract, transform, and load (ETL) pipeline using Spark to populate the Lakehouse catalog on RMS. The Data Warehouse Admin has an IAM admin role and manages databases in Amazon Redshift. Clear the checkbox Use only IAM access control for new tables in this database.
database permissions, ETL capability, processing, etc.), it has to be done using custom SQL in Tableau? Hopefully, you don’t run into this scenario because joining and querying multiple tables in Tableau using custom SQL is not recommended due to its impact on performance.
Relational databases use SQL for querying, which can be complex and rigid. Explain The Difference Between MongoDB and SQL Databases. MongoDB is a NoSQL database that stores data in documents, while SQL databases store data in tables with rows and columns. Documents are stored in collections, analogous to SQL database tables.
In transitional modeling, we’d add new atoms: Subject: Customer#1234 Predicate: hasEmailAddress Object: "john.new@example.com" Timestamp: 2023-07-24T10:00:00Z The old email address atoms are still there, giving us a complete history of how to contact John. Extract, Load, and Transform (ELT) using tools like dbt has largely replaced ETL.
Even if your current pipelines dont need Icebergs full set of capabilities, the shift from file-centric Parquet writes to table-aware Iceberg writes can significantly reduce your query execution costs, especially when used with Athena or Spark SQL. Seamless support with DynamicFrames, Spark SQL, and Glue Studio. No custom JARs.
Through practical examples with AWS Glue jobs, this blog demonstrates how to query Icebergs metadata tables using SQL and turn hidden information into actionable insights. The ETL Pipeline failed in PROD. Theyre actual system tables equivalent that can be queried with SQL, providing detailed visibility into your data.
Dakota Kelley serving his homemade BBQ for the entire US phData team at the 2023 picnic Curiosity Curiosity is important in any career because it promotes creative problem-solving, helps you adapt to change, and allows you to explore new perspectives, ultimately leading to a more dynamic work environment.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content