This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world’s leading publication for data science, AI, and ML professionals. You don’t need deep ML knowledge or tuning skills. Why Automate ML Model Selection? It’s not just convenient, it’s smart ML hygiene. Libraries We Will Use We will be exploring 2 underrated Python ML Automation libraries.
Last Updated on June 14, 2023 by Editorial Team Author(s): Jan Marcel Kezmann Originally published on Towards AI. Data is the lifeblood of ML and DL models, serving as the foundation upon which they learn and make predictions. But the question of how to best utilize that data remains a topic of debate.
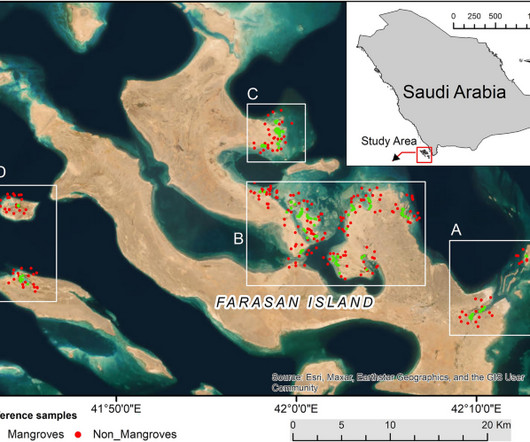
This study used 2023 Landsat 8 SR data within the Google Earth Engine (GEE) platform to classify mangrove and non-mangrove areas in the Farasan Islands Protected Area in Saudi Arabia. Mangroves provide essential ecological benefits, and accurate classification is vital for their protection. and a kappa coefficient (KC) of 0.84. OA and 0.76
Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. The cross-validations for all winners were reproduced by the DrivenData team. Lower is better. Unsurprisingly, the 0.10 quantile was easier to predict than the 0.90
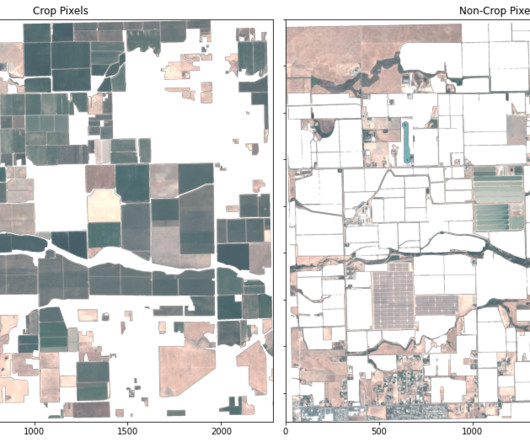
In late 2023, Planet announced a partnership with AWS to make its geospatial data available through Amazon SageMaker. In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Planet’s data is therefore a valuable resource for geospatial ML.
Last Updated on August 17, 2023 by Editorial Team Author(s): Jeff Holmes MS MSCS Originally published on Towards AI. In fact, AI/ML graduate textbooks do not provide a clear and consistent description of the AI software engineering process. When the agent is a computer, the learning process is called machine learning (ML) [6, p.
Results of the Hindcast Stage ¶ The Water Supply Forecast Rodeo is being held over multiple stages from October 2023 through July 2024. Also, I have 10 years of experience with C++ cross-platform development, especially in the medical imaging domain, and for embedded solutions. Image courtesy of USBR.
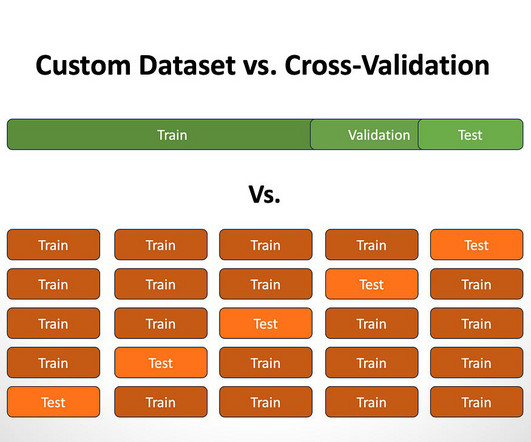
Figure 1: Brute Force Search It is a cross-validation technique. Figure 2: K-fold CrossValidation On the one hand, it is quite simple. Running a cross-validation model of k = 10 requires you to run 10 separate models. Available at: [link] (Accessed: 8 February 2023). Johnston, B. and Mathur, I.
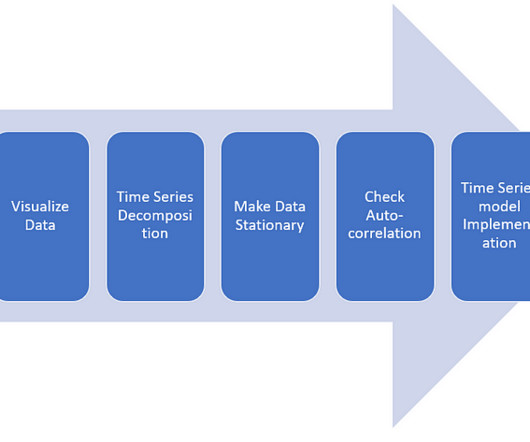
Last Updated on July 19, 2023 by Editorial Team Author(s): Yashashri Shiral Originally published on Towards AI. Sales Prediction| Using Time Series| End-to-End Understanding| Part -2 Sales Forecasting determines how the company invests and grows to create a massive impact on company valuation.
AI / ML offers tools to give a competitive edge in predictive analytics, business intelligence, and performance metrics. By leveraging cross-validation, we ensured the model’s assessment wasn’t reliant on a singular data split.
Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. As businesses increasingly rely on ML to gain insights and improve decision-making, the demand for skilled professionals surges. This growth signifies Python’s increasing role in ML and related fields.
The data we use for this challenge is Miami's historical METAR logs from 2014–2023. Challenge Overview Objective : Building upon the insights gained from Exploratory Data Analysis (EDA), participants in this data science competition will venture into hands-on, real-world artificial intelligence (AI) & machine learning (ML).
For example, if you are using regularization such as L2 regularization or dropout with your deep learning model that performs well on your hold-out-cross-validation set, then increasing the model size won’t hurt performance, it will stay the same or improve. The only drawback of using a bigger model is computational cost. deeplearning.ai/machine-learning-yearning-book
The platform accomplishes this by using a combination of no-code visual tools, for your code-averse analysts, and code-first options, for your seasoned ML practitioners. Dataiku added Prophet as a built-in algorithm for time-series analysis in Dataiku 12, which was released in late May 2023.
The platform accomplishes this by using a combination of no-code visual tools, for your code-averse analysts, and code-first options, for your seasoned ML practitioners. Dataiku added Prophet as a built-in algorithm for time-series analysis in Dataiku 12, which was released in late May 2023.
The time has come for us to treat ML and AI algorithms as more than simple trends. We are no longer far from the concepts of AI and ML, and these products are preparing to become the hidden power behind medical prediction and diagnostics. Techniques like cross-validation and robust evaluation methods are crucial.
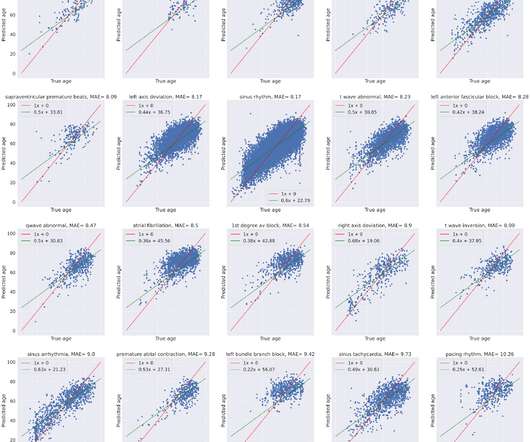
The use of Jupyter Notebooks was done in order to make it possible to train and validate the models on Google Colab in order to get access to free GPUs. doing cross-validation on the training set and a mean absolute error of 8.3 Proceedings of the Northern Lights Deep Learning Workshop 4 , (2023). years on the test set.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content