This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
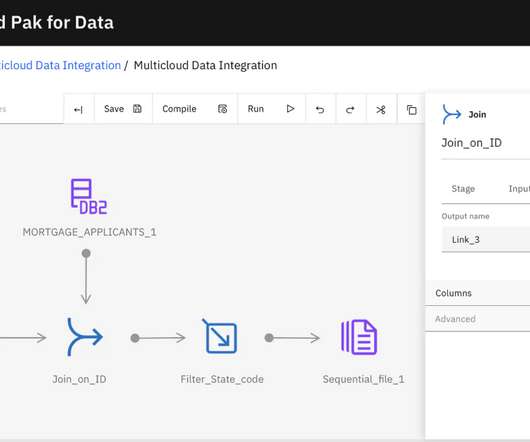
IBM Multicloud Data Integration helps organizations connect data from disparate sources, build data pipelines, remediate data issues, enrich data, and deliver integrated data to multicloud platforms where it can easily accessed by data consumers or built into a data product.
IBM Multicloud Data Integration helps organizations connect data from disparate sources, build data pipelines, remediate data issues, enrich data, and deliver integrated data to multicloud platforms where it can easily accessed by data consumers or built into a data product.
As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. The global Big Data and Data Engineering Services market, valued at USD 51,761.6 million in 2022, is projected to grow at a CAGR of 18.15% , reaching USD 140,808.0
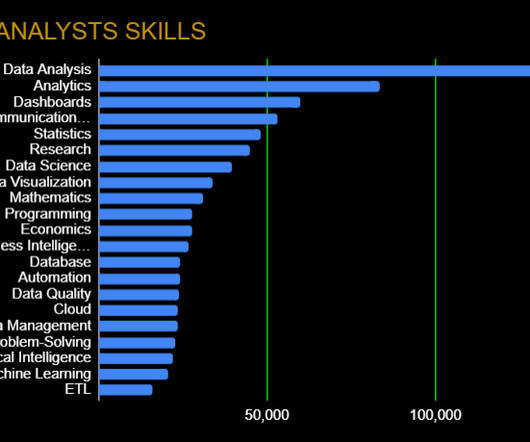
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. Section 4: Reporting data for the project insights. ETL ARCHITECTURE DIAGRAM ETL stands for Extract, Transform, Load.
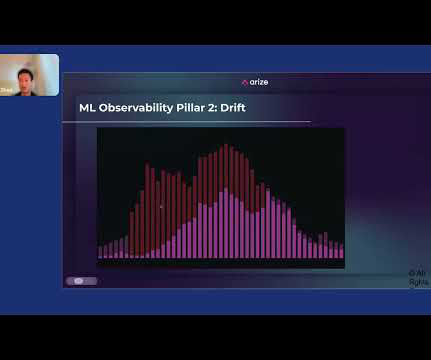
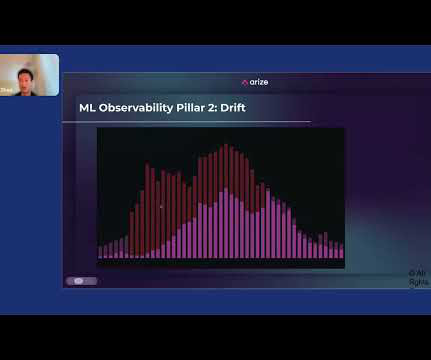
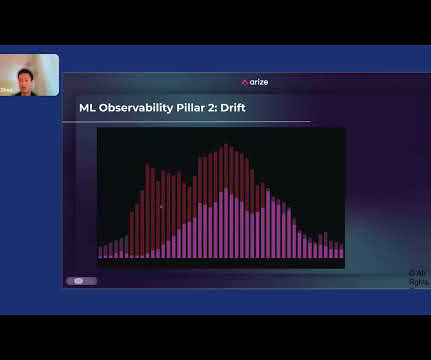
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. Then there’s dataquality, and then explainability.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. Then there’s dataquality, and then explainability.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. Then there’s dataquality, and then explainability.
DataQuality Good testing is an essential part of ensuring the integrity and reliability of data. Without testing, it is difficult to know whether the data is accurate, complete, and free of errors. Below, we will walk through some baseline tests every team could and should run to ensure dataquality.
To overcome this, you can specify the desired data types, ensuring accurate data representation: >>> import pandas as pd # Read CSV file with specific data types >>> data = pd.read_csv(‘data.csv’, dtype = {‘column_name’: int}) # Access the data >> print(data.head()) Exploring Your Data in Python (..)
AI Today ChatGPT was released on November 30, 2022, and has since been coined the fastest-growing app in internet history. You don’t need massive data sets because “dataquality scales better than data size.”
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content