This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
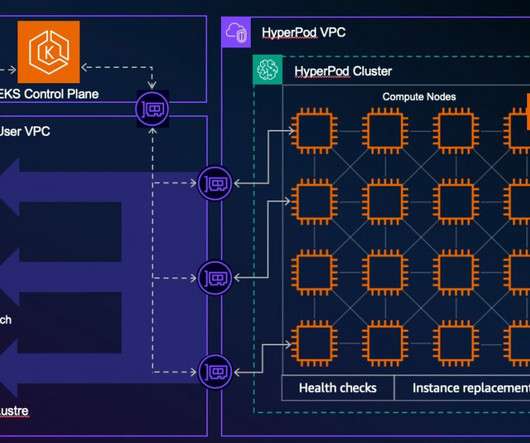
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. At the time, I knew little about AI or machinelearning (ML). Despite this, exciting events like the AWS DeepRacer F1 Pro-Am kept the community engaged.
Under Settings , enter a name for your database cluster identifier. You can verify the output by cross-referencing the PDF, which has a target as $12 million for the in-store sales channel in 2020. Delete the Aurora MySQL instance and Aurora cluster. Choose Create database. Select Aurora , then Aurora (MySQL compatible).
From artificial intelligence and machinelearning to blockchains and data analytics, big data is everywhere. Software businesses are using Hadoop clusters on a more regular basis now. MachineLearning. Machinelearning is a trending field and a hot topic right now. Big Data Skillsets.
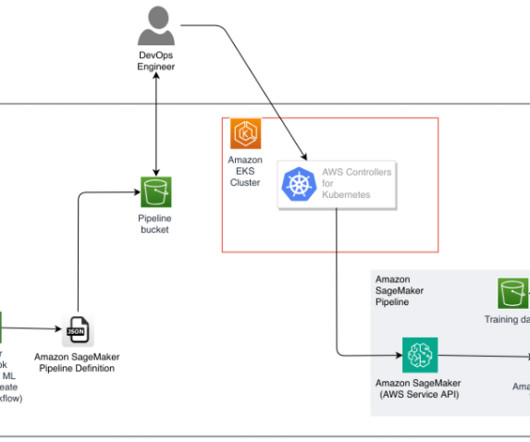
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machinelearning (ML) applications. ACK allows you to take advantage of managed model building pipelines without needing to define resources outside of the Kubernetes cluster. kubectl for working with Kubernetes clusters.
In fact, studies by the Gigabit Magazine depict that the amount of data generated in 2020 will be over 25 times greater than it was 10 years ago. AI and machinelearning & Cloud-based solutions may drive future outlook for data warehousing market. The amount of data being generated globally is increasing at rapid rates.
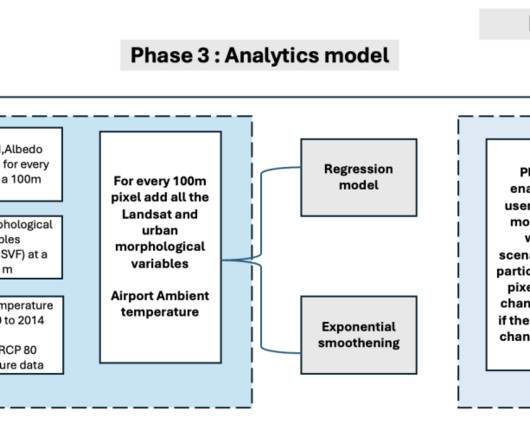
SageMaker geospatial capabilities make it straightforward for data scientists and machinelearning (ML) engineers to build, train, and deploy models using geospatial data. Among these models, the spatial fixed effect model yielded the highest mean R-squared value, particularly for the timeframe spanning 2014 to 2020.
Detecting drought in January 2020 (on the left) using the EVI vegetation index Yellow means very healthy vegetation while dark green means unhealthy. Clustering similar fields using unsupervised K-means clustering The outcome of K-means clustering is cluster labels that assign each data point to one of the K clusters.
As a result, machinelearning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Aligning SMP with open source PyTorch Since its launch in 2020, SMP has enabled high-performance, large-scale training on SageMaker compute instances. To mitigate this problem, SMP v2.0
Starting June 7th, both Falcon LLMs will also be available in Amazon SageMaker JumpStart, SageMaker’s machinelearning (ML) hub that offers pre-trained models, built-in algorithms, and pre-built solution templates to help you quickly get started with ML. The model weights are available to download, inspect and deploy anywhere.
Temperature observation at 1pm UTC on June 15, 2020 Wind speed observation at 1pm UTC on June 15, 2020 Data usage Most of our clients use weather data as a variable in their linear regression model and other machinelearning models. June 2020 is ~540 GB). write.mode(params["mode"]).format(params["output"]).save(params["dest"])
Machinelearning The 6 key trends you need to know in 2021 ? They bring deep expertise in machinelearning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Download the free, unabridged version here.
The standard cells are then collected into clusters to help speed up the training process. Recall that, as a preprocessing step, the reinforcement learning method gathers up the standard cells into clusters. The macro-placing reinforcement learning portion has no knowledge of the initial placement, they say.
Image recognition is one of the most relevant areas of machinelearning. Deep learning makes the process efficient. In 2020, our team launched DataRobot Visual AI. We embedded best practices and various deep learning models to support image data. Multimodal Clustering. DataRobot Visual AI.
Authors of AntMan [1] propose a deep learning infrastructure, which is a co-design of cluster schedulers (e.g., with deep learning frameworks (e.g., Their motivation for this work was their observation on very low GPU utilization on Alibaba cluster. AntMan: Dynamic scaling on GPU clusters for deep learning.
The Story of the Name Patrick Lewis, lead author of the 2020 paper that coined the term , apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI.
Sentence transformers are powerful deep learning models that convert sentences into high-quality, fixed-length embeddings, capturing their semantic meaning. These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machinelearning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. Journal of machinelearning research 9, no.
SOTA (state-of-the-art) in machinelearning refers to the best performance achieved by a model or system on a given benchmark dataset or task at a specific point in time. The earlier models that were SOTA for NLP mainly fell under the traditional machinelearning algorithms. 2020) “GPT-4 Technical report ” by Open AI.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. It involves training a global machinelearning (ML) model from distributed health data held locally at different sites. 2020): e0235424. Plos one 15.7
Custom geospatial machinelearning : Fine-tune a specialized regression, classification, or segmentation model for geospatial machinelearning (ML) tasks. Points clustered closely on the y-axis indicate similar ground conditions; sudden and persistent discontinuities in the embedding values signal significant change.
Today, entire industries are looking to leverage the availability of complex space technologies and insights — from reusable rocket launchers to the use of open-source machinelearning pipelines — to accelerate a new era of commercial space applications.
JumpStart is a machinelearning (ML) hub that can help you accelerate your ML journey. in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. RAG models were introduced by Lewis et al.
The strategic value of IoT development and data analytics Sierra Wireless Sierra Wireless , a wireless communications equipment designer and service provider, has been honing its focus on IoT software and managed services following its acquisition of M2M Group, a cluster of companies dedicated to IoT connectivity, in 2020.
The Snowflake Data Cloud was unveiled in 2020 as the next iteration of Snowflake’s journey to simplify how organizations interact with their data. What is the Snowflake Data Cloud? The Data Cloud applies technology to solve data problems that exist with every customer, namely; availability, performance, and access.
The seeds of a machinelearning (ML) paradigm shift have existed for decades, but with the ready availability of virtually infinite compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are rapidly adopting and using ML technologies to transform their businesses.
in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. He focuses on developing scalable machinelearning algorithms. RAG models were introduced by Lewis et al.
These activities cover disparate fields such as basic data processing, analytics, and machinelearning (ML). Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern.
Fight sophisticated cyber attacks with AI and ML When “virtual” became the standard medium in early 2020 for business communications from board meetings to office happy hours, companies like Zoom found themselves hot in demand. A basic example of an application of machinelearning in cybersecurity is the spam filter in email inboxes.
For example, rising interest rates and falling equities already in 2013 and again in 2020 and 2022 led to drawdowns of risk parity schemes. His interests are financial markets, asset management, and machinelearning applications.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
The model is trained on gameplay data from Bleeding Edge, a 2020 multiplayer game developed by NinjaTheory. Development The development of Muse was driven by advances in machinelearning and the need to scale model training. The release marks a significant step toward integrating generative AI into game design.
Even modern machinelearning applications should use visual encoding to explain data to people. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Gestalt properties including clusters are salient on scatters. Let’s take a look at each. . Query innovation.
Iris was designed to use machinelearning (ML) algorithms to predict the next steps in building a data pipeline. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machinelearning.
For decades, Amazon has pioneered and innovated machinelearning (ML), bringing delightful experiences to its customers. Similar to the rest of the industry, the advancements of accelerated hardware have allowed Amazon teams to pursue model architectures using neural networks and deep learning (DL). You can find him on LinkedIn.
If you havent installed it yet, follow this step-by-step guide: Getting Started with Docker for MachineLearning. e "discovery.type=single-node" : Runs OpenSearch as a single-node cluster (since were not setting up a distributed system locally). pandas==2.0.3 tqdm==4.66.1 pyarrow==14.0.2
Machinelearning (ML) methods can help identify suitable compounds at each stage in the drug discovery process, resulting in more streamlined drug prioritization and testing, saving billions in drug development costs (for more information, refer to AI in biopharma research: A time to focus and scale ).
JumpStart is the machinelearning (ML) hub of Amazon SageMaker that offers a one-click access to over 350 built-in algorithms; pre-trained models from TensorFlow, PyTorch, Hugging Face, and MXNet; and pre-built solution templates. He focuses on developing scalable machinelearning algorithms.
Machinelearning is a popular choice here. I tried several other machinelearning classifiers, but SVM turned out to be the best. Furthermore, it involves just dot-products, a fast operation for nowadays machines to carry on. Of course, any machinelearning algorithm requires a proper dataset to train on.
Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machinelearning. Machinelearning collaboration Gigaforce allocates work based on the phase of the project.
AI Engineers focus primarily on implementing and deploying AI models and algorithms, working closely with data scientists and machinelearning experts. Model Selection and Optimization Identifying appropriate machinelearning models and techniques, fine-tuning parameters, and optimizing the performance of AI systems.
Even modern machinelearning applications should use visual encoding to explain data to people. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Gestalt properties including clusters are salient on scatters. Let’s take a look at each. . Query innovation.
[link] Ahmad Khan, head of artificial intelligence and machinelearning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
[link] Ahmad Khan, head of artificial intelligence and machinelearning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content