This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Azure Data Studio has rapidly gained popularity among developers and database administrators for its user-friendly design and powerful features. As a versatile tool, it simplifies the management of both SQL Server and Azure SQL databases, offering a modern alternative to traditional database management solutions.
Fastweb , one of Italys leading telecommunications operators, recognized the immense potential of AI technologies early on and began investing in this area in 2019. During the training process, our SageMaker HyperPod cluster was connected to this S3 bucket, enabling effortless retrieval of the dataset elements as needed.
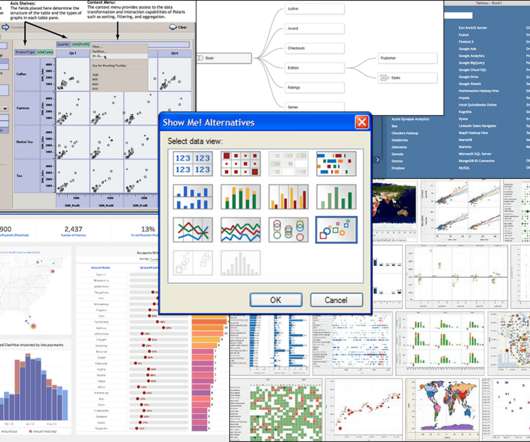
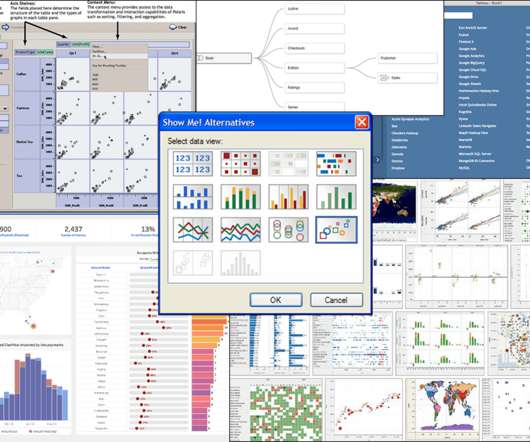
The Salesforce purchase in 2019. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first EOM contract with the database company Hyperion—that’s when I was hired.
Partitioning and clustering features inherent to OTFs allow data to be stored in a manner that enhances query performance. 2019 - Delta Lake Databricks released Delta Lake as an open-source project. This is invaluable in big data environments, where unnecessary scans can significantly drain resources.
The Salesforce purchase in 2019. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first OEM contract with the database company Hyperion—that’s when I was hired.
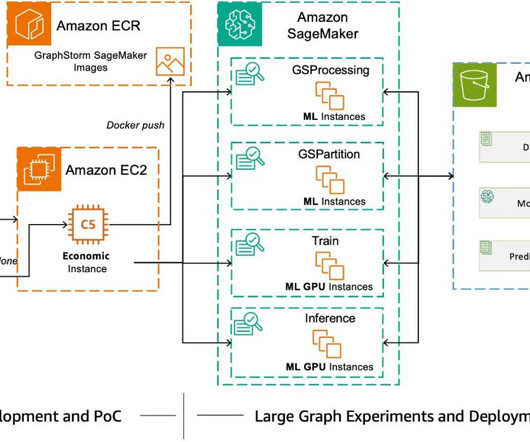
Although GraphStorm can run efficiently on single instances for small graphs, it truly shines when scaling to enterprise-level graphs in distributed mode using a cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances or Amazon SageMaker. Today, AWS AI released GraphStorm v0.4.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. Claude 3 Sonnet is the next generation of state-of-the-art models from Anthropic.
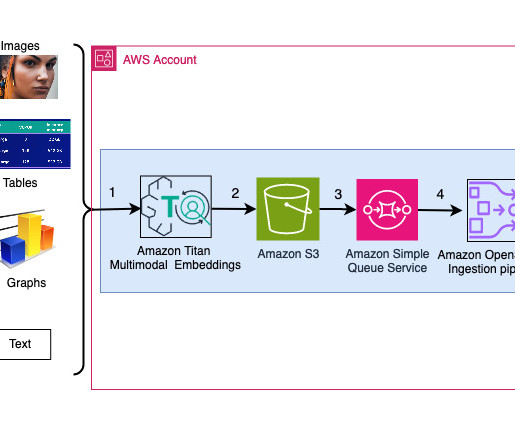
For scalability and search performance, we index the embedding vectors in a vector database. Step 4: Consolidation and vector database integration The final pipeline step consolidates the processed embeddings into a unified dataset and loads them into vector databases optimized for similarity search.
Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. Customers are telling us that Neuron has made it easy for them to switch their existing model training and inference pipelines to Trainium and Inferentia with just a few lines of code.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor data quality and availability. One way to address this is to implement a data lake: a large and complex database of diverse datasets all stored in their original format.
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 degree in AI and ML specialization from Gujarat University, earned in 2019. bge-small-en-v1.5 He holds an M.S.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. The Inferentia chip became generally available (GA) in December 2019, followed by Trainium GA in October 2022, and Inferentia2 GA in April 2023.
To give a sense for the change in scale, the largest pre-trained model in 2019 was 330M parameters. Second, customers want integration into applications to be seamless, without having to manage huge clusters of infrastructure or incur large costs. Today’s FMs, such as the large language models (LLMs) GPT3.5
GraphViz [Graphviz] has important applications in networking, bioinformatics, software engineering, database and web design, machine learning, and in visual interfaces for other technical domains. Format: Open source automatic graph drawing/design tool that uses a simple graph description language (DOT) for nodes, edges, clusters etc.
Clustering health aspects ? The ICD-11 (International Classification of Diseases) is a database that holds a wide variety of health information about diseases and symptoms. Clustering health aspects Health aspects can have many synonyms or similar contexts such as: ” sore throat ”, ” itchy throat ”, or ” swollen throat ”.
And in a similar vein, we can expect LLMs to be useful in making connections to external databases, functions, etc. but with things like clustering). We introduced it in 2019 as a way to make specific, individual contributed functions available in the Wolfram Language. But in Version 14.0
OnPrem - Geospatial database D2. OnPrem - SAP database D4. OnCloud - Large mirror database D10. OnPrem - LotusNotes database D11. OnPrem - LotusNotes database D11. OnPrem - IBM BPM database D12. In 2000s many of our systems were built on top of IBM Lotus Notes databases. OnPrem - Sharepoint D7.
Solvers submitted a wide range of methodologies to this end, including using open-source and third party LLMs (GPT, LLaMA), clustering (DBSCAN, K-Means), dimensionality reduction (PCA), topic modeling (LDA, BERT), sentence transformers, semantic search, named entity recognition, and more. and DistilBERT.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









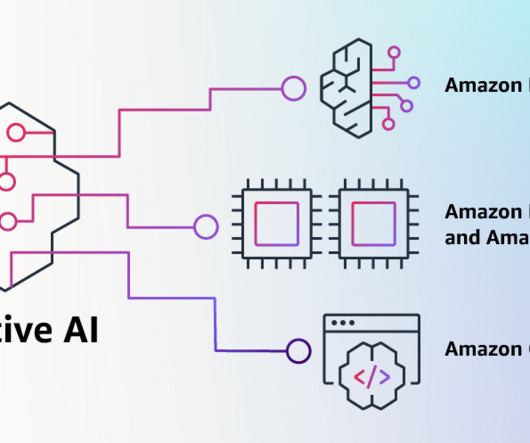

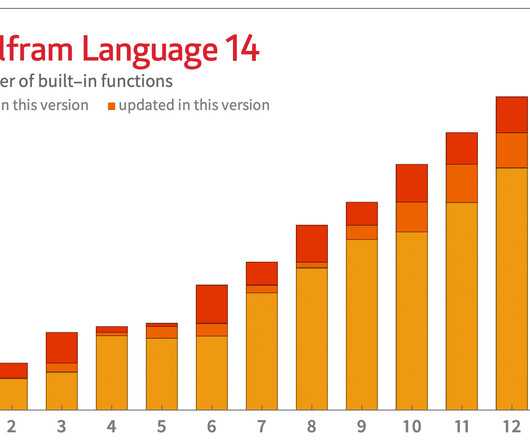









Let's personalize your content