This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
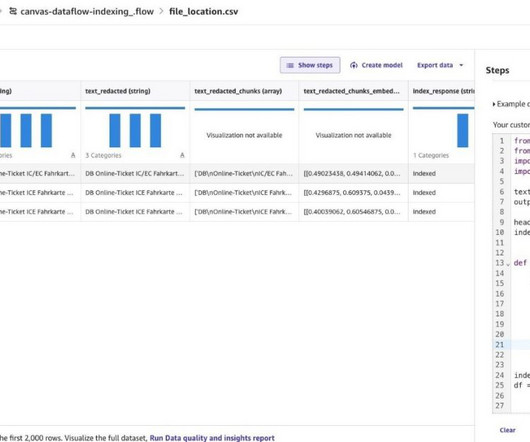
Generative artificialintelligence ( generative AI ) models have demonstrated impressive capabilities in generating high-quality text, images, and other content. However, these models require massive amounts of clean, structured training data to reach their full potential. read HTML).
Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. Marc van Oudheusden is a Senior Data Scientist with the Amazon ML Solutions Lab team at Amazon Web Services. He works with AWS customers to solve business problems with artificialintelligence and machine learning.
During training, the input data is intentionally corrupted by adding noise, while the target remains the original, uncorrupted data. The autoencoder learns to reconstruct the cleandata from the noisy input, making it useful for image denoising and data preprocessing tasks. And that’s exactly what I do.
And those who practice these “old school” governance methods have little confidence in their efficacy: 73% of Ventana research participants stated that spreadsheets were a data governance concern for their organization, while 59% viewed incompatible tools as the top barrier to a single source of truth. And it’s growing in popularity.
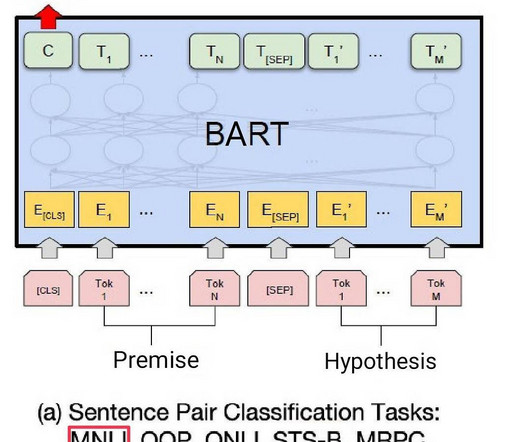
Advances in neural information processing systems 32 (2019). Visualizing data using t-SNE.” She works with strategic AWS customers to explore and apply artificialintelligence and machine learning to discover new insights and solve complex problems. “The Illustrated Transformer.” When does label smoothing help?
MACHINE LEARNING | ARTIFICIALINTELLIGENCE | PROGRAMMING T2E (stands for text to exam) is a vocabulary exam generator based on the context of where that word is being used in the sentence. In this article, I will take you through what it’s like coding your own AI for the first time at the age of 16. Are you ready to explore?
Customers must acquire large amounts of data and prepare it. This typically involves a lot of manual work cleaningdata, removing duplicates, enriching and transforming it. It’s also not easy to run these models cost-effectively.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content