
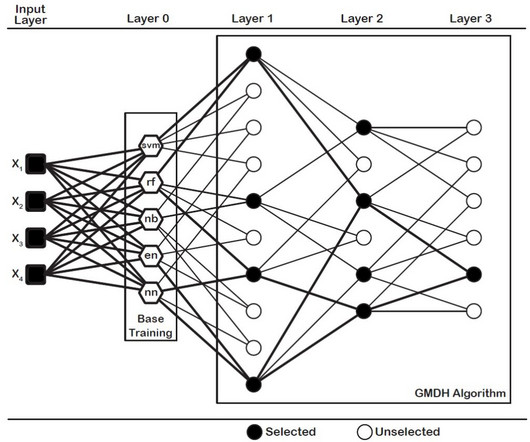
Binary Classification via dce-GMDH Algorithm in R
Universe of Data Science
MARCH 12, 2023
Binary Classification via dce-GMDH Algorithm in R Subscribe to YouTube Channel Don’t forget to check: 6 Ways of Subsetting Data in R References Dag, O., For reproducibility of results, let’s fix the seed number to 1234. dce-GMDH algorithm is available in GMDH2 package (Dag et al., Karabulut, E.,















Let's personalize your content