This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Spotify Million Playlist Released for RecSys 2018, this dataset helps analyze short-term and sequential listening behavior. Yelp Open Dataset Contains 8.6M reviews, but coverage is sparse and city-specific. Valuable for local business research, yet not optimal for large-scale generalizable models.
BI Dashboards Everywhere After 2018, a new shift happened. Tools like Tableau and Power BI do data analysis by just clicking, and they offer amazing visualizations at once, called dashboards. Nate Rosidi is a datascientist and in product strategy. Now the complex tasks could be done in minutes. This was the new standard.
They are essential for processing large amounts of data efficiently, particularly in deep learning applications. What are Tensor Processing Units (TPUs)? History of Tensor Processing Units The inception of TPUs can be traced back to 2015 when Google developed them for internal machine learning projects.
GenAI I serve as the Principal DataScientist at a prominent healthcare firm, where I lead a small team dedicated to addressing patient needs. Over the past 11 years in the field of data science, I’ve witnessed significant transformations. In 2023, we witnessed the substantial transformation of AI, marking it as the ‘year of AI.’
The data set only helps it if it’s well-trained and supervised. A Mongolian pharmaceutical company engaged in a pilot study in 2018 to detect fake drugs, an initiative with the potential to save hundreds of thousands of lives. Experts train AI specifically on how to fight counterfeit products.
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for naturallanguageprocessing (NLP) tasks. BERT can be fine-tuned for a variety of NLP tasks, including question answering, naturallanguage inference, and sentiment analysis.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses naturallanguageprocessing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
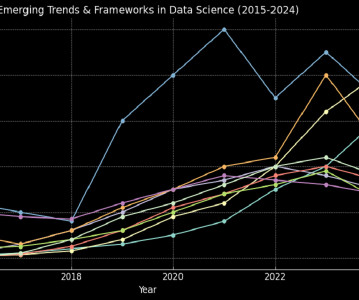
The Early Years: Laying the Foundations (20152017) In the early years, data science conferences predominantly focused on foundational topics like data analytics , visualization , and the rise of big data. The Deep Learning Boom (20182019) Between 2018 and 2019, deep learning dominated the conference landscape.
While this requires technology – AI, machine learning, log parsing, naturallanguageprocessing,metadata management, this technology must be surfaced in a form accessible to business users – the data catalog. The Forrester Wave : Machine Learning Data Catalogs, Q2 2018.
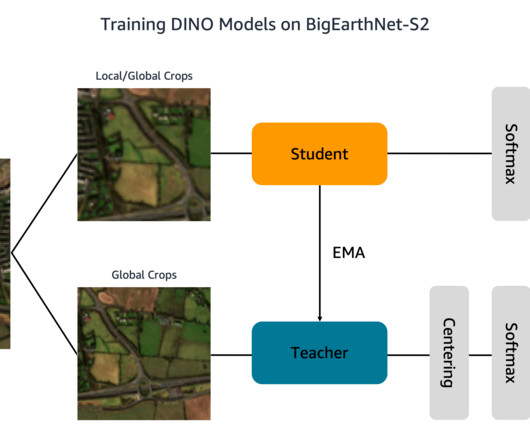
The images document the land cover, or physical surface features, of ten European countries between June 2017 and May 2018. Jeremy Anderson is a Director & DataScientist at Travelers on the AI & Automation Accelerator team. His specialty is NaturalLanguageProcessing (NLP) and is passionate about deep learning.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and naturallanguageprocessing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervised learning. This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately?
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Our datascientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. Business requirements We are the US squad of the Sportradar AI department.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. Haibo Ding is a senior applied scientist at Amazon Machine Learning Solutions Lab. He is broadly interested in Deep Learning and NaturalLanguageProcessing.
AWS received about 100 samples of labeled data from the customer, which is a lot less than the 1,000 samples recommended for fine-tuning an LLM in the data science community. Improving Language Understanding by Generative Pre-Training” Devlin et al., Safa Tinaztepe is a full-stack datascientist with AWS Professional Services.
Imagine an AI system that becomes proficient in many tasks through extensive training on each specific problem and a higher-order learning process that distills valuable insights from previous learning endeavors. NaturalLanguageProcessing: With Meta-Learning, language models can be generalized across various languages and dialects.
About the Authors Maira Ladeira Tanke is a Senior Generative AI DataScientist at AWS. Her work spans speech recognition, naturallanguageprocessing, and large language models. Andrew Gordon Wilson before joining Amazon in 2018.
But now, a computer can be taught to comprehend and process human language through NaturalLanguageProcessing (NLP), which was implemented, to make computers capable of understanding spoken and written language. We’re committed to supporting and inspiring developers and engineers from all walks of life.
About the Authors Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. His research interests are in the area of naturallanguageprocessing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
In 2018, we did a piece of research where we tried to estimate the value of AI and machine learning across geographies, across use cases, and across sectors. One is compared to our first survey conducted in 2018, we see more enterprises investing in AI capability. We need datascientists familiar with deep learning frameworks.
from_disk("/path/to/s2v_reddit_2015_md") nlp.add_pipe(s2v) doc = nlp("A sentence about naturallanguageprocessing.") text == "naturallanguageprocessing" freq = doc[3:6]._.s2v_freq While few datascientists would endorse this as best practice, the qualitative evaluation does have important advantages.
of the spaCy NaturalLanguageProcessing library includes a huge number of features, improvements and bug fixes. spaCy is an open-source library for industrial-strength naturallanguageprocessing in Python. Maybe you’re a grad student working on a paper, maybe you’re a datascientist working on a prototype.
Large language models are foundation models (a kind of large neural network) that generate or embed text. The text they generate can be conditioned by giving them a starting point or “prompt,” enabling them to solve useful tasks expressed in naturallanguage or code. However, modern large language models make it even easier.
Large language models are foundation models (a kind of large neural network) that generate or embed text. The text they generate can be conditioned by giving them a starting point or “prompt,” enabling them to solve useful tasks expressed in naturallanguage or code. However, modern large language models make it even easier.
What the plot here on the X-axis is showing is just, from 2018 up to 2022, relative performance from the best system that we had because of a good benchmark like MLPerf and seeing what the improvement was with respect to “Moore’s Law” (because Moore’s law has been slowing now). Now, these are the “fundamental benchmarks.”
What the plot here on the X-axis is showing is just, from 2018 up to 2022, relative performance from the best system that we had because of a good benchmark like MLPerf and seeing what the improvement was with respect to “Moore’s Law” (because Moore’s law has been slowing now). Now, these are the “fundamental benchmarks.”
LinkedIn: https://www.linkedin.com/in/edwin-genego/ Throughout my career since 2018 I have primarily been a Python and Django developer, with a unintentional pivot to AI integrations & engineering in 2022/2023. I'm a datascientist, I'm looking for hard problems to solve.
About the Authors Maira Ladeira Tanke is a Senior Generative AI DataScientist at AWS. Her work spans speech recognition, naturallanguageprocessing, and large language models. Andrew Gordon Wilson before joining Amazon in 2018.
Datascientists and developers can quickly prototype and experiment with various ML use cases, accelerating the development and deployment of ML applications. This fine-tuning process involves providing the model with a dataset specific to the target domain. Domain adaption format You can fine-tune the Meta Llama 3.2
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















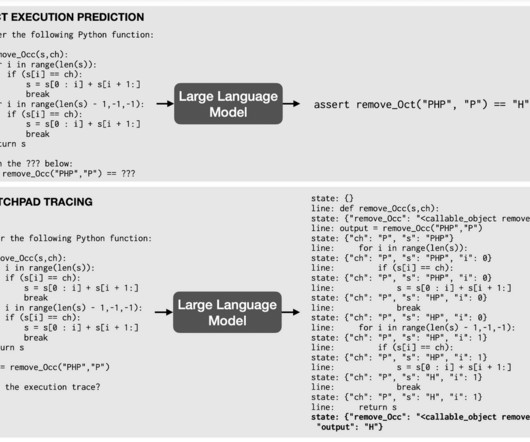
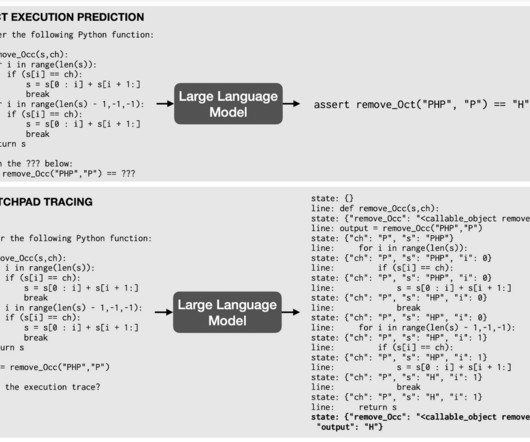








Let's personalize your content