This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Spotify Million Playlist Released for RecSys 2018, this dataset helps analyze short-term and sequential listening behavior. Read the original article at Turing Post , the newsletter for over 90 000 professionals who are serious about AI and ML. Yelp Open Dataset Contains 8.6M reviews, but coverage is sparse and city-specific.
This increases the time it takes for customers to go from data to insights. Our customers want a simple and secure way to find the best applications, integrate the selected applications into their machine learning (ML) and generative AI development environment, manage and scale their AI projects.
This is the first part of an article series based on a whitepaper by Dataiku) The year 2018 was supposed to be the one. The post The most important unanswered questions of 2018 in Artificial Intelligence (AI) and Machine Learning (ML) appeared first on Dataconomy. Let’s find out.
While it is not one of the popular programming languages for datascience, The Go Programming Language (aka Golang) has surfaced for me a few times in the past few years as an option for datascience. I decided to do some searching and find some conclusions about whether golang is a good choice for datascience.
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. By analyzing conference session titles and abstracts from 2018 to 2024, we can trace the rise and fall of key trends that shaped the industry.
AI encompasses the creation of intelligent machines capable of autonomous decision-making, while Predictive Analytics relies on data, statistics, and machine learning to forecast future events accurately. Read more –> DataScience vs AI – What is 2023 demand for? Streamline operations. Improve customer service.
Source Purpose of Using DevSecOps in Traditional and ML Applications The DevSecOps practices are different in traditional and ML applications as each comes with different challenges. The characteristics which we saw for DevSecOps for traditional applications also apply to ML-based applications.
Formerly known as Google Research, it was rebranded during the 2018 Google I/O conference. Datascience services Through Google Cloud, users can access ML infrastructure and datascience capabilities, empowering organizations to leverage AI for their specific needs.
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with Data Integrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machine learning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
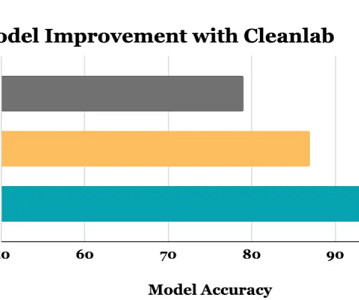
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Everybody knows you need to clean your data to get good ML performance. How does cleanlab work?
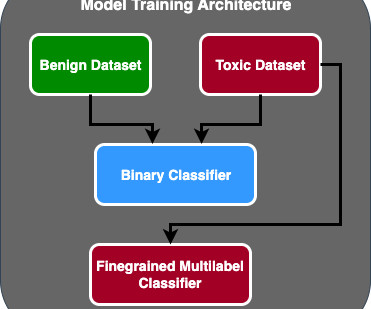
Secondly, to be a successful ML engineer in the real world, you cannot just understand the technology; you must understand the business. Some typical examples are given in the following table, along with some discussion as to whether or not ML would be an appropriate tool for solving the problem: Figure 1.1:
So, if you are eyeing your career in the data domain, this blog will take you through some of the best colleges for DataScience in India. There is a growing demand for employees with digital skills The world is drifting towards data-based decision making In India, a technology analyst can make between ₹ 5.5
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machine learning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
Announced at re:Invent 2018, it puts machine learning in the hands of every developer through the fun and excitement of developing and racing self-driving remote control cars. Idries is the Product Marketing Manager for AWS AI/ML Gamified Learning Programs.
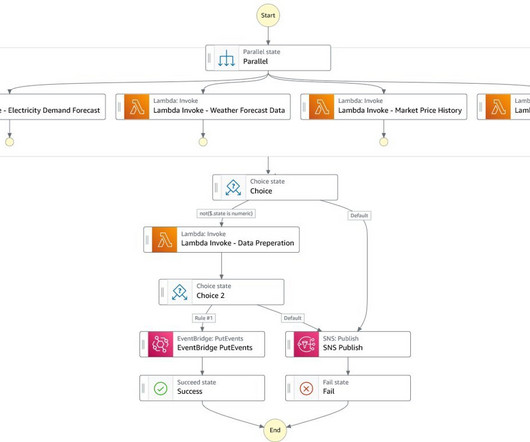
Manager DataScience at Marubeni Power International. MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability.
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
AWS ProServe solved this use case through a joint effort between the Generative AI Innovation Center (GAIIC) and the ProServe ML Delivery Team (MLDT). AWS received about 100 samples of labeled data from the customer, which is a lot less than the 1,000 samples recommended for fine-tuning an LLM in the datascience community.
We are actively working on extending our methods to additional domains, such as computer vision, but be aware that our efficiency improvements do not translate to all ML domains at this time. Graviton Technical Guide is a good resource to consider while evaluating your ML workloads to run on Graviton.
Photo by Andrew Neel on Unsplash Introduction If you are working or have worked on any datascience task then you definitely used pandas. So, pandas is a library which helps with performing data ingestion and transformations. apply(lambda x: x.year) df.groupby('year')['Sales'].mean() Yearly average sales.
While this requires technology – AI, machine learning, log parsing, natural language processing,metadata management, this technology must be surfaced in a form accessible to business users – the data catalog. The Forrester Wave : Machine Learning Data Catalogs, Q2 2018. Subscribe to Alation's Blog.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. Each season consists of around 17,000 plays.
Amazon’s AI Resume Screening In 2018, Amazon abandoned an AI-powered resume screening tool after it was found to be biased against women. If you are curious to know how your AI/ML models in production might be failing under your noses and how to go about fixing them, be sure to catch my session, “ Why do AI Models go Rogue?
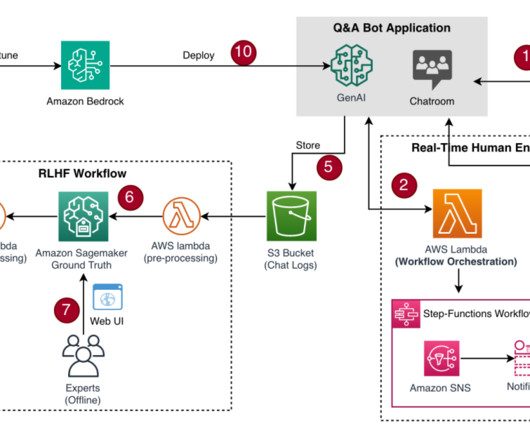
RLHF is a technique that combines rewards and comparisons, with human feedback to pre-train or fine-tune a machine learning (ML) model. Response before RLHF : SageMaker stores code in ML storage volumes Response after RLHF : SageMaker stores code in ML storage volumes, secured by security groups and optionally encrypted at rest.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. It involves training a global machine learning (ML) model from distributed health data held locally at different sites. Import the data loader into the training script.
20 Newsgroups A dataset containing roughly 20,000 newsgroup documents spanning a variety of topics, for text classification, text clustering and similar ML applications. million articles from 20,000 news sources across a seven day period in 2017 and 2018. Long-Form Content 14. The newsgroups are: comp.graphics, comp.os.ms-windows.misc,
If you are a Data Scientist, then your LinkedIn profile should be flooded with information on DataScience’s latest development in this domain, such that it instantly garners the attention of recruiters as well as your contemporaries. In fact, these industries majorly employ Data Scientists.
In this post, we show you how to train the 7-billion-parameter BloomZ model using just a single graphics processing unit (GPU) on Amazon SageMaker , Amazon’s machine learning (ML) platform for preparing, building, training, and deploying high-quality ML models. BloomZ is a general-purpose natural language processing (NLP) model.
By using our mathematical notation, the entire training process of the autoencoder can be written as follows: Figure 2 demonstrates the basic architecture of an autoencoder: Figure 2: Architecture of Autoencoder (inspired by Hubens, “Deep Inside: Autoencoders,” Towards DataScience , 2018 ).
When you’re working on an enterprise scale, managing your ML models can be tricky. YOLOv3 is a newer version of YOLO and was released in 2018. During training, the model is presented with an image with its own real labels and learns to predict the class and position of each object in the image, as well as the corresponding mask.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. He currently is working on Generative AI for data integration. Clay Elmore is an AI/ML Specialist Solutions Architect at AWS. He is the author of the upcoming book “What’s Your Problem?”
photo from DataScience Central Industrial automation, security and surveillance, and service robots are just a few examples of fields that might benefit from robotics’ ability to identify and track objects. A combination of simulated and real-world data was used to train the system, enabling it to generalize to new objects and tasks.
Priorities for Data Cubes evolution Users and developers discussed some of the main trends in the evolution of data cubes and best practices moving forward, such as how to overcome bottlenecks, and key technologies to improve efficiency and accessibility. 2/2) What should be the priority for the data cube evolution? 2018, July).
10Clouds is a software consultancy, development, ML, and design house based in Warsaw, Poland. Deeper Insights has six years of experience in building AI solutions for large enterprise and scale-up clients, a suite of AI models, and data visualization dashboards that enable them to quickly analyze and share insights.
The Continuing Story of Neural Magic Around New Year’s time, I pondered about the upcoming sparsity adoption and its consequences on inference w/r/t ML models. But first… a word from our sponsors: [link] If you enjoy the read, help us out by giving it a ?? and share with friends! The company is Neural Magic.
AI is the next generation of what we called “datascience” a few years back, and datascience represented a merger between statistical modeling and software development. The next most needed skill is operations for AI and ML (54%). That’s not the same as failure, and 2018 significantly predates generative AI.
Text generation using RAG with LLMs enables you to generate domain-specific text outputs by supplying specific external data as part of the context fed to LLMs. JumpStart is a machine learning (ML) hub that can help you accelerate your ML journey. SageMaker Savings Plans apply only to SageMaker ML Instance usage.
The quality of your training data in Machine Learning (ML) can make or break your entire project. Real-Life Examples of Poor Training Data in Machine Learning Amazon’s Hiring Algorithm Disaster In 2018, Amazon made headlines for developing an AI-powered hiring tool to screen job applicants. Sounds great, right?
Adherence to such public health programs is a prevalent challenge, so researchers from Google Research and the Indian Institute of Technology, Madras worked with ARMMAN to design an ML system that alerts healthcare providers about participants at risk of dropping out of the health information program. certainty when used correctly.
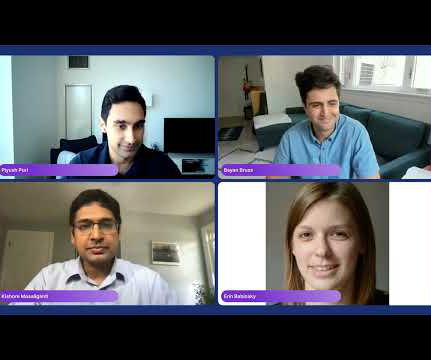
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
I worked on an early conversational AI called Marcel in 2018 when I was at Microsoft. In 2018 when BERT was introduced by Google, I cannot emphasize how much it changed the game within the NLP community. In retrospect, we were slightly ahead of our time because of what came next.
Why We Will Never Open Deep Learning's Black Box || Towards DataScience Brent, M., Explainability and Auditability in ML: Definitions, Techniques, and Tools || Neptune.ai For explainability purposes, you can log the explanations generated by different techniques and associate them with the corresponding model runs.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We’re committed to supporting and inspiring developers and engineers from all walks of life.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content