This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Spotify Million Playlist Released for RecSys 2018, this dataset helps analyze short-term and sequential listening behavior. By, Avi Chawla - highly passionate about approaching and explaining datascience problems with intuition. Yelp Open Dataset Contains 8.6M reviews, but coverage is sparse and city-specific.
Neural Magic is a startup company that focuses on developing technology that enables deeplearning models to run on commodity CPUs rather than specialized hardware like GPUs. The company was founded in 2018 by Alexander Matveev, a former researcher at MIT, and Nir Shavit, a professor of computer science at MIT.
University can be a great way to learndatascience. Luckily, a few of them are willing to share datascience, machine learning and deeplearning materials online for everyone. However, many universities are very expensive, difficult to get admitted, or not geographically feasible.
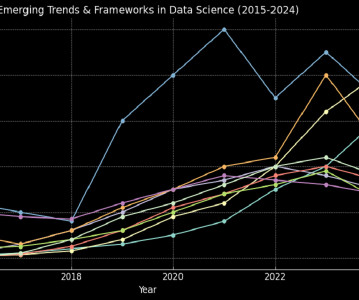
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. By analyzing conference session titles and abstracts from 2018 to 2024, we can trace the rise and fall of key trends that shaped the industry.
Introduction In 2018, when we were contemplating whether AI would take over our jobs or not, OpenAI put us on the edge of believing that. Our way of working has completely changed after the inception of OpenAI’s ChatGPT in 2022. But is it a threat or a boon?
We’ll dive into the core concepts of AI, with a special focus on Machine Learning and DeepLearning, highlighting their essential distinctions. Read more –> DataScience vs AI – What is 2023 demand for? DeepLearning, an AI subset, quickly analyzes vast datasets, delivering results in seconds.
By harnessing machine learning, natural language processing, and deeplearning, Google AI enhances various products and services, making them smarter and more user-friendly. Formerly known as Google Research, it was rebranded during the 2018 Google I/O conference.
In the wake of OpenAI’s announcement of their new o1 model, CDS Professor of Computer Science and DataScience Kyunghyun Cho tweeted, “ Phew, did you say multiple models, inference time adaptive compute, multimodality and language? ” The setting of referential games was an ideal test bed for this complex system.”
Deeplearning And NLP DeepLearning and Natural Language Processing (NLP) are like best friends in the world of computers and language. DeepLearning is when computers use their brains, called neural networks, to learn lots of things from a ton of information. I was developed by OpenAI in 2018.
A visual representation of discriminative AI – Source: Analytics Vidhya Discriminative modeling, often linked with supervised learning, works on categorizing existing data. This breakthrough has profound implications for drug development, as understanding protein structures can aid in designing more effective therapeutics.
Minor changes in the input data that are very apparent to human intelligence are not so for deeplearning models. Deeplearning is essentially matrix multiplication, which means even small perturbations in the coefficients can cause a significant change in the output.
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
Emerging as a key player in deeplearning (2010s) The decade was marked by focusing on deeplearning and navigating the potential of AI. Introduction of cuDNN Library: In 2014, the company launched its cuDNN (CUDA Deep Neural Network) Library. It provided optimized codes for deeplearning models.
GenAI I serve as the Principal Data Scientist at a prominent healthcare firm, where I lead a small team dedicated to addressing patient needs. Over the past 11 years in the field of datascience, I’ve witnessed significant transformations. CS6910/CS7015: DeepLearning Mitesh M. Khapra Homepage www.cse.iitm.ac.in
In this article, we embark on a journey to explore the transformative potential of deeplearning in revolutionizing recommender systems. However, deeplearning has opened new horizons, allowing recommendation engines to unravel intricate patterns, uncover latent preferences, and provide accurate suggestions at scale.
“A lot happens to these interpretability artifacts during training,” said Chen, who believes that by only focusing on the end result, we might be missing out on understanding the entire journey of the model’s learning. The paper is a case study of syntax acquisition in BERT (Bidirectional Encoder Representations from Transformers).
In order to learn the nuances of language and to respond coherently and pertinently, deeplearning algorithms are used along with a large amount of data. A prompt is given to GPT-3 and it produces very accurate human-like text output based on deeplearning. AI chatbot ChatGPT is based on GPT-3.5,
So, if you are eyeing your career in the data domain, this blog will take you through some of the best colleges for DataScience in India. There is a growing demand for employees with digital skills The world is drifting towards data-based decision making In India, a technology analyst can make between ₹ 5.5
By using our mathematical notation, the entire training process of the autoencoder can be written as follows: Figure 2 demonstrates the basic architecture of an autoencoder: Figure 2: Architecture of Autoencoder (inspired by Hubens, “Deep Inside: Autoencoders,” Towards DataScience , 2018 ). That’s not the case.
Large-scale deeplearning has recently produced revolutionary advances in a vast array of fields. is a startup dedicated to the mission of democratizing artificial intelligence technologies through algorithmic and software innovations that fundamentally change the economics of deeplearning. Founded in 2021, ThirdAI Corp.
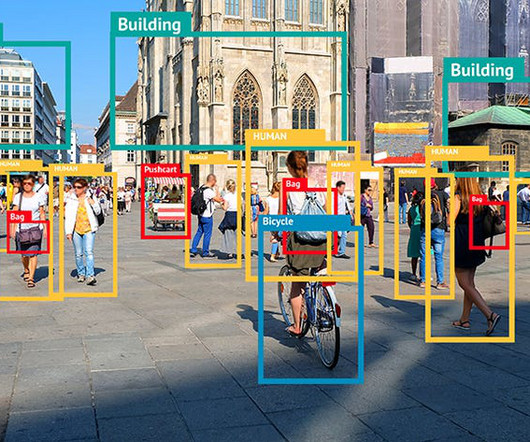
photo from DataScience Central Industrial automation, security and surveillance, and service robots are just a few examples of fields that might benefit from robotics’ ability to identify and track objects. A combination of simulated and real-world data was used to train the system, enabling it to generalize to new objects and tasks.
He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deeplearning on tabular data, and robust analysis of non-parametric space-time clustering. Dr. Huan works on AI and DataScience. He founded StylingAI Inc.,
Previously, he was a senior scientist at Amazon Web Services developing AutoML and DeepLearning algorithms that now power ML applications at hundreds of companies. Originally posted on OpenDataScience.com Read more datascience articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels!
After all, this is what machine learning really is; a series of algorithms rooted in mathematics that can iterate some internal parameters based on data. This is understandable: a report by PwC in 2018 suggested that 30% of UK jobs will be impacted by automation by the 2030s Will Robots Really Steal Our Jobs?
When it comes to deeplearning models, that are often used for more complex problems and sequential data, Long Short-Term Memory (LSTM) networks or Transformers are applied. Discover how our solutions can elevate your media-mix models and boost your organization by making smarter, data-driven decisions. Mahboobi, S.
For instance, two major Machine Learning tasks are Classification, where the goal is to predict a label, and Regression, where the goal is to predict continuous values. REGISTER NOW Building upon the exponential advancements in DeepLearning, Generative AI has attained mastery in Natural Language Processing.
An additional 2018 study found that each SLR takes nearly 1,200 total hours per project. This ongoing process straddles the intersection between evidence-based medicine, datascience, and artificial intelligence (AI). dollars apiece.
Transformer models are a type of deeplearning model that are used for natural language processing (NLP) tasks. They are able to learn long-range dependencies between words in a sentence, which makes them very powerful for tasks such as machine translation, text summarization, and question answering.
Transformer models are a type of deeplearning model that are used for natural language processing (NLP) tasks. They are able to learn long-range dependencies between words in a sentence, which makes them very powerful for tasks such as machine translation, text summarization, and question answering.
LeCun received the 2018 Turing Award (often referred to as the "Nobel Prize of Computing"), together with Yoshua Bengio and Geoffrey Hinton, for their work on deeplearning. Hinton is viewed as a leading figure in the deeplearning community. He co-developed the Lush programming language with Léon Bottou.
YOLOv3 is a newer version of YOLO and was released in 2018. İrem KÖMÜRCÜ Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deeplearning practitioners.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. The library can be installed via pip.
For example, if you are using regularization such as L2 regularization or dropout with your deeplearning model that performs well on your hold-out-cross-validation set, then increasing the model size won’t hurt performance, it will stay the same or improve. In the big data and deeplearning era, now you have much more flexibility.
He focused on generative AI trained on large language models, The strength of the deeplearning era of artificial intelligence has lead to something of a renaissance in corporate R&D in information technology, according to Yann LeCun, chief AI. Hinton is viewed as a leading figure in the deeplearning community.
For example, explainability is crucial if a healthcare professional uses a deeplearning model for medical diagnoses. Captum allows users to explain both deeplearning and traditional machine learning models. Explainability in Machine Learning || Seldon Blazek, P. References Castillo, D. Russell, C. &
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks.
Using DeepLearning Models to Detect Abusive Behavior in Video Games Abusive behaviors are a pervasive issue in numerous business settings, including credit card companies, video games, and promotional events. To address such abusive behaviors, there exist various deeplearning models that can effectively mitigate this problem.
For example, supporting equitable student persistence in computing research through our Computer Science Research Mentorship Program , where Googlers have mentored over one thousand students since 2018 — 86% of whom identify as part of a historically marginalized group.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. Haibo Ding is a senior applied scientist at Amazon Machine Learning Solutions Lab. He is broadly interested in DeepLearning and Natural Language Processing.
We call the data loader function for eICU data with the following code: elif dataset_name == "eicu": logging.info("load_data. FedML supports several out-of-the-box deeplearning algorithms for various data types, such as tabular, text, image, graphs, and Internet of Things (IoT) data. Scientific data 5.1
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). He focuses on developing scalable machine learning algorithms.
Everything You Need to Know About Few-Shot Learning || Paperspace Blog Model-Agnostic Meta-Learning (MAML) Made Simple || InstaDeep Nichol, A. & 2018) Reptile: A scalable meta-learning algorithm || OpenAI.com Xavier L. & Schulman, J. We pay our contributors, and we don't sell ads.
Natural language processing and machine learning as practical toolsets for archival processing. Natural language processing and machine learning for law and policy texts. Records Management Journal , 30 (2), 155–174. Law and word order: NLP in legal tech. Natural Language Engineering , 25 (1), 211–217.
According to fortunly , the demand for Blockchain has risen in recent years as we have obviously seen in the Crypto bull runs of 2018 and 2020. R – The king of statistical analysis R is a very popular programming language for DataScience, mainly focused on statistical analysis.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























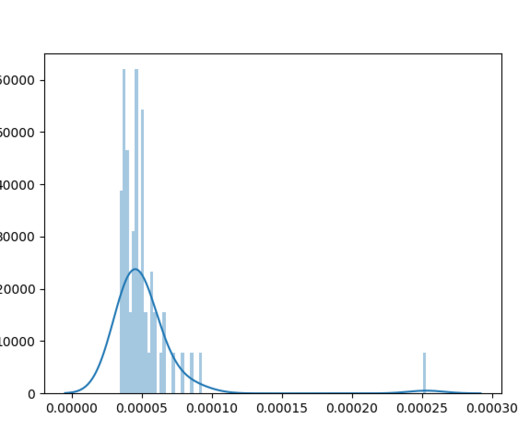



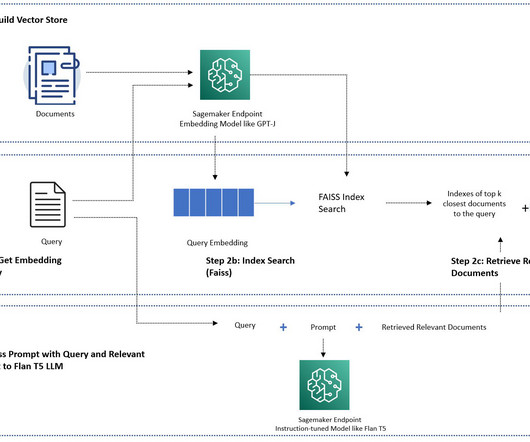









Let's personalize your content