This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While it is not one of the popular programming languages for datascience, The Go Programming Language (aka Golang) has surfaced for me a few times in the past few years as an option for datascience. I decided to do some searching and find some conclusions about whether golang is a good choice for datascience.
Just like people, Algorithmic biases can occur sometimes. AI algorithms are used to make decisions about everything from who gets a loan to what ads we see online. However, AI algorithms can be biased, which can have a negative impact on people’s lives. Thinking why? Well, think of AI as making those characters.
How did you get started in datascience? Like many data scientists in the 2010s, I stumbled my way into the field. Afterward, I worked as research assistant at the Fiscal Research Center - a research group at GSU - on a project measuring income mobility in Georgia using government administrative data.
Looking for a few academic datascience papers to study? Here are a few I have found interesting. The are not all from the past 12 months, but I am including them anyhow.
Are you looking to get a job in big data? The Bureau of Labor Statistics reports that there were over 31,000 people working in this field back in 2018. However, it is not easy to get a career in big data. This has led to a number of great opportunities for data scientists to offer their services to gaming companies.
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. By analyzing conference session titles and abstracts from 2018 to 2024, we can trace the rise and fall of key trends that shaped the industry.
Formerly known as Google Research, it was rebranded during the 2018 Google I/O conference. Focus areas of Google AI Google AI directs its efforts towards several key research areas, continually pushing the boundaries of what AI can achieve: Machine learning: Developing algorithms that enable computers to learn from data.
In the wake of OpenAI’s announcement of their new o1 model, CDS Professor of Computer Science and DataScience Kyunghyun Cho tweeted, “ Phew, did you say multiple models, inference time adaptive compute, multimodality and language? ” By tracing these connections, we gain insight into the collaborative nature of AI progress.
AI encompasses the creation of intelligent machines capable of autonomous decision-making, while Predictive Analytics relies on data, statistics, and machine learning to forecast future events accurately. Read more –> DataScience vs AI – What is 2023 demand for? Goals To predict future events and trends.
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world.
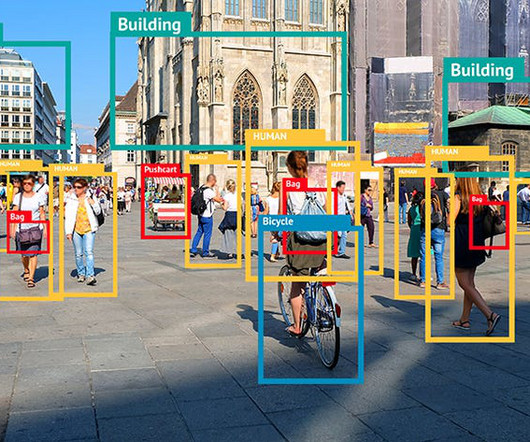
How do Object Detection Algorithms Work? There are two main categories of object detection algorithms. Two-Stage Algorithms: Two-stage object detection algorithms consist of two different stages. Single-stage object detection algorithms do the whole process through a single neural network model.
Louis will join the CDS community with an extensive background in datascience applications within the financial industry and a strong commitment to educational mentorship. “As I can’t think of a better place to do this than NYU Center for DataScience.”
A number of new predictive analytics algorithms are making it easier to forecast price movements in the cryptocurrency market. The researchers analyzed daily market data from nearly 1,700 cryptocurrencies that were sold between November 2015 and April 2018. The accuracy of these machine learning algorithms is also important.
GenAI I serve as the Principal Data Scientist at a prominent healthcare firm, where I lead a small team dedicated to addressing patient needs. Over the past 11 years in the field of datascience, I’ve witnessed significant transformations. Expand your skillset by… courses.analyticsvidhya.com 2.
So, if you are eyeing your career in the data domain, this blog will take you through some of the best colleges for DataScience in India. There is a growing demand for employees with digital skills The world is drifting towards data-based decision making In India, a technology analyst can make between ₹ 5.5
Furthermore, data enrichment can help ensure that AI algorithms are trained on diverse data, reducing the risk of bias. Adding datasets for underrepresented groups can help ensure that AI algorithms are not perpetuating any preexisting biases. Tendü received her Ph.D. Tendü received her Ph.D.
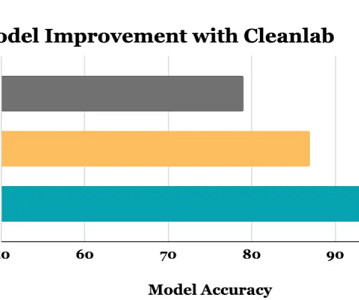
Cleanlab is an open-source software library that helps make this process more efficient (via novel algorithms that automatically detect certain issues in data) and systematic (with better coverage to detect different types of issues). You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
After all, this is what machine learning really is; a series of algorithms rooted in mathematics that can iterate some internal parameters based on data. This is understandable: a report by PwC in 2018 suggested that 30% of UK jobs will be impacted by automation by the 2030s Will Robots Really Steal Our Jobs?
The data set only helps it if it’s well-trained and supervised. A Mongolian pharmaceutical company engaged in a pilot study in 2018 to detect fake drugs, an initiative with the potential to save hundreds of thousands of lives. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
In order to learn the nuances of language and to respond coherently and pertinently, deep learning algorithms are used along with a large amount of data. The BERT algorithm has been trained on 3.3 A Google AI language model called Bidirectional Encoder Representations from Transformers (BERT) was introduced in 2018.
By incorporating computer vision methods and algorithms into robots, they are able to view and understand their environment. photo from DataScience Central Industrial automation, security and surveillance, and service robots are just a few examples of fields that might benefit from robotics’ ability to identify and track objects.
Algorithmic Attribution using binary Classifier and (causal) Machine Learning While customer journey data often suffices for evaluating channel contributions and strategy formulation, it may not always be comprehensive enough. 0278937 The post Data-driven Attribution Modeling appeared first on DataScience Blog.
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. Dr. Huan works on AI and DataScience. From 2015–2018, he worked as a program director at the US NSF in charge of its big data program.
Predictive analytics: Predictive analytics leverages historical data and statistical algorithms to make predictions about future events or trends. Machine learning and AI analytics: Machine learning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
is a startup dedicated to the mission of democratizing artificial intelligence technologies through algorithmic and software innovations that fundamentally change the economics of deep learning. Vihan is also a recipient of a National Science Foundation research fellowship. Founded in 2021, ThirdAI Corp.
An additional 2018 study found that each SLR takes nearly 1,200 total hours per project. This ongoing process straddles the intersection between evidence-based medicine, datascience, and artificial intelligence (AI). dollars apiece.
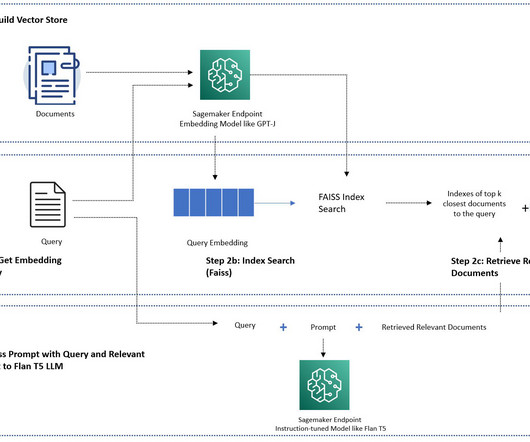
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). If you have a large dataset, the SageMaker KNN algorithm may provide you with an effective semantic search.
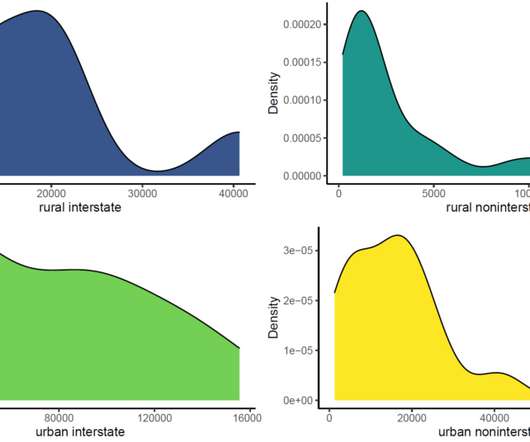
library(AID) data(AADT) Before we go ahead, let’s obtain descriptive statistics for each group with describe() function available in onewaytests (Dag et al., library(onewaytests) describe(aadt ~ class, data = AADT) ## n Mean Std.Dev Median Min Max 25th 75th Skewness Kurtosis NA ## rural interstate 8 18593.125 10384.748 17688.0
Using historical data from the 2018–2023 Mexico Grand Prix and race data from the 2024 season, participants will analyze variables such as lap times, stint numbers, tire compounds, and pit stop timing. Click here to access the challenge and become part of our datascience community.
Artificial Intelligence has made significant strides since its inception, evolving from simple algorithms to highly advanced Neural Networks capable of performing sophisticated tasks such as generating completely new content, including images, audio, and video. Interested in attending an ODSC event?
github.com Their core repos consist of SparseML: a toolkit that includes APIs, CLIs, scripts and libraries that apply optimization algorithms such as pruning and quantization to any neural network. Neural Magic Neural Magic has 6 repositories available. Follow their code on GitHub. SparseZoo: a model repo for sparse models. Connected Papers
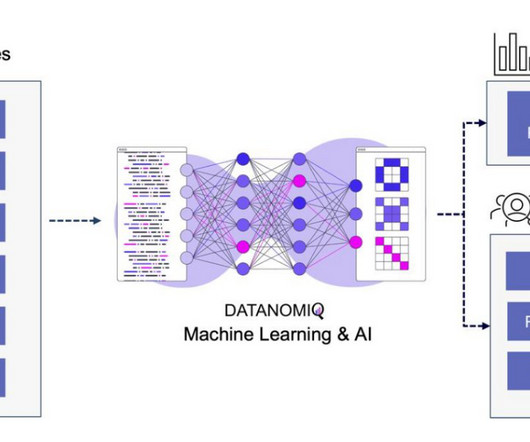
By using our mathematical notation, the entire training process of the autoencoder can be written as follows: Figure 2 demonstrates the basic architecture of an autoencoder: Figure 2: Architecture of Autoencoder (inspired by Hubens, “Deep Inside: Autoencoders,” Towards DataScience , 2018 ).
After 116 years in business, legendary guitar maker Gibson filed for bankruptcy in 2018. A commitment to using data to become a customer-first organization rather than a self-described “developer-led community.”. Collaborating together, they were able to align interests and algorithms to generate a breakthrough data product.
Manager DataScience at Marubeni Power International. SageMaker enables Marubeni to run ML and numerical optimization algorithms in a single environment. Manager DataScience at Marubeni Power International. His team applies datascience and digital technologies to support Marubeni Power growth strategies.
Video Presentation of the B3 Project’s Data Cube. Presenters and participants had the opportunity to hear about and evaluate the pros and cons of different back end technologies and data formats for different uses such as web-mapping, data visualization, and the sharing of meta-data. 2018, July). Giuliani, G.,
The quality of your training data in Machine Learning (ML) can make or break your entire project. This article explores real-world cases where poor-quality data led to model failures, and what we can learn from these experiences. By the end, you’ll see why investing in quality data is not just a good idea, but a necessity.
Example 1: Tabular Data Interpretation Consider the following table showing the number of trees planted by a government over six years: Question : What is the average number of trees planted per year from 2018 to 2023? How Do I Handle Missing Data During Interpretation?
A:It was 2018 when WiBD Munich started. I participated in the very first meeting because I was just starting out with datascience and pursuing a nanodegree on the topic. A:One of the biggest challenges was getting past the HR algorithms to get interviews.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. We design an algorithm that automatically identifies the ambiguity between these two classes as the overlapping region of the clusters. Each season consists of around 17,000 plays.
Together with data stores, foundation models make it possible to create and customize generative AI tools for organizations across industries that are looking to optimize customer care, marketing, HR (including talent acquisition) , and IT functions. An open-source model, Google created BERT in 2018.
Consider a scenario where legal practitioners are armed with clever algorithms capable of analyzing, comprehending, and extracting key insights from massive collections of legal papers. Algorithms can automatically detect and extract key items. But what if there was a technique to quickly and accurately solve this language puzzle?
At its core, Meta-Learning equips algorithms with the aptitude to quickly grasp new tasks and domains based on past experiences, paving the way for unparalleled problem-solving skills and generalization abilities. Reptile is a meta-learning algorithm that falls under model-agnostic meta-learning approaches.
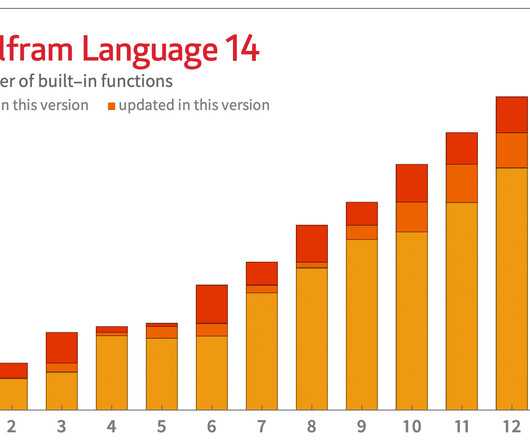
Sometimes it’s a story of creating a superalgorithm that encapsulates decades of algorithmic development. Sometimes it’s a story of painstakingly curating data that’s never been assembled before. Talking of speedups, another example—made possible by new algorithms operating on multithreaded CPUs—concerns polynomials.
By leveraging the power of neural networks, deep learning techniques breathe new life into recommendation algorithms, empowering them to handle complex data and surpass the limitations of their predecessors. Netflix’s movies and TV shows are recommended based on user ratings, viewing history, and platform interactions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content