
Evaluating Long-Context Question & Answer Systems
Eugene Yan
JUNE 21, 2025
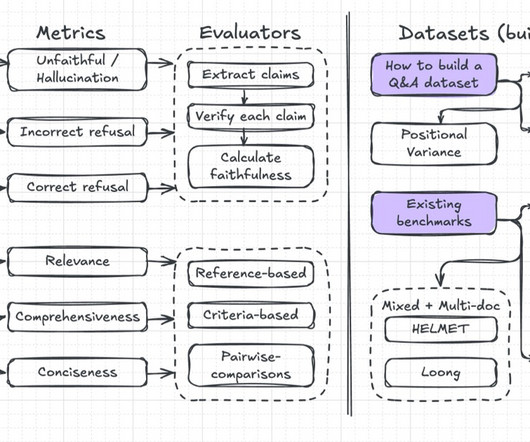
in 2017 , is designed to test genuine narrative comprehension rather than surface-level pattern matching. 2025) , addresses issues in earlier benchmarks, such as unrealistic tasks and inconsistent metrics, providing a framework for evaluating long-context language models. The NarrativeQA dataset , introduced by Kočiský et al.












Let's personalize your content