This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Katharine Jarmul and Data Natives are joining forces to give you an amazing chance to delve deeply into Python and how to apply it to data manipulation, and data wrangling. By the end of her workshop, Learn Python for Data Analysis, you will feel comfortable importing and running simple Python analysis on your.
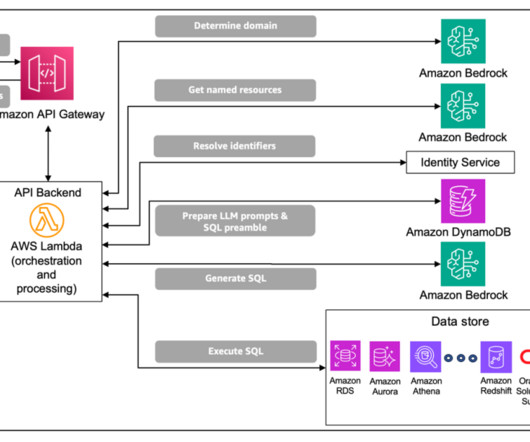
The API is linked to an AWS Lambda function, which implements and orchestrates the processing steps described earlier using a programming language of the users choice (such as Python) in a serverless manner. He has over a decade of cross-industry expertise leading strategic initiatives and masters degrees in AI and DataScience.
As newer fields emerge within datascience and the research is still hard to grasp, sometimes it’s best to talk to the experts and pioneers of the field. His research interests bridge the computational, statistical, cognitive, biological, and social sciences. Recently, we spoke with Michael I.
The change of direction in the data for a sustained period can be called a trend. To demonstrate the trend, we will use Pollution US 2000 to 2016data from Kaggle. It will be clearer with the examples below. Please feel free to download the dataset from this link: U.S. csv') This dataset is pritty big.
It 10x’s our world-class AI platform by dramatically increasing the flexibility of DataRobot for data scientists who love to code and share their expertise across teams of all skill levels. At DataRobot, we have always known that datascience is a team sport. Customize and automate your datascience workflows.
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for datascience, machine learning (ML), and computational science. Given the importance of Jupyter to data scientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
We use DSPy (Declarative Self-improving Python) to demonstrate the workflow of Retrieval Augmented Generation (RAG) optimization, LLM fine-tuning and evaluation, and human preference alignment for performance improvement. Complete the following steps: Load the dataset for evaluation in the Example data type.
You can use the below resources for creating your data. ★ Kaggle image datasets: Link Users of Kaggle may discover and share data sets, study and develop models in a web-based datascience environment, and collaborate with other data scientists and computer vision experts.
python inference.py --input_path test_data --sequence_column name_of_the_column input_type Drug --relation_name smiles --model_path ibm/otter_dude_distmult --output_path output_path Benchmarks Training benchmark models We assume that you have used the inference script to generate embeddings for training and test proteins/drugs. Hercules, M.
If you are a Data Scientist, then your LinkedIn profile should be flooded with information on DataScience’s latest development in this domain, such that it instantly garners the attention of recruiters as well as your contemporaries. Expansive Hiring The IT and service sector is actively hiring Data Scientists.
IBM Watson Studio has come a long way since I first tested IBM DataScience Experience in November 2016. The new Watson Studio delivers a more collaborative, enterprise quality data. by Jen Underwood. Read More.
It can also be used in a variety of languages, such as Python, C++, JavaScript, and Java. The basic data structure for TensorFlow are tensors. What is PyTorch PyTorch is an open-source deep learning framework developed by Facebook and released in 2016.
Photo by Andrew Neel on Unsplash Introduction If you are working or have worked on any datascience task then you definitely used pandas. So, pandas is a library which helps with performing data ingestion and transformations. apply(lambda x: x.year) df.groupby('year')['Sales'].mean() Yearly average sales.
Their platform was developed for working with Spark and provides automated cluster management and Python-style notebooks. Scale AI Founded in 2016, Scale AI has one simple goal, and that’s to accelerate the development of AI applications and provide end-to-end data-centric solutions that manage the entire machine learning life cycle.
Jan 22: Ines was invited as a guest to the TalkPython podcast and discussed how to build a datascience startup. Mar 29: Ines joined the at the German Python Podcast to talk about Natural Language Processing with spaCy. ? Since founding Explosion in 2016, we’ve run the company as a profitable business. September ?
Image generated with Midjourney In today’s fast-paced world of datascience, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
The “Fourth Industrial Revolution” was coined by Klaus Schwab of the World Economic Forum in 2016. Python is unarguably the most broadly used programming language throughout the datascience community. Native Python Support for Snowpark. Deploying a Model and Consuming the Inferences.
With the emergence of datascience and AI, clustering has allowed us to view data sets that are not easily detectable by the human eye. Thus, this type of task is very important for exploratory data analysis. 1207–1221, May 2016, doi: 10.1109/JSAC.2016.2545384. 4, center_box=(20, 5)) model = OPTICS().fit(x)
The demand for data analysts in India is expected to reach 1.5 lakhs by the end of 2021, up from 70,000 in 2016, as per a report by Great Learning, an ed-tech platform. The average Data Analyst salary in India is Rs. How to Become a Data Analyst with No Experience? lakhs per annum, according to Glassdoor.
Abstract Polars is a fast-growing open-source data frame library that is rapidly becoming the preferred choice for data scientists and data engineers in Python. It is available in multiple languages: Python, Rust, and NodeJS. Comparison of data frame libraries (Image by Author) Why use Polars?
A good understanding of Python and machine learning concepts is recommended to fully leverage TensorFlow's capabilities. Further Reading TensorFlow Documentation TensorFlow Tutorials PyTorch PyTorch, developed by Facebook's AI Research Lab (FAIR) , was released in 2016. It is well-suited for both research and production environments.
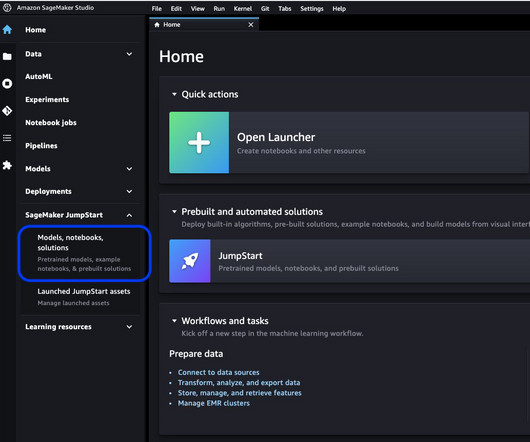
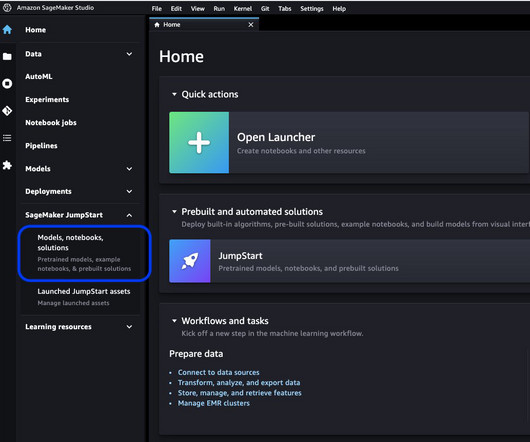
Solution overview In the following sections, we provide a step-by-step demonstration for fine-tuning an LLM for text generation tasks via both the JumpStart Studio UI and Python SDK. The Companys net income attributable to the Company for the year ended December 31, 2016 was $4,816,000, or $0.28
First released in 2016, it quickly gained traction due to its intuitive design and robust capabilities. Discover its dynamic computational graphs, ease of debugging, strong community support, and seamless integration with popular Python libraries for enhanced development.
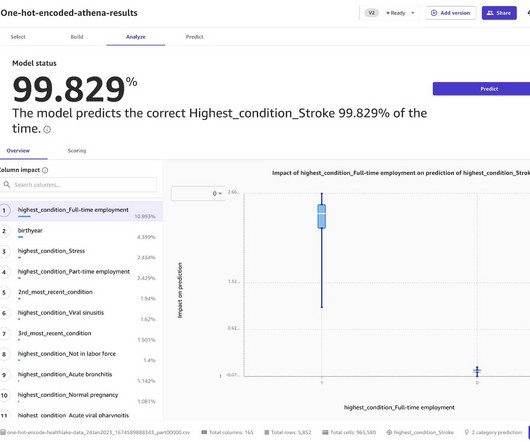
However, organizations and users in industries where there is potential health data, such as in healthcare or in health insurance, must prioritize protecting the privacy of people and comply with regulations. They are also facing challenges in using ML-driven analytics for an increasing number of use cases.
Here's an example of calculating feature importance using permutation importance with scikit-learn in Python: from sklearn.inspection import permutation_importance # Fit your model (e.g., Alibi Alibi is an open-source Python library for algorithmic transparency and interpretability. References Castillo, D. Russell, C. &
Solution overview In the following sections, we provide a step-by-step demonstration for fine-tuning an LLM for text generation tasks via both the JumpStart Studio UI and Python SDK. The Companys net income attributable to the Company for the year ended December 31, 2016 was $4,816,000, or $0.28
This API is how we'll work with the model from Python code. In many datascience projects, including this one, we more often care about the model's performance on unseen data, that is, data the model hasn't seen/wasn't trained on. 2016; Piamsai, 2017). Which brings us to. In [8]: df. Well, maybe wrong.
A Simple Step-to-Step Guide to Chi-Square Tests in Python Introduction In our last article , we used the t-test. This parametric test assumes that the sample data comes from normally distributed populations. Implementing Chi-Square in Python Now, we will calculate the Chi-Square test using the scipy.stats.chi2_contingency function.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content